
Today is a federal holiday, so no rocket science
Huggingface has a pipeline interface now that is pretty abstract. This works:
from transformers import pipeline
translator = pipeline("translation_en_to_fr")
print(translator("Hugging Face is a technology company based in New York and Paris", max_length=40))
- [{‘translation_text’: ‘Hugging Face est une entreprise technologique basée à New York et à Paris.’}]
DtZ is back up! Too many countries have the disease and the histories had to be cropped to stay under the data cap for the free service
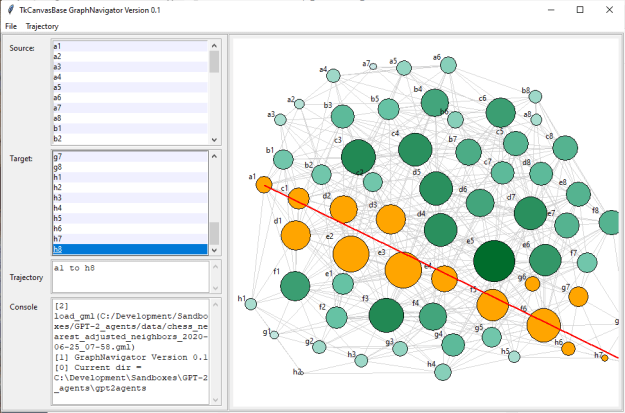
GPT-2 Agents
- Work on more granular path finding
- Going to try the hypotenuse of distance to source and line first – nope
- Trying looking for the distances of each and doing a nested sort
- I had a problem where I was checking to see whether a point was between the current node and the target node using the original line between the source and target nodes. Except that I was checking on a lone from the current node to the target, and failing the test. Oops! Fixed
- I went back to the hypotenuse version now that the in_between test isn’t broken and look at that!
-
- Added the option for coarse or granular paths
- Start thinking about topic extraction for a given corpus
#COVID
- Evaluate Arabic to English translation. Got it working!
from transformers import MarianTokenizer, MarianMTModel from typing import List src = 'ar' # source language trg = 'en' # target language sample_text = "لم يسافر أبي إلى الخارج من قبل" sample_text2 = "الصحة_السعودية تعلن إصابة أربعيني بفيروس كورونا بالمدينة المنورة حيث صنفت عدواه بحالة أولية مخالطة الإبل مشيرة إلى أن حماية الفرد من(كورونا)تكون باتباع الإرشادات الوقائية والمحافظة على النظافة والتعامل مع #الإبل والمواشي بحرص شديد من خلال ارتداء الكمامة " mname = f'Helsinki-NLP/opus-mt-{src}-{trg}' model = MarianMTModel.from_pretrained(mname) tok = MarianTokenizer.from_pretrained(mname) batch = tok.prepare_translation_batch(src_texts=[sample_text2]) # don't need tgt_text for inference gen = model.generate(**batch) # for forward pass: model(**batch) words: List[str] = tok.batch_decode(gen, skip_special_tokens=True) print(words) - It took a few tries to find the right model. The naming here is very haphazard.
- Asked for a sanity check from the group
- This:
الصحة_السعودية تعلن إصابة أربعيني بفيروس كورونا بالمدينة المنورة حيث صنفت عدواه بحالة أولية مخالطة الإبل مشيرة إلى أن حماية الفرد من(كورونا)تكون باتباع الإرشادات الوقائية والمحافظة على النظافة والتعامل مع #الإبل والمواشي بحرص شديد من خلال ارتداء الكمامة
- Translates to this:
Saudi health announces a 40-year-old corona virus in the city of Manora, where his enemy was classified as a primary camel conglomerate, indicating that the protection of the individual from Corona would be through preventive guidance, hygiene, and careful handling of the Apple and the cattle by wearing the gag.
- This:
- Write script that takes a batch of rows and adds translations until all the rows in the table are complete
Book chat
- List of folks who would be interesting to interview
- Stewart Russel
- Stuart Kauffman
- Alex (Sandy) Pentland
- Kate Starbird
- Joanna Bryson
- Daniel DeNicola
- Margaret Gilbert
- Joseph Liechty /Cecelia Clegg
- Rebecca Solint
- Zeynep Tefuchi
- Christian Jacob (directeur de recherche at the Centre national de la recherche scientifique in Paris)
- Ezra Klien



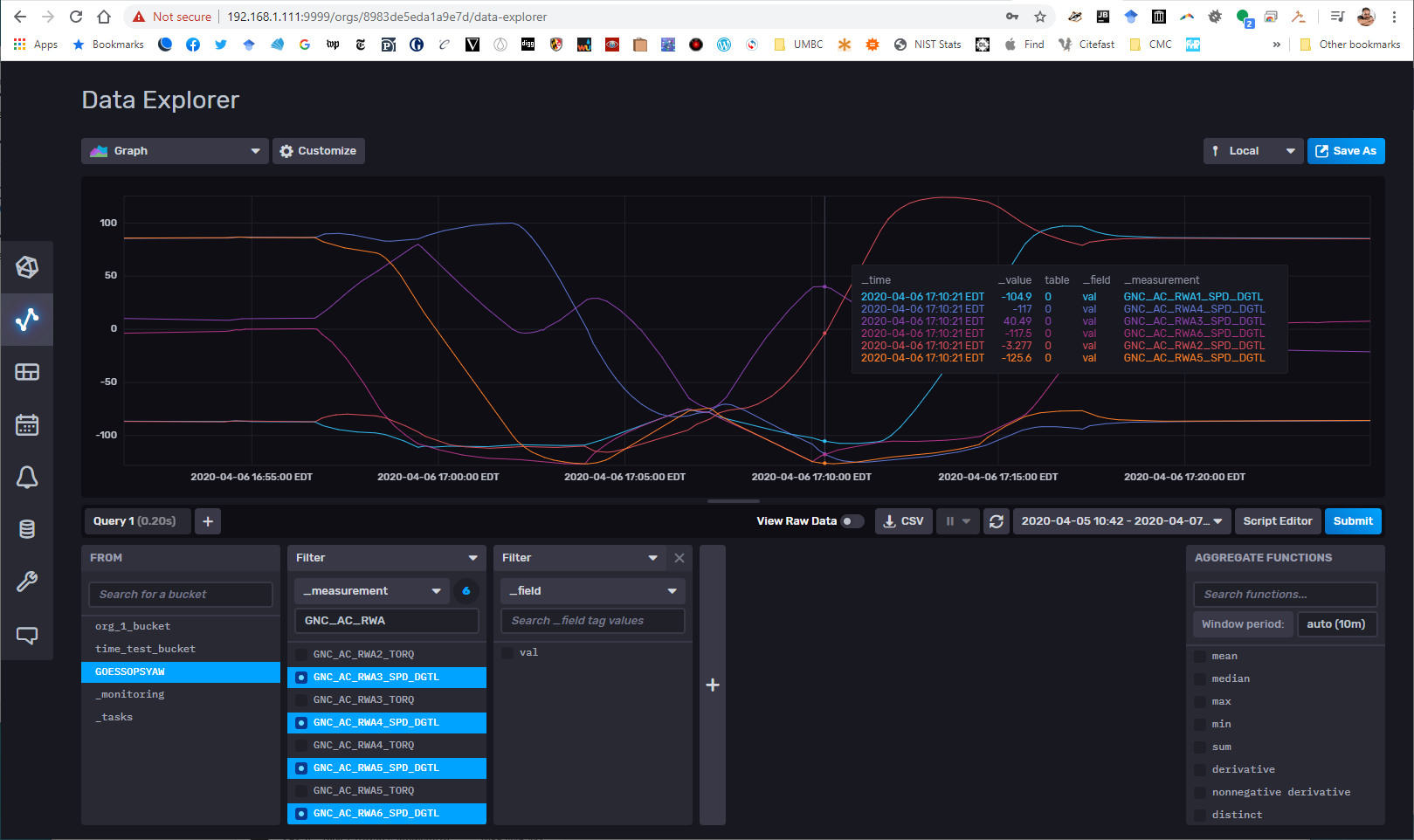


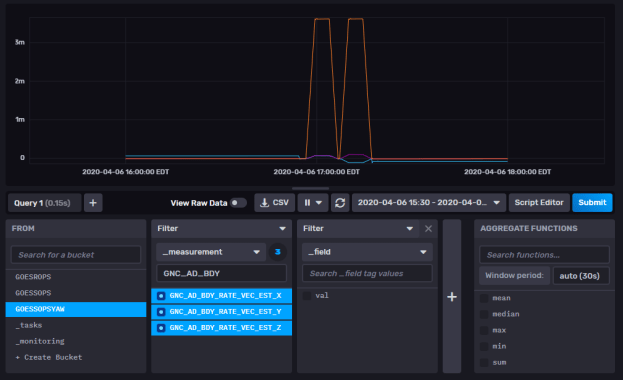

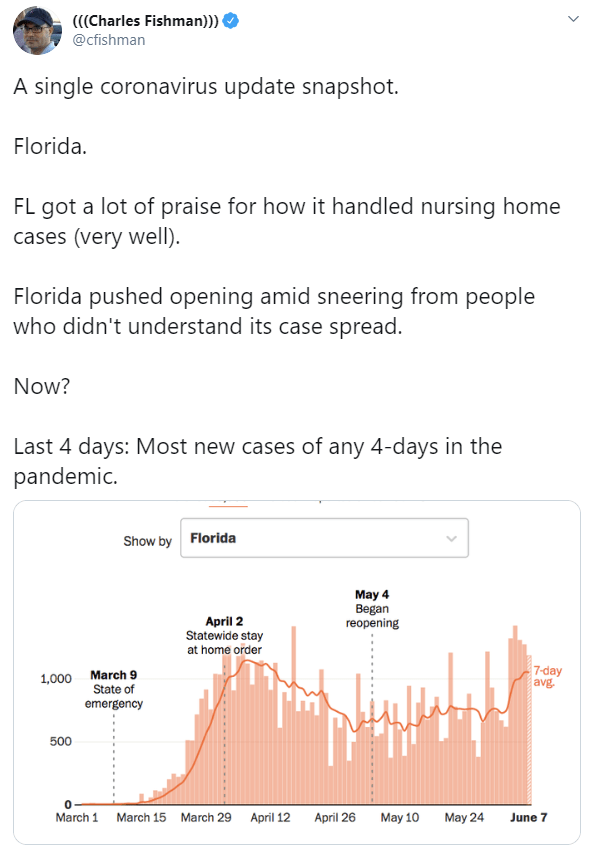

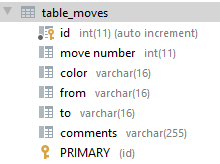
 All the writes are working. I’ll do the reads Monday. Everything looks pretty consistent, though.
All the writes are working. I’ll do the reads Monday. Everything looks pretty consistent, though.





































You must be logged in to post a comment.