Building the db table/store for the NZ tweets – done. After screwing up the insert arguments, I’m running a 1k set of synthetic tweets to evaluate the test field.
As a J&J recipient, today is booster day! I will become a cocktail of J&J/Moderna antibodies at 10:00. Hopefully my wifi reception will improve dramatically with these new chips.
Leave NLT 9:15
GPT Agents
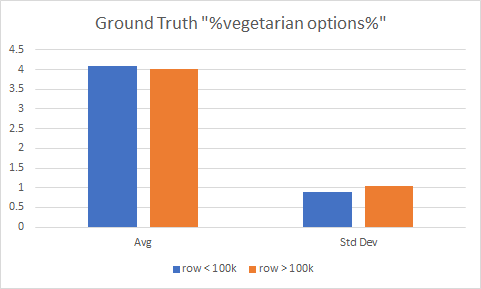
Run some other variations, or show that the usage of “several vegetarian options” is normal speech. The phrase ‘%vegetarian options%’ has 79 reviews in the training set and 4,911 in the holdout set. Going to do a quick boxplot to see if there’s much difference.
Pretty much what I expected – very hard to evaluate any difference:
Probably not a good example
Running ‘some vegetarian options’ and ‘no vegetarian’ on the 100k American model. It turns out that I ran the default ‘review:’ probe yesterday
SBIRs
Getting the separate behavior for the cmdr and sbrd nodes to work. Rather than having them bounce around, I need to have them head to targets at a speed. That means rewriting bits of Moveable node. Done!
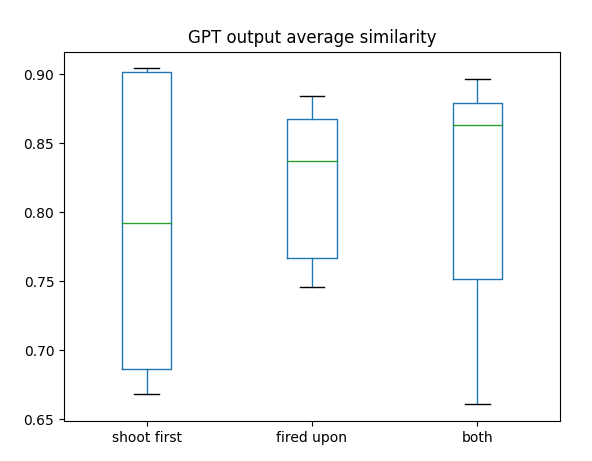
Added a boxplot to the TextSimilarity framework. Might show at the meeting today?
Get the script tied into node display. Having some issues. Thinking about having an animated commander and subordinate node moving across the map
Set enum types for ForceNodes and MoveableNodes. Tomorrow I’ll add cmdr and sbrd nodes and try moving them around. This will need a setup() method in ScriptFrame that adds them as MoveableNodes
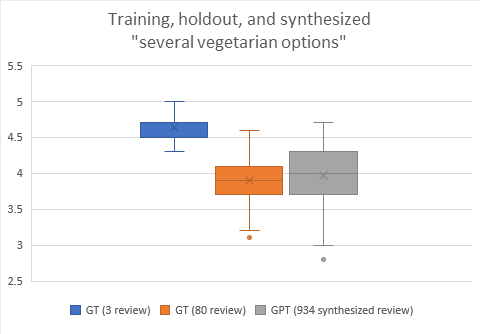
Try to get the query and probe for “%several vegetarian options%” running. This data is used in the “Why use this technique?” section of the introduction.
From the database
Run American 100k model with the prompt “several vegetarian options” and pull into spreadsheet – done. It looks good, too:
When evaluating models, you should pick the smallest one that can deliver the accuracy you need. It will predict faster and require fewer hardware resources for training and inference. Frugality goes a long way.
GPT Agents
Added some content to the paper
Meeting. Need to compare the stars from something like “%ethnic vegan%” that doesn’t appear much in the training set but shows up significantly in the later data and compare that to the gpt for the prompt “ethnic vegan”
SBIRs
Stories! Done!
Work with Aaron on document similarity
Add script section
Create initial maps
Plus one of heatmap
Fix bug that doesn’t save details
Sprint planning
I have a much bigger application:
Now with hooks for showing a script!
Got a primitive script generator working. Next will be to load it and navigate a map
Do another review, and do something in the introduction that works with the idea that we are barely individuals. How that changes from childhood through adulthood to old age, and how technology has had a huge impact
SBIRs
9:15 Standup
3:00 Army
Timesheets!
GPT-Agents
Run the new LIWC data and generate two spreadsheets. One with the word numbers and one with the default settings. Done
A central goal of artificial intelligence in high-stakes decision-making applications is to design a single algorithm that simultaneously expresses generalizability by learning coherent representations of their world and interpretable explanations of its dynamics. Here, we combine brain-inspired neural computation principles and scalable deep learning architectures to design compact neural controllers for task-specific compartments of a full-stack autonomous vehicle control system. We discover that a single algorithm with 19 control neurons, connecting 32 encapsulated input features to outputs by 253 synapses, learns to map high-dimensional inputs into steering commands. This system shows superior generalizability, interpretability and robust-ness compared with orders-of-magnitude larger black-box learning systems. The obtained neural agents enable high-fidelity autonomy for task-specific parts of a complex autonomous system.
In “Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning”, we introduce Uncertainty Baselines, a collection of high-quality implementations of standard and state-of-the-art deep learning methods for a variety of tasks, with the goal of making research on uncertainty and robustness more reproducible. The collection spans 19 methods across nine tasks, each with at least five metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components and with minimal dependencies outside of the framework in which it is written. The included pipelines are implemented in TensorFlow, PyTorch, and Jax. Additionally, the hyperparameters for each baseline have been extensively tuned over numerous iterations so as to provide even stronger results.
Book
Twitter and Tear Gas
SBIRs
Adding optional buttons to TopicCombo so it’s possible to add a topic and not set a seed.
Need to check for the case where I am adding a topic to the group that provided the seed. No need to link to yourself
Save graph to DB, hopefully
Woohoo!
Taking a break
Saving the full graph to the DB!
How it looks today
I’m going to add a button to “find closest group” based on text analysis. Probably start with Doc2vec paragraph embeddings
Create stories for 1) DB buildout 2) Model save/load 3) GML generation
9:30 sprint planning
Creating tables and getting Graph read/write to the DB
GPT Agents
Rebuilt the code that takes into account the LIWC2015 components and how they relate/rollup. And I found one real difference between the ground truth and the gpt:
LIWC 2015 “Informal” word counts out of 500k words
4:15 Meeting. Going to make a spreadsheet of the untrained GPT yelp, and be done with data. When that gets back, re-run the spreadsheets, and also add a version of the z-test code that produces rollups with the original LIWC data.
In this paper, we tackle the detection of out-of-distribution (OOD) objects in semantic segmentation. By analyzing the literature, we found that current methods are either accurate or fast but not both which limits their usability in real world applications. To get the best of both aspects, we propose to mitigate the common shortcomings by following four design principles: decoupling the OOD detection from the segmentation task, observing the entire segmentation network instead of just its output, generating training data for the OOD detector by leveraging blind spots in the segmentation network and focusing the generated data on localized regions in the image to simulate OOD objects. Our main contribution is a new OOD detection architecture called ObsNet associated with a dedicated training scheme based on Local Adversarial Attacks (LAA). We validate the soundness of our approach across numerous ablation studies. We also show it obtains top performances both in speed and accuracy when compared to ten recent methods of the literature on three different datasets.
SBIRs
9:00 Sprint demos – done
More DB – working!
More GPT – got the seed response running. Now working on the topic response – done!
Added switching between raw content to support topics and details
Call Outlaw – done. Working out a tire mound and a compressor to be added to the build
Book
Rewriting the positioning statement and probably a lot of the proposal to reframe the books as a problem/solution as opposed to “look at these interesting things”
SBIRs
Enable calls to GPT
Set up for database, add row_id and parent_id to objects and then wrtite to_db and from_db methods (base class?)
Set up basic password management
Got db access working, and am writing/updating project tables. Each project has its own password so they can be shared
Meeting with John on the UI. I’m thinking that the demo can run entirely off of gml files that are generated by Graphbuilder
Write 2 short reviews. Did some more topical overview and wrote a paragraph on Meltdown
SBIRs
Verify that subsequent parent-node linking works – done. That took a while. There was more stuff to fix
Make sure that we don’t make redundant links, just update weights – done. No weight updating for now. I think I’d rather calculate them on the fly for now
Make sure that details get stored with topics – done. Not sure that overwriting the response is a good idea. I think a better idea is to store the current response and replace it in the raw text once the details are set.
Get to_string() to show when node is selected – done














You must be logged in to post a comment.