
Getting Started With Stable Diffusion: A Guide For Creators
- We offer comprehensive evidence of preferences for ideological congruity when people engage with politicians, pundits, and news organizations on social media. Using 4 years of data (2016–2019) from a random sample of 1.5 million Twitter users, we examine three behaviors studied separately to date: (i) following of in-group versus out-group elites, (ii) sharing in-group versus out-group information (retweeting), and (iii) commenting on the shared information (quote tweeting). We find that the majority of users (60%) do not follow any political elites. Those who do follow in-group elite accounts at much higher rates than out-group accounts (90 versus 10%), share information from in-group elites 13 times more frequently than from out-group elites, and often add negative comments to the shared out-group information. Conservatives are twice as likely as liberals to share in-group versus out-group content. These patterns are robust, emerge across issues and political elites, and exist regardless of users’ ideological extremity.
Tasks
- Jim Donnies (winterize and generator) – done
- BGE
- ProServ
SBIRs
- 9:30 RCSNN design discussion – done
- 2:00 Meeting with Loren – done
- Write up some sort of trip report
- Reach out to folks from conference – done
- Start on distributed data dictionary? Kind of?
Book
- Roll in Brenda’s Changes – continuing
- Ping Ryan for chapter/paper/article on authoritarians and sociotechnical systems
GPT Agents
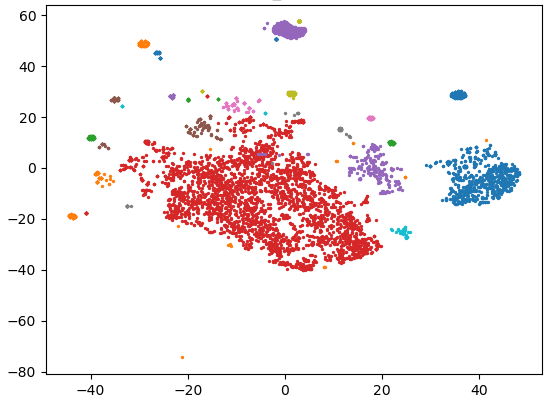
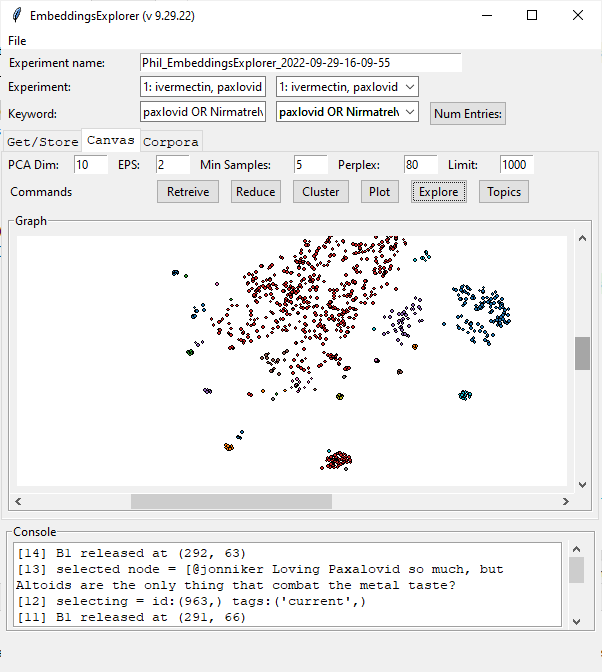
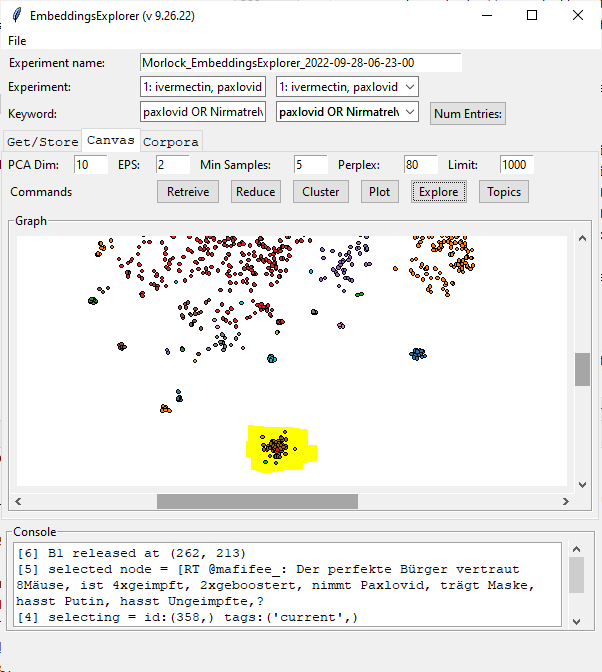
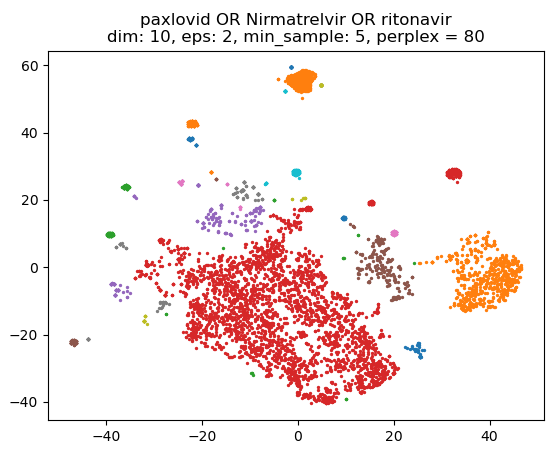
- Add cluster ID to console text when a node is clicked and a button to “exclude topic” that adds an entry to “table_exclude” that has experiment_id, keyword (or “all_keywords”), and cluster_id. These clusters are excluded when a corpora is generated.
- Re-clustering will cause these rows to be deleted from the table
- Add training corpora generation with checkboxes for meta-wrappers and dropdown for “before” or “after”









You must be logged in to post a comment.