I want to write a paper about the one unambiguously good option that AI/ML + simulation provides – problem domain exploration and the industrialization of imagination. The failures in Vietnam, Iraq, and Afghanistan, not to mention 9/11 and Pearl Harbor have all been described as failures of imagination. These failures exist at multiple levels – the tactical (think Jimmy Doolittle), and the strategic (human nature). AI/ML allows us to safely explore these domains before the unimaginable occurs. Because these potentials can be visualized in narratives, it is possible to broadly and compellingly present these possibilities, and increase the effectiveness and resiliency of our choices in combat and combat-adjacent domains.
- Enhanced simulation means that ML can explore tactical options
- Deliver the right amount of energy in the right place for the lowest cost
- Language model maps means that ML can explore strategic options
- And maybe avoid a fourth Vietnam
labml.ai Annotated PyTorch Paper Implementations
This is a collection of simple PyTorch implementations of neural networks and related algorithms. These implementations are documented with explanations, and the website renders these as side-by-side formatted notes. We believe these would help you understand these algorithms better. We are actively maintaining this repo and adding new implementations.
GPT-Agents
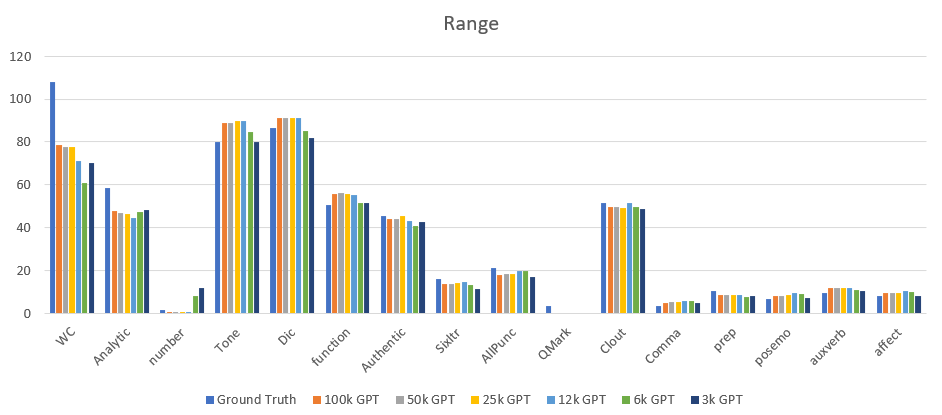
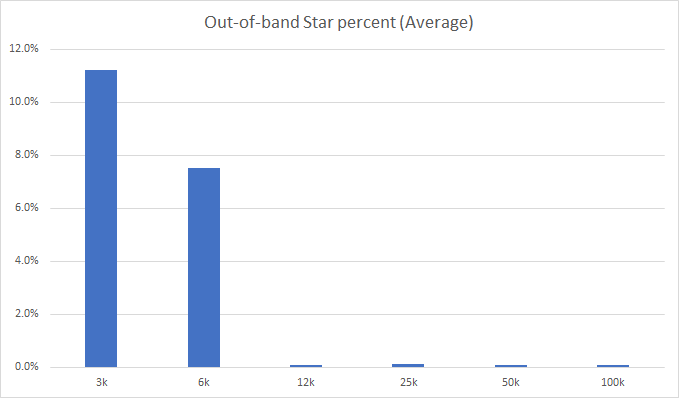
- Need to do some preliminary (e.g. stars) evaluations on the synthesized and ground truth data before meeting
- 3:30 Meeting
- Went over results
- Make a new 50k, 25k, and 12k model and do the same tests
- Sent Shimei a set of CSV files for
- On the Opportunities and Risks of Foundation Models
- AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles (e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on conventional deep learning and transfer learning, their scale results in new emergent capabilities, and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
SBIR(s)
- Something something NASA proposal?
- Meeting with Rukan
- Sprint planning













You must be logged in to post a comment.