Need to be able to turn out a numeric equivalent. Done with floating point. This:
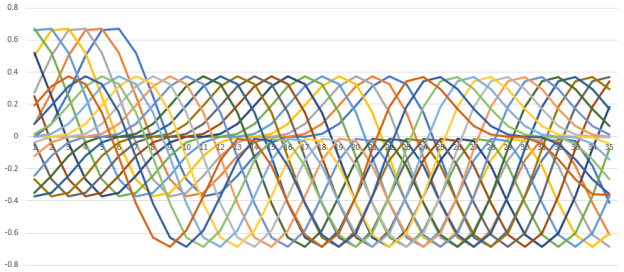
#confg: {"function":math.sin(xx)*math.sin(xx/2.0)*math.cos(xx/4.0), "rows":100, "sequence_length":20, "step":1, "delta":0.4, "type":"floating_point"}
0.0,0.07697897630719268,0.27378318599563484,0.5027638400821064,0.6604469814238397,0.6714800165989514,0.519596709539434,0.2524851001382131,-0.04065231596017931,-0.2678812526747579,-0.37181365763470914,-0.34898182120310306,-0.24382057359778858,-0.12182487479311599,-0.035942415169752356,-0.0027892469005274916,0.00019865778200507415,0.016268713740310237,0.07979661440830532,0.19146155036709192,
0.07697897630719312,0.2737831859956355,0.5027638400821071,0.6604469814238401,0.6714800165989512,0.5195967095394334,0.2524851001382121,-0.04065231596018022,-0.26788125267475843,-0.37181365763470925,-0.3489818212031028,-0.24382057359778805,-0.12182487479311552,-0.0359424151697521,-0.0027892469005274395,0.0001986577820050832,0.016268713740310397,0.07979661440830574,0.19146155036709248,0.31158944024296154,
0.2737831859956368,0.502763840082108,0.6604469814238405,0.6714800165989508,0.5195967095394324,0.25248510013821085,-0.04065231596018143,-0.2678812526747592,-0.37181365763470936,-0.34898182120310245,-0.24382057359778747,-0.12182487479311502,-0.03594241516975184,-0.002789246900527388,0.00019865778200509222,0.01626871374031056,0.07979661440830614,0.191461550367093,0.311589440242962,0.3760334615921674,
0.5027638400821092,0.6604469814238411,0.6714800165989505,0.5195967095394312,0.25248510013820913,-0.040652315960182955,-0.26788125267476015,-0.37181365763470964,-0.348981821203102,-0.24382057359778667,-0.12182487479311428,-0.03594241516975145,-0.0027892469005273107,0.00019865778200510578,0.016268713740310803,0.07979661440830675,0.1914615503670939,0.3115894402429629,0.3760334615921675,0.3275646734005755,
0.660446981423842,0.6714800165989498,0.5195967095394289,0.2524851001382062,-0.04065231596018568,-0.2678812526747618,-0.37181365763471,-0.34898182120310123,-0.24382057359778553,-0.1218248747931133,-0.03594241516975093,-0.0027892469005272066,0.00019865778200512388,0.016268713740311122,0.07979661440830756,0.19146155036709495,0.31158944024296387,0.3760334615921676,0.3275646734005745,0.1475692800414062,
0.671480016598949,0.5195967095394267,0.25248510013820324,-0.04065231596018842,-0.2678812526747636,-0.3718136576347104,-0.34898182120310045,-0.24382057359778414,-0.12182487479311209,-0.03594241516975028,-0.002789246900527077,0.0001986577820051465,0.016268713740311528,0.07979661440830856,0.19146155036709636,0.3115894402429648,0.37603346159216783,0.32756467340057344,0.1475692800414041,-0.12805444308254293,
0.5195967095394245,0.2524851001382003,-0.04065231596019116,-0.2678812526747653,-0.3718136576347107,-0.3489818212030998,-0.24382057359778303,-0.12182487479311109,-0.03594241516974975,-0.0027892469005269733,0.00019865778200516457,0.016268713740311847,0.07979661440830936,0.19146155036709747,0.3115894402429657,0.37603346159216794,0.32756467340057244,0.147569280041402,-0.1280544430825456,-0.41793663502550105,
0.2524851001381973,-0.04065231596019389,-0.26788125267476703,-0.3718136576347111,-0.3489818212030989,-0.2438205735977817,-0.12182487479310988,-0.0359424151697491,-0.002789246900526843,0.00019865778200518717,0.01626871374031225,0.07979661440831039,0.1914615503670989,0.3115894402429671,0.3760334615921681,0.3275646734005709,0.14756928004139883,-0.1280544430825496,-0.41793663502550454,-0.6266831461371138,

 \
\


You must be logged in to post a comment.