
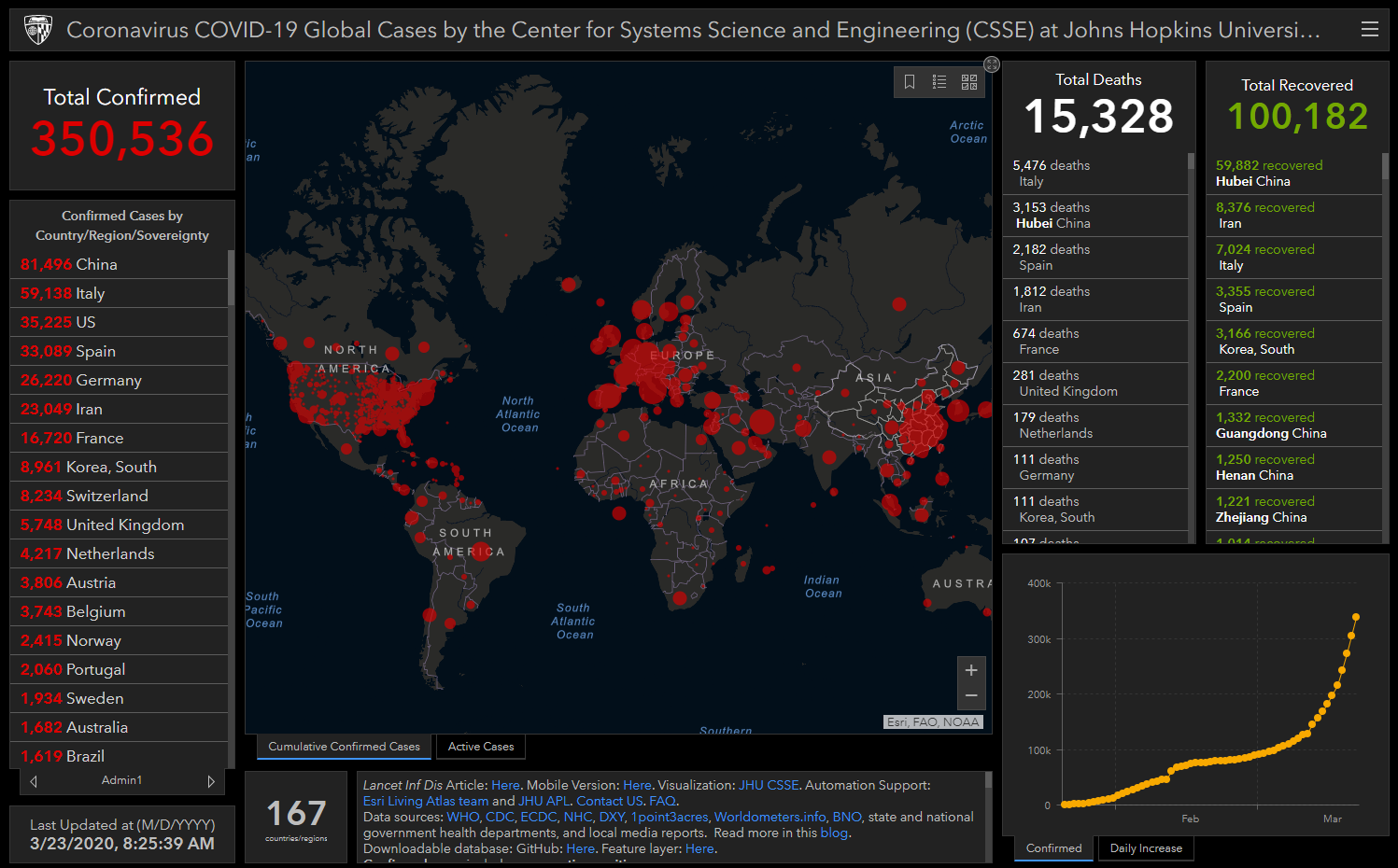
I need to go grocery shopping today. A friend of mine has come down with the virus. He’s in his 30’s, and I’m feeling vulnerable. I went down to the shop and dug up my painting masks. Turns out I have a few, so that’s what I’m going shopping with. Here’s why, from the NY Times:
When researchers conducted systematic review of a variety of interventions used during the SARS outbreak in 2003, they found that washing hands more than 10 times daily was 55 percent effective in stopping virus transmission, while wearing a mask was actually more effective — at about 68 percent. Wearing gloves offered about the same amount of protection as frequent hand-washing, and combining all measures — hand-washing, masks, gloves and a protective gown — increased the intervention effectiveness to 91 percent.
Podcast with BBC’s misinformation reporter: https://podcasts.apple.com/gb/podcast/the-political-party/id595312938?i=1000470048553
- A friend of mine who works in Whitehall has told me that the army are going to be on the streets this week arresting people who don’t listen to this podcast. If that sounds familiar, you’ll be aware that this crisis has already been fertile ground for disinformation. Marianna Spring is a BBC specialist reporter covering disinformation and social media. In this fascinating interview, Marianna reveals how disinformation and misinformation gets so widely shared, why we share it, how to spot it, what the trends are, how it differs around the world and so much more. This is a brilliant insight not just into the sharing of inaccurate information, but into human behaviour.
D20
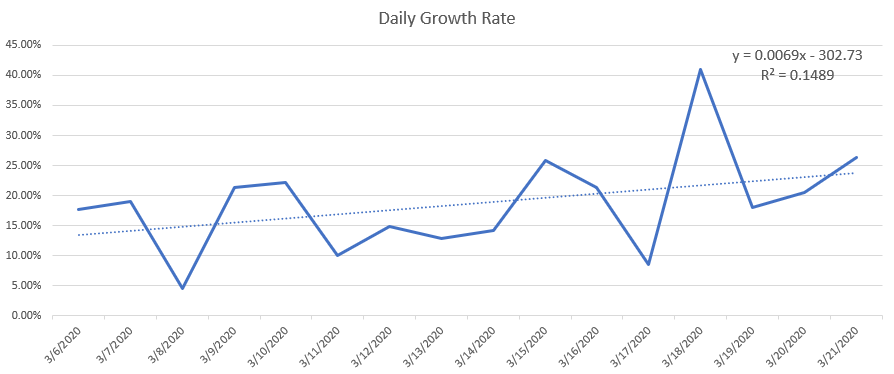
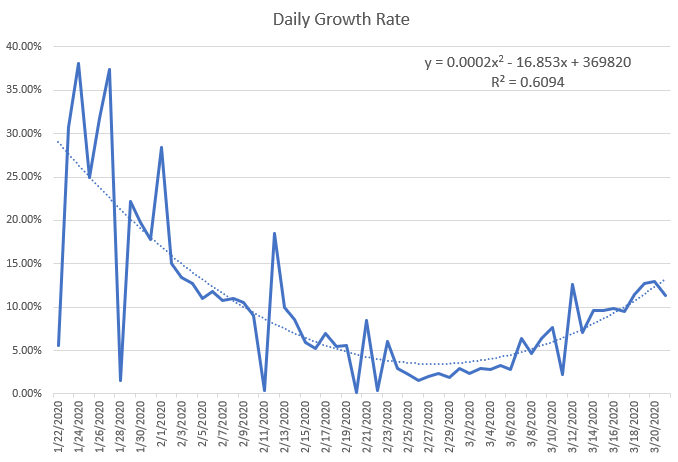
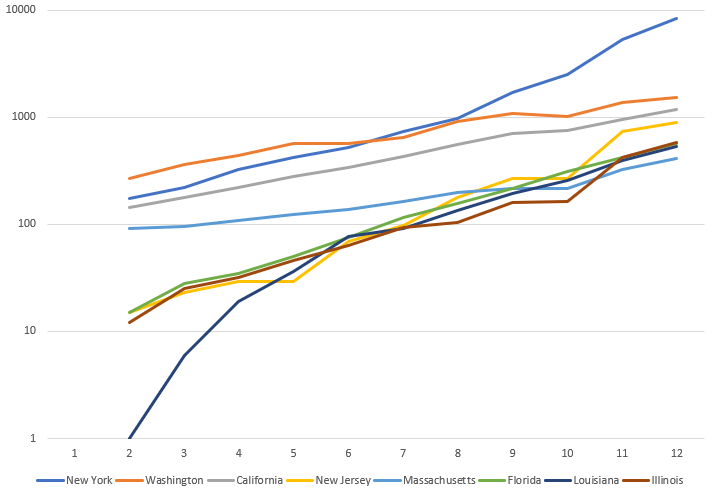
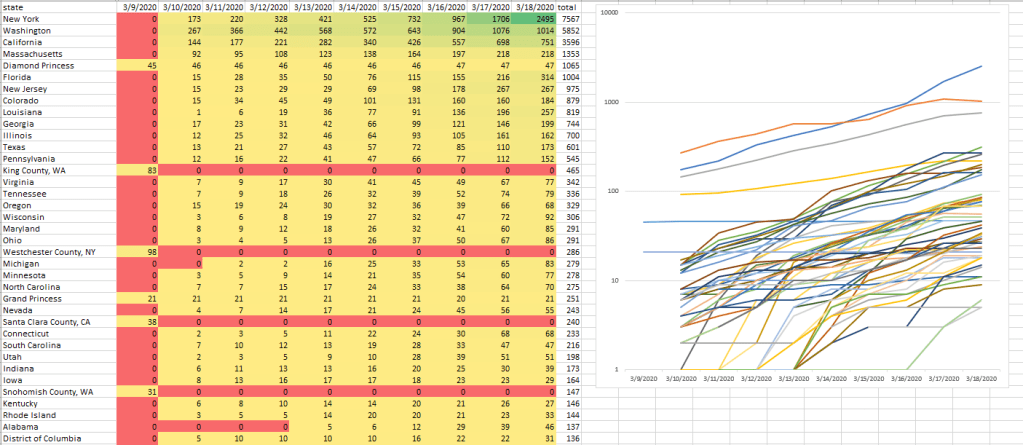
- Changed the calculations from the linear regression to handle cases where the virus is under control, like China – first pass is done
- Have the linear regression only go back some number of weeks/months. I’m worried about missing a second wave
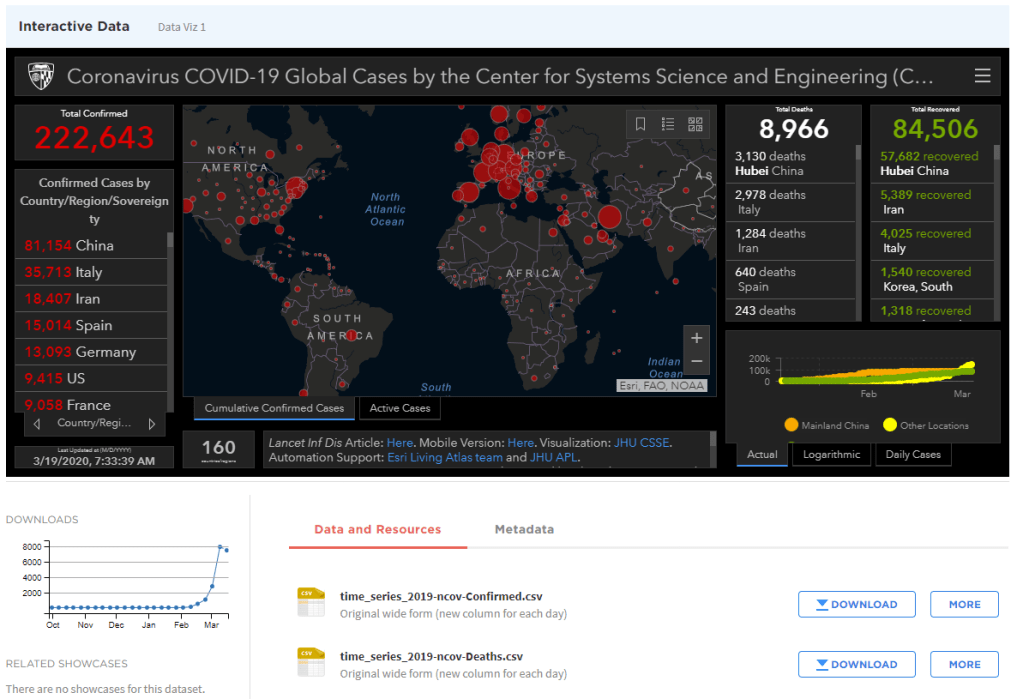
- Need to add a disclaimer about the quality of the predictions is dependent on the quality of the data, and that we expect that as poorer countries come online, these trends may be erratic and inaccurate.
- Add an UNSET state. The ETS will only set the state if it is UNSET. This lets regression predictions to be used until the ETS is working well – done
- I think showing the linear and ETS mean prediction is a good way to start including ETS values
- Found the page that shows how to adjust parameters: https://www.statsmodels.org/stable/examples/notebooks/generated/exponential_smoothing.html
GOES
- Try to create an image from the stored tar
- Start setting up InfluxDB2
IRAD Meeting at 2:00
ML Group at 4:00
- Put together a list of potential papers to present. No need, I’ll do infinitely wide networks
- Had just a lovely online evening of figuring out how to use some (terrible!) webex tools, and trying to figure out Neural ODEs. It was an island of geeky normalcy for a few hours. This may be a more comprehensible writeup.


















You must be logged in to post a comment.