
7:00 – 4:00 ASRC MKT
- How artificial intelligence is changing science – This page contains pointers to a bunch of interesting projects:
- Multi-view Discriminative Learning via Joint Non-negative Matrix Factorization
- Multi-view learning attempts to generate a classifier with a better performance by exploiting relationship among multiple views. Existing approaches often focus on learning the consistency and/or complementarity among different views. However, not all consistent or complementary information is useful for learning, instead, only class-specific discriminative information is essential. In this paper, we propose a new robust multi-view learning algorithm, called DICS, by exploring the Discriminative and non-discriminative Information existing in Common and view-Specific parts among different views via joint non-negative matrix factorization. The basic idea is to learn a latent common subspace and view-specific subspaces, and more importantly, discriminative and non-discriminative information from all subspaces are further extracted to support a better classification. Empirical extensive experiments on seven real-world data sets have demonstrated the effectiveness of DICS, and show its superiority over many state-of-the-art algorithms.
- Add Nomadic, Flocking, and Stampede to terms. And a bunch more
- Slides
- Embedding navigation
- Extend SmartShape to SourceShape. It should be a stripped down version of FlockingShape
- Extend BaseCA to SourceCA, again, it should be a stripped down version of FlockingBeliefCA
- Add a sourceShapeList for FlockingAgentManager that then passes that to the FlockingShapes
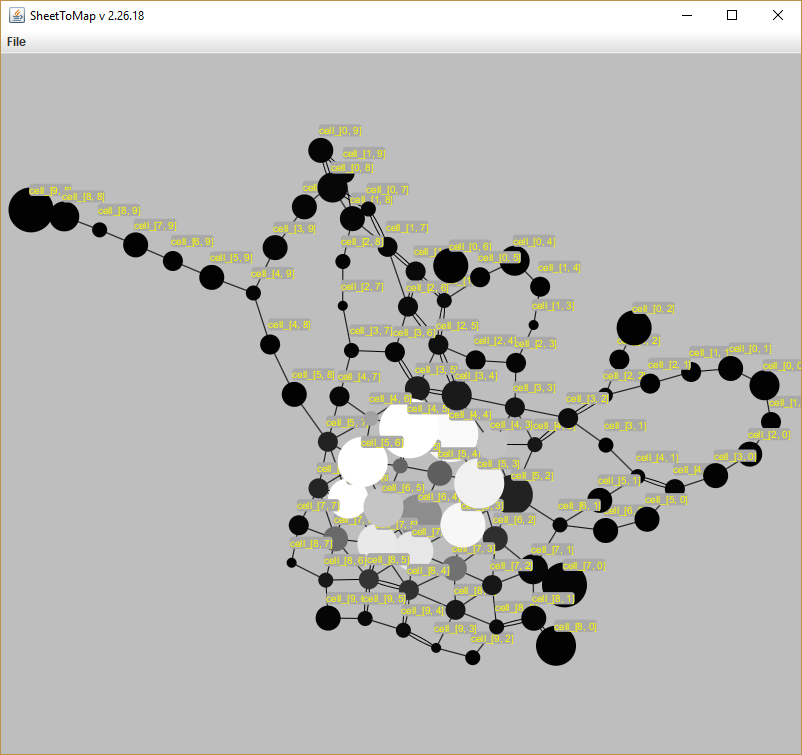
- And it’s working! Well, drawing. Next is the interactions:

- Finally went and joined the IEEE

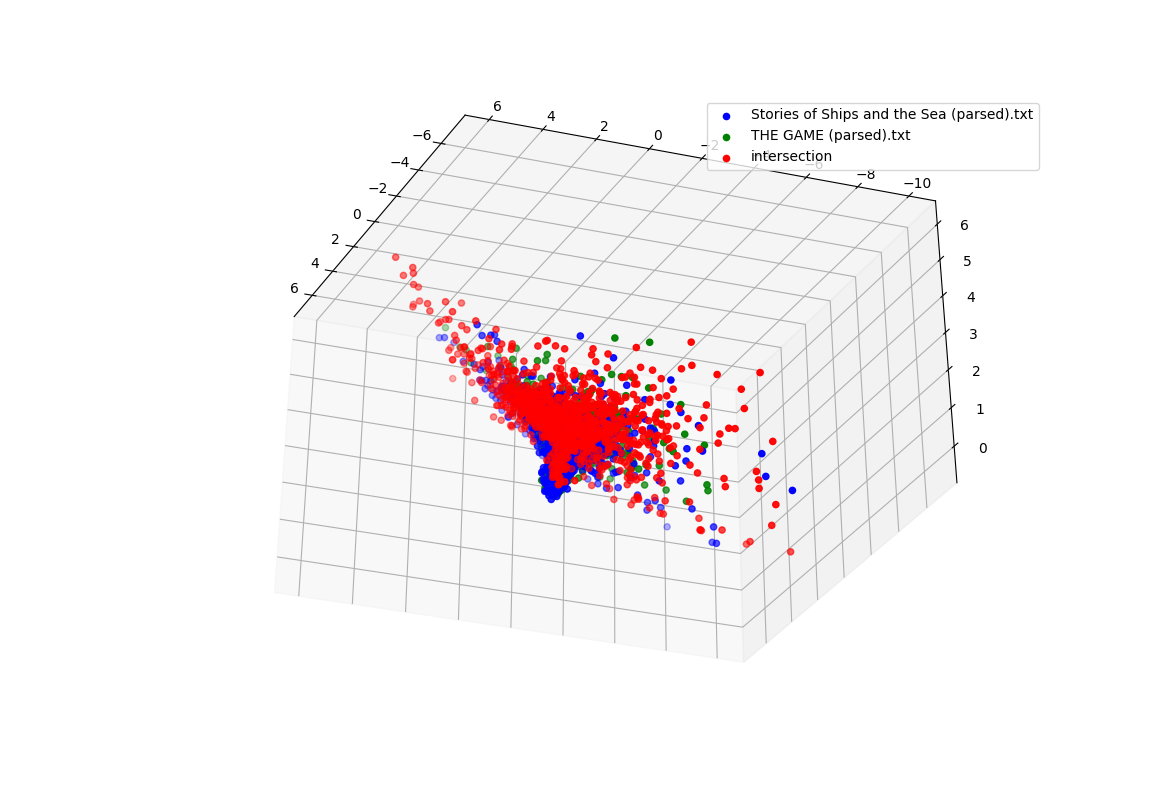
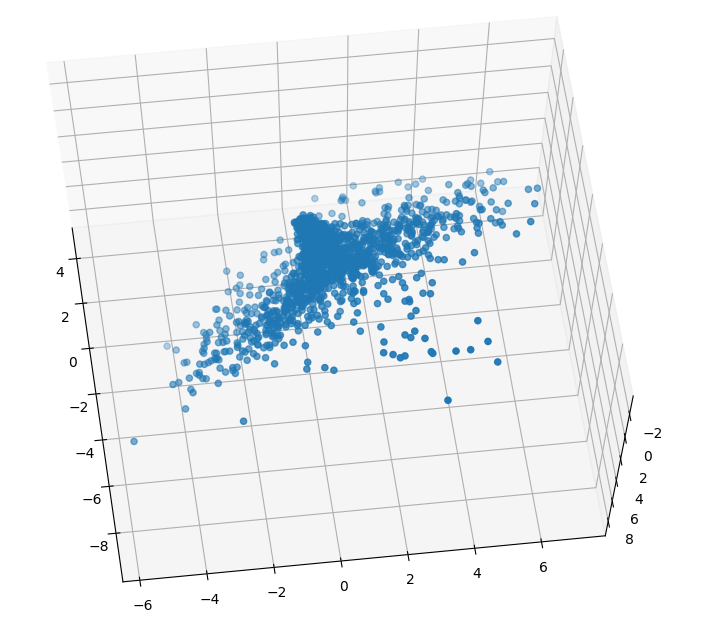


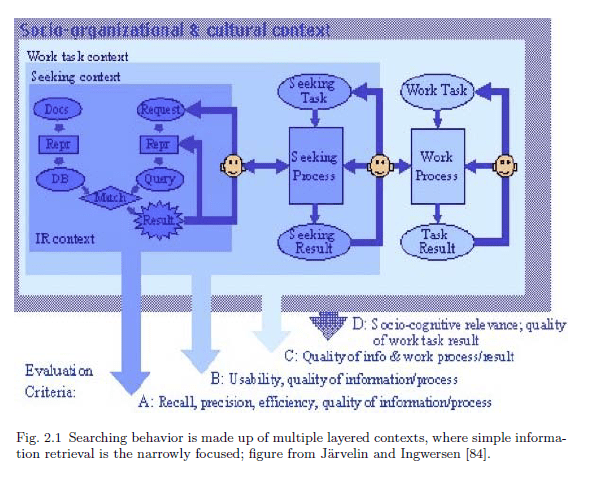
 I think it is reasonable to consider this a measure of alignment
I think it is reasonable to consider this a measure of alignment







You must be logged in to post a comment.