Put in a ride for tomorrow!

SBIRs
- Finish up MORS slides
- Create a single-level hierarchy that moves a target in 3D space and set up the visualizer to track through the data dictionary
GPT Agents
- Clustering

Put in a ride for tomorrow!
SBIRs
GPT Agents
SBIRs
GPT Agents
Book
Train station at noon!
Git Re-Basin: Merging Models modulo Permutation Symmetries

SBIRs
GPT Agents
SBIRs
Book
GPT Agents


SBIRs
GPT Agents


Book
Call powerwasher! Dave Tobias 410 271-8795 – done
The antibiotics seem to be working on the bronchitis… slowly
Book
SBIRs
GPT Agents
TOLKIEN’S ILLUSTRATORS: SERGEY YUKHIMOV

SBIRs
GPT Agents
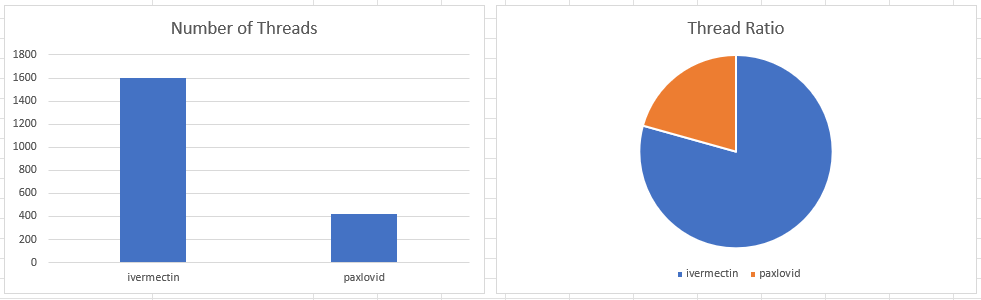
Yay! Got a prescription!
My guess is that Trump made a deal with the Saudis for nuclear information on Israel and Iran
Book
SBIRs
GPT Agents
Set up a monthly contribution to the UNHCR
Book
GPT Agents
SBIRs

Book
SBIRs

GPT Agents

Heavenbanning is real in the world: We flooded our dating app with bots…to scam scammers
Book
SBIRs
GPT Agents
Back from more travels! It’s good to be home
SBIRs
GPT Agents
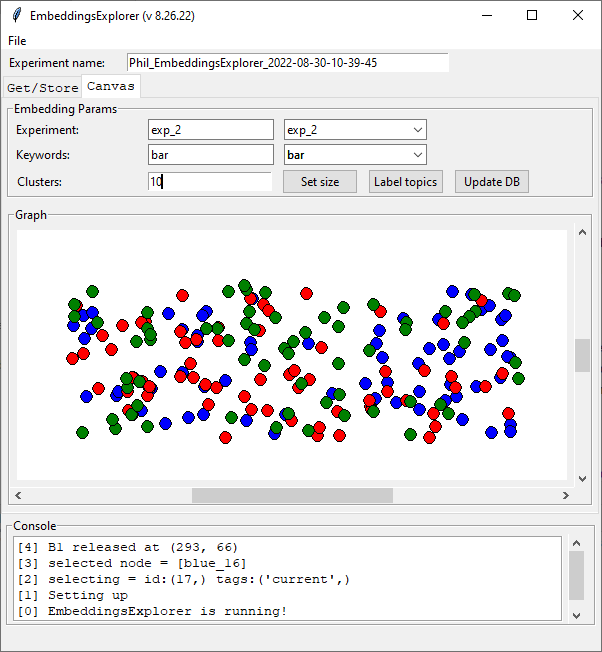
Book
Umberto Eco: A Practical List for Identifying Fascists
Multi Dimensional and Domain Operations (MDDO)
SBIRs
Book
GPT Agents

SBIRs
Book
from tkinter import filedialog
import PyPDF2
import re
from typing import List, Dict
filename = filedialog.askopenfilename(filetypes=(("pdf files", "*.pdf"),), title="Load pdf File")
if filename:
print("opening {}".format(filename))
# open the pdf file
object = PyPDF2.PdfFileReader(filename)
d = {}
# get number of pages
NumPages = object.getNumPages()
print("There are {} pages".format(NumPages))
# extract text and do the search
for i in range(0, NumPages):
PageObj = object.getPage(i)
# print("this is page " + str(i))
Text = PageObj.extractText()
# print(Text)
reml:List = re.findall("\[\d+\]", Text)
if len(reml) > 0:
for r in reml:
if r in d:
d[r] += 1
else:
d[r] = 1
ds = dict(sorted(d.items(), key = lambda x: x[1], reverse=True))
for k, v in ds.items():
print("{} = {}".format(k, v))
GPT-Agents
Book
SBIRs
GPT Agents

{kind=link}
You must be logged in to post a comment.