Done with a week of riding my bike around:
On a related note, in talking to the other members of the group about the dissertation and research, the resonant points seem to involve network density and stiffness, and the mathematical similarities of animal motion and human text usage
7:30 – 3:30 ASRC NASA GEOS
- Working on the JASSS submission process. Need to get 100-word bios for all authors
- When submitting your article through the web (see below), you will also be asked to provide:
- the names, affiliations, addresses, home web pages and emails addresses of all authors;
- a brief biography (about 100 words) for each of the authors;
- confirmation that the article has not been published or submitted elsewhere for publication.
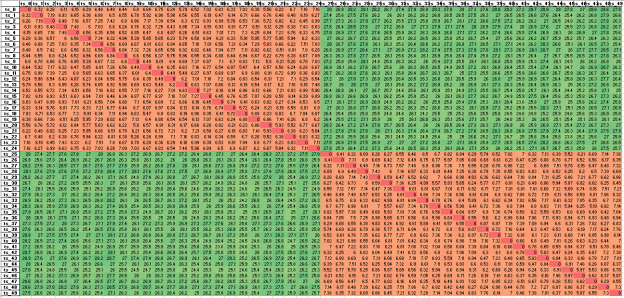
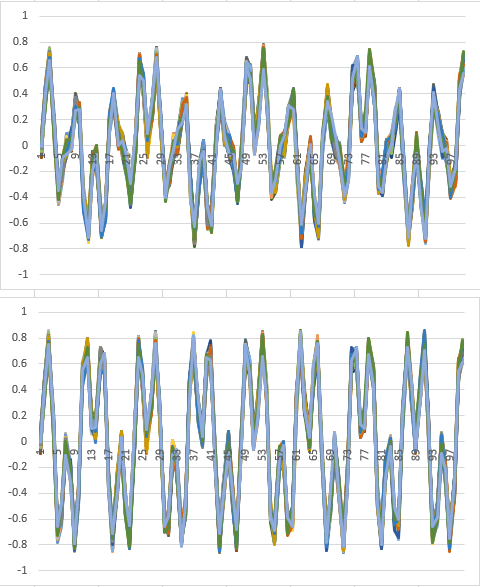
- Re-did the waveforms for DTW with the full data and 100 samples. I’ll fire it up on the way out the door today
- Starting to build an automated pipeline for producing time-series data for ML
- Started meta-skills document













You must be logged in to post a comment.