7:00 – 4:30 ASRC MKT
- R2D3 is an experiment in expressing statistical thinking with interactive design. Find us at @r2d3us.

- Foundations of Temporal Text Networks
- Davide Vega (Scholar)
- Matteo Magnani (Scholar)
- Three fundamental elements to understand human information networks are the individuals (actors) in the network, the information they exchange, that is often observable online as text content (emails, social media posts, etc.), and the time when these exchanges happen. An extremely large amount of research has addressed some of these aspects either in isolation or as combinations of two of them. There are also more and more works studying systems where all three elements are present, but typically using ad hoc models and algorithms that cannot be easily transferred to other contexts. To address this heterogeneity, in this article we present a simple, expressive and extensible model for temporal text networks, that we claim can be used as a common ground across different types of networks and analysis tasks, and we show how simple procedures to produce views of the model allow the direct application of analysis methods already developed in other domains, from traditional data mining to multilayer network mining.
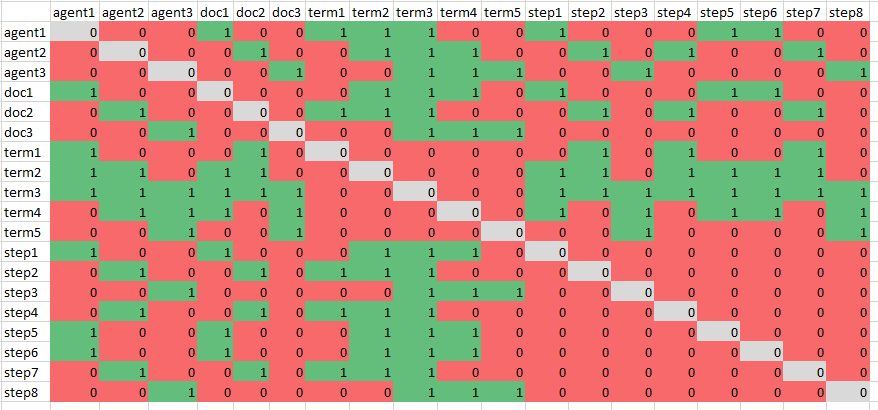
- Ok, I’ve been reading the paper and if I understand it correctly, it’s pretty straightforward and also clever. It relates a lot to the way that I do term document matrices, and then extends the concept to include time, agents, and implicitly anything you want to. To illustrate, here’s a picture of a tensor-as-matrix:
 The important thing to notice is that there are multiple dimensions represented in a square matrix. We have:
The important thing to notice is that there are multiple dimensions represented in a square matrix. We have:
- agents
- documents
- terms
- steps
- This picture in particular is of an undirected adjacency matrix, but I think there are ways to handle in-degree and out-degree, though I think that’s probably better handled by having one matrix for indegree and one for out.
- Because it’s a square matrix, we can calculate the steps between any node that’s on the matrix, and the centrality, simply by squaring the matrix and keeping track of the steps until the eigenvector settles. We can also weight nodes by multiplying that node’s row and column by the scalar. That changes the centrality, but ot the connectivity. We can also drop out components (steps for example) to see how that changes the underlying network properties.
- If we want to see how time affects the development of the network, we can start with all the step nodes set to a zero weight, then add them in sequentially. This means, for example, that clustering could be performed on the nonzero nodes.
- Some or all of the elements could be factorized using NMF, resulting in smaller, faster matrices.
- Network embedding could be useful too. We get distances between nodes. And this looks really important: Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec
- I think I can use any and all of the above methods on the network tensor I’m describing. This is very close to a mapping solution.
- Ok, I’ve been reading the paper and if I understand it correctly, it’s pretty straightforward and also clever. It relates a lot to the way that I do term document matrices, and then extends the concept to include time, agents, and implicitly anything you want to. To illustrate, here’s a picture of a tensor-as-matrix:
- The Shifting Discourse of the European Central Bank: Exploring Structural Space in Semantic Networks (cited by the above paper)
- Convenient access to vast and untapped collections of documents generated by organizations is a valuable resource for research. These documents (e.g., Press releases, reports, speech transcriptions, etc.) are a window into organizational strategies, communication patterns, and organizational behavior. However, the analysis of such large document corpora does not come without challenges. Two of these challenges are 1) the need for appropriate automated methods for text mining and analysis and 2) the redundant and predictable nature of the formalized discourse contained in these collections of texts. Our article proposes an approach that performs well in overcoming these particular challenges for the analysis of documents related to the recent financial crisis. Using semantic network analysis and a combination of structural measures, we provide an approach that proves valuable for a more comprehensive analysis of large and complex semantic networks of formal discourse, such as the one of the European Central Bank (ECB). We find that identifying structural roles in the semantic network using centrality measures jointly reveals important discursive shifts in the goals of the ECB which would not be discovered under traditional text analysis approaches.
- Comparative Document Analysis for Large Text Corpora
- This paper presents a novel research problem, Comparative Document Analysis (CDA), that is, joint discovery of commonalities and differences between two individual documents (or two sets of documents) in a large text corpus. Given any pair of documents from a (background) document collection, CDA aims to automatically identify sets of quality phrases to summarize the commonalities of both documents and highlight the distinctions of each with respect to the other informatively and concisely. Our solution uses a general graph-based framework to derive novel measures on phrase semantic commonality and pairwise distinction, where the background corpus is used for computing phrase-document semantic relevance. We use the measures to guide the selection of sets of phrases by solving two joint optimization problems. A scalable iterative algorithm is developed to integrate the maximization of phrase commonality or distinction measure with the learning of phrase-document semantic relevance. Experiments on large text corpora from two different domains—scientific papers and news—demonstrate the effectiveness and robustness of the proposed framework on comparing documents. Analysis on a 10GB+ text corpus demonstrates the scalability of our method, whose computation time grows linearly as the corpus size increases. Our case study on comparing news articles published at different dates shows the power of the proposed method on comparing sets of documents.
- Social and semantic coevolution in knowledge networks
- Socio-semantic networks involve agents creating and processing information: communities of scientists, software developers, wiki contributors and webloggers are, among others, examples of such knowledge networks. We aim at demonstrating that the dynamics of these communities can be adequately described as the coevolution of a social and a socio-semantic network. More precisely, we will first introduce a theoretical framework based on a social network and a socio-semantic network, i.e. an epistemic network featuring agents, concepts and links between agents and between agents and concepts. Adopting a relevant empirical protocol, we will then describe the joint dynamics of social and socio-semantic structures, at both macroscopic and microscopic scales, emphasizing the remarkable stability of these macroscopic properties in spite of a vivid local, agent-based network dynamics.
- Tensorflow 2.0 feedback request
- Shortly, we will hold a series of public design reviews covering the planned changes. This process will clarify the features that will be part of TensorFlow 2.0, and allow the community to propose changes and voice concerns. Please join developers@tensorflow.org if you would like to see announcements of reviews and updates on process. We hope to gather user feedback on the planned changes once we release a preview version later this year.