
7:00 – ASRC MKT
- Finished the first pass through the SASO slides. Need to start working on timing (25 min + 5 min questions)
- Start on poster (A0 size)
- Sent Wayne a note to get permission for 899
- Started setting up laptop. I hate this part. Google drive took hours to synchronize
- Java
- Python/Nvidia/Tensorflow
- Intellij
- Visual Studio
- MikTex
- TexStudio
- Xampp
- Vim
- TortoiseSVN
- WinSCP
- 7-zip
- Creative Cloud
- Acrobat
- Reader
- Illustrator
- Photoshop
- Microsoft suite
- Express VPN
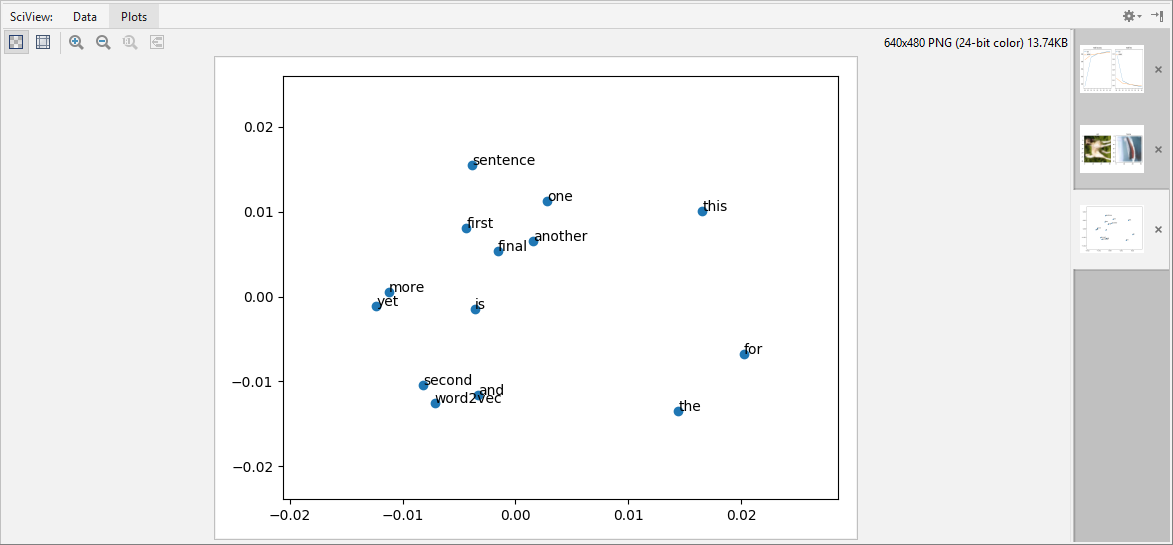


 I think it is reasonable to consider this a measure of alignment
I think it is reasonable to consider this a measure of alignment





You must be logged in to post a comment.