
It did a great job of summarizing my last paper: “The paper describes how to build maps of human belief as expressed through textual interaction in ways analogous to physical maps.”

It did a great job of summarizing my last paper: “The paper describes how to build maps of human belief as expressed through textual interaction in ways analogous to physical maps.”
The initial version of DaysToZero is up! Working on adding states now
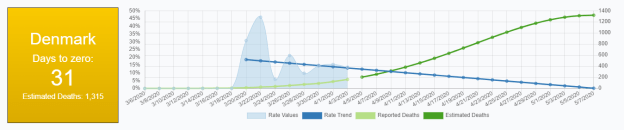
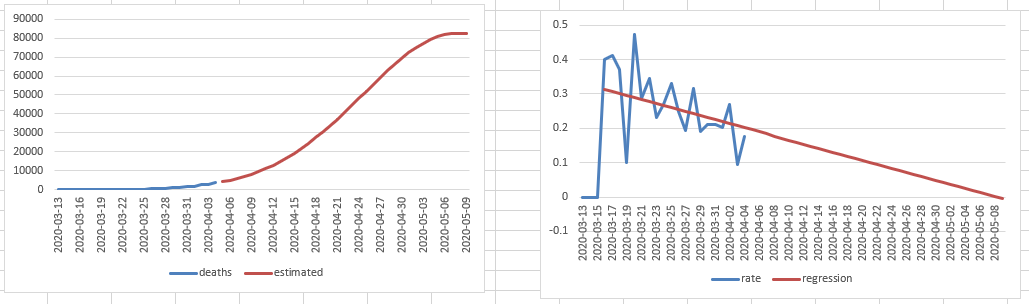
Got USA data working. New York looks very bad:
Evaluating the fake news problem at the scale of the information ecosystem
Bringing Stories Alive: Generating Interactive Fiction Worlds
Ran through the presentation with David. He pointed out that stampedes bouncing off the edge of the environment look like flocking, so I generated a new map where the stampede gathers and runs off the edge

7:00 – 9:00 ASRC GOES
The brains of birds synchronize when they sing duets
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
In Data Voids: Where Missing Data Can Easily Be Exploited, Golebiewski teams up with danah boyd (Microsoft Research; Data & Society) to demonstrate how data voids are exploited by manipulators eager to expose people to problematic content including falsehoods, misinformation, and disinformation.
Data voids are often difficult to detect. Most can be harmless until something happens that causes lots of people to search for the same term, such as a breaking news event, or a reporter using an unfamiliar phrase. In some cases, manipulators work quickly to produce conspiratorial content to fill a void, whereas other data voids, such as those from outdated terms, are filled slowly over time. Data voids are compounded by the fraught pathways of search-adjacent recommendation systems such as auto-play, auto-fill, and trending topics; each of which are vulnerable to manipulation.
Persuading Algorithms With an AI Nudge Fact-Checking Can Reduce the Spread of Unreliable News. It Can Also Do the Opposite.
Tesla Autopilot Duped By ‘Phantom’ Images: Researchers were able to fool popular autopilot systems into perceiving projected images as real – causing the cars to brake or veer into oncoming traffic lanes.
An ant colony has memories that its individual members don’t have
7:00 – ASRC
7:00 – 5:00 ASRC PhD
\def\changemargin#1#2{\list{}{\rightmargin#2\leftmargin#1}\item[]}
\let\endchangemargin=\endlist
\begin{changemargin}{1.5cm}{1.5cm}
They were one man, not thirty. For as the one ship that held them all; though it was put together of all contrasting things-oak, and maple, and pine wood; iron, and pitch, and hemp-yet all these ran into each other in the one concrete hull, which shot on its way, both balanced and directed by the long central keel; even so, all the individualities of the crew, this man’s valor, that man’s fear; guilt and guiltiness, all varieties were welded into oneness, and were all directed to that fatal goal which Ahab their one lord and keel did point to.
\end{changemargin}
The dynamics of norm change in the cultural evolution of language
When Hillclimbers Beat Genetic Algorithms in Multimodal Optimization
7:00 – 5:30 ASRC GEOS

nodePath.node(). However, there is no unambiguous way to convert back. That’s important: sometimes you need a NodePath, sometimes you need a node pointer. Because of this, it is recommended that you store NodePaths, not node pointers. When you pass parameters, you should probably pass NodePaths, not node pointers. The callee can always convert the NodePath to a node pointer if it needs to.

Phil 7:00 – 5:00 ASRC NASA GEOS
Semantics-Space-Time Cube. A Conceptual Framework for Systematic Analysis of Texts in Space and Time
7:00 – 3:30 ASRC PhD/NASA


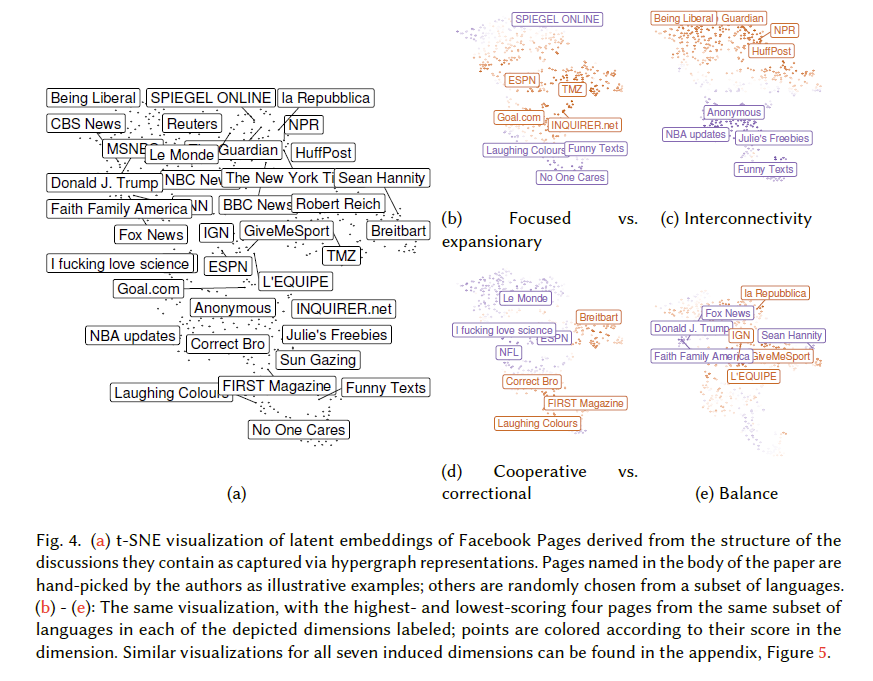

7:00 – 7:00 ASRC PhD
Let the House Subcommittee investigations begin! Also, better redistricting?
7:00 – 5:00 ASRC PhD/BD
Scientists have found that the brains of close friends respond in remarkably similar ways as they view a series of short videos: the same ebbs and swells of attention and distraction, the same peaking of reward processing here, boredom alerts there. The neural response patterns evoked by the videos — on subjects as diverse as the dangers of college football, the behavior of water in outer space, and Liam Neeson trying his hand at improv comedy — proved so congruent among friends, compared to patterns seen among people who were not friends, that the researchers could predict the strength of two people’s social bond based on their brain scans alone.
7:00 – 2:00 ASRC PhD/BD

You must be logged in to post a comment.