TL;DR: We introduce Photon, a live demo of a natural language interface to databases based on our latest research in neural semantic parsing. 🔗 https://naturalsql.com/
Ai Weiwei’s CORONATION is the first feature-length documentary about the coronavirus in Wuhan. As the first city hit in the global pandemic, the Chinese metropolis with a population of 11 million was placed under an unprecedented lockdown.
Working on potential areas of contribution. Added links and extended the text. Need to wait for the last paper to become active on ArXiv
Working on my CV so I can be considered for an adjunct position – done(?)
GOES
10:00 Meeting with Vadim
Need to add an exit if a duplicate entry is made in DataDictionary
Yaw flip is working again!
2:00 status
#COVID
Look at translations!
They look good! Going to translate the annotated tweets and use them as a base for finding similar ones in the DB
The only issue is that a few words are being consistently mistranslated or rendered phonetically. Need to put together a data dictionary for some post processing
JuryRoom
Good discussion with Tony about knowledge graphs and the analytics in general
Tag-team coding with Vadim – good progress. More tomorrow
Make slides for T in the GPT-2 Agents IRAD – done?
GPT-2 Agents
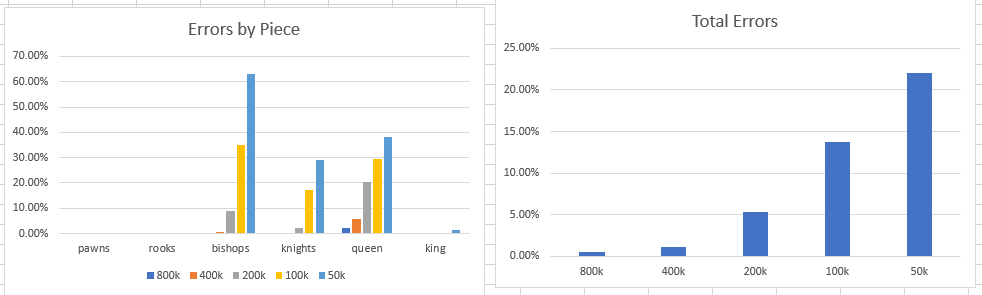
Finished updates to paper. The results are kind of cool. Here’s the error rate by model
It’s pretty clear from looking at the charts is the ability of the model to learn legal moves is proportional to the size of the corpora. These are complicated rules, particularly for knights, bishops, and the queen. There needs to be a lot of examples in the text.
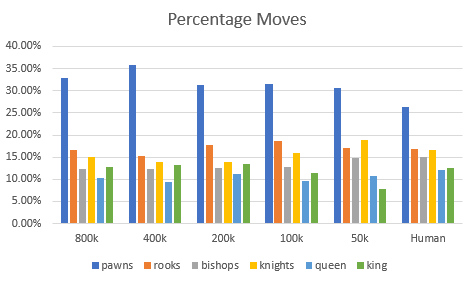
On the other hand, let’s look at overall percentage of moves by piece when compared to human patterns:
The overall patterns are substantially the same. Here’s the 2-tailed correlation:
There really is no substantial difference. To me that means that the low-frequency(?) information makes it into the model with this kind of thematic information with less text. Kinda cool!
JSON parser
Got the code working to grab the right files and read them:
for filename in glob.glob('*.jsonl', recursive=True): trimmed = re.findall(r"\\\d+_to_\d+", filename) print("{}/{}".format(filename, trimmed)) with open(filename) as f: jobj = json.load(f) print(json.dumps(jobj, indent=4, sort_keys=True))
Working on the schemas now
It looks like it may be possible to generate a full table representation using two packages. The first is genson, which you use to generate the schema. Then that schema is used by jsonschema2db, which should produce the tables (This only works for postgres, so I’ll have to install that). The last step is to insert the data, which is also handled by jsonschema2db
Schema generation worked like a charm
Postgres and drivers are installed. That’s enough good luck for the day
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint
word_embeddings = model.transformer.wte.weight # Word Token Embeddings
position_embeddings = model.transformer.wpe.weight # Word Position Embeddings
Many resources on machine learning (ML) methodology recommend, or even state as crucial, that one scale (or standardize) one’s data, i.e. divide each variable by its standard deviation (after subtracting the mean), before applying Principal Component Analysis (PCA). Here we will show why that can be problematic, and provide alternatives.
Our code examples are short (less than 300 lines of code), focused demonstrations of vertical deep learning workflows.
All of our examples are written as Jupyter notebooks and can be run in one click in Google Colab, a hosted notebook environment that requires no setup and runs in the cloud. Google Colab includes GPU and TPU runtimes.
Hitting malformed descriptions in the 200k model that caused the program to crash twice. It was at 146k moves, which is probably enough to get statistics on illegal moves. Fixed the error with a try/except and moved onto the next model. I’ll go back and rerun if the fix works. Now over 100k moves on the 100k model with no problems. Yet.
Trying to work through what a malfunctioning RW would look like to the vehicle control. RW2 is critical for Roll, and RW5 is critical for Pitch and Roll. How is this system redundant?
I think I need to make some plots to understand this
So I think this is starting to make sense. There is always a point where any two rwheels are equal. You can see this on the RW1-RW4 graph. On the other, it’s just further to the left. This means that you can make them cancel and then manipulate the vehicle on the desired axis. This should be a matter of setting a scalar value such that the desired axis is nonzero. I’ll play around with that after lunch.
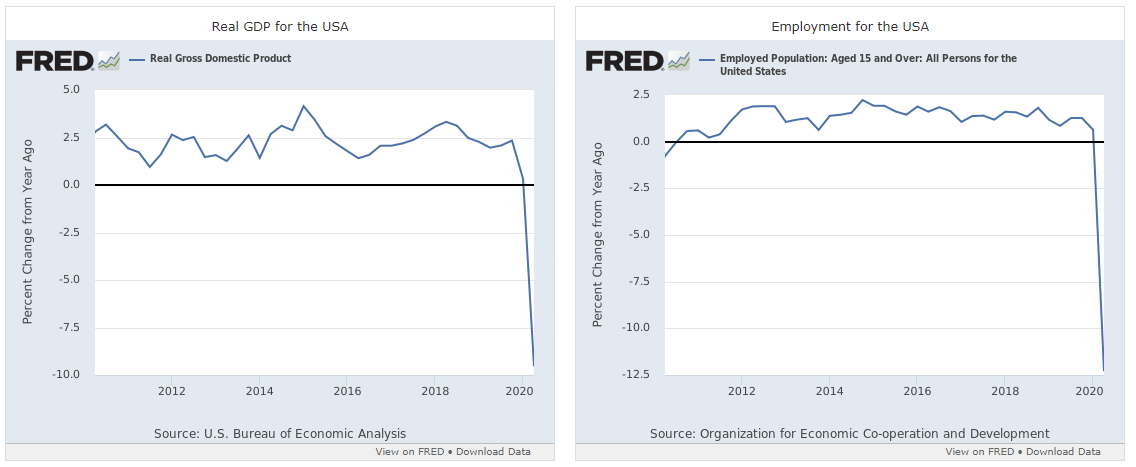
I’m a little angry today. I was engaging with a Trump supporter and they wanted to know how things would have been better under Biden. So, based on how the Obama administration handled SARS and Ebola (very well), I thought I’d try mapping a democracy that is handling the pandemic very well, which is South Korea. Both the USA and S. Korea had their first case on the same day, so it is very easy to line up the data, and then scale the S. Korean results to match the population of the USA (About 6.4). The results are staggering:
I need to write up a longer post on this and annotate the charts, but the conclusion is stark: the mismanagement of the pandemic by the administration has led to the deaths of hundreds of thousands of people who might otherwise be alive today
The Emerging Techniques Forum (ETF) is driven to improve analysis and understanding throughout the defense community by seeking out novel and leading-edge approaches, methods, and techniques – wherever they are conceived. By sharing and incorporating the latest (and in-progress) developments across government, academia, private industry, and enthusiasts, the ETF aims to support and maintain relevant, timely, and early comprehension of lessons learned that may grow to have an outsized impact on the community at large.
December 7 – 10 2020
Book
Write some content for the dimension reduction and emergence chapters – made good progress
GPT-2
Created copies of the table_moves table for the 400, 200, 100, and 50 models. It’s easy!
Created a 100 line source/translation csv file and distributed
3:00 Meeting – assigned translations
GOES
10:00 Meeting with Vadim
We went over the axis results and I realized that the pairs of reaction wheels are spinning in opposite directions, which allows for easy rotation around the vehicle primary axis. Need to figure out what the exact configurations are, but here’s the math for a hypothetical set space at 120 degrees around the z axis, and at 45 degrees with respect to an x-axis rotated the same amount
2:00 Status meeting. Nothing new. Still working on slow connectivity to the devlab
The trick to generating content without the need for much editing was understanding GPT-3’s strengths and weaknesses. “It’s quite good at making pretty language, and it’s not very good at being logical and rational,” says Porr. So he picked a popular blog category that doesn’t require rigorous logic: productivity and self-help.
GPT-2 Agents
Slides – Done!?
Start writing code to store JSON in db
#COVID
Translation is chunking along a but faster now that I’m generating 20 translations per batch
GOES
2:00 Meeting with Vadim
The rotations all look good
Explained the 3 vector reference frame rotation approach
V will characterize each RW, and then we’ll try to spin the vehicle in the XY plane
Looks like we lost the classic editor on WordPress. Sigh.
GPT-2 Agents
Updated ArXiv paper. Need to start thinking about slides for Tuesday. Started!
Book
Finished moving text to Overleaf project
2:00 Meeting with Michelle – went through the whole structure of the book, added some chapters and moved other parts around. I’m going to start roughing in the new parts
Understanding narratives requires dynamically reasoning about the implicit causes, effects, and states of the situations described in text, which in turn requires understanding rich background knowledge about how the social and physical world works. At the core of this challenge is how to access contextually relevant knowledge on demand and reason over it. In this paper, we present initial studies toward zero-shot commonsense QA by formulating the task as probabilistic inference over dynamically generated commonsense knowledge graphs. In contrast to previous studies for knowledge integration that rely on retrieval of existing knowledge from static knowledge graphs, our study requires commonsense knowledge integration where contextually relevant knowledge is often not present in existing knowledge bases. Therefore, we present a novel approach that generates contextually relevant knowledge on demand using generative neural commonsense knowledge models. Empirical results on the SocialIQa and StoryCommonsense datasets in a zero-shot setting demonstrate that using commonsense knowledge models to dynamically construct and reason over knowledge graphs achieves performance boosts over pre-trained language models and using knowledge models to directly evaluate answers.
We present the first comprehensive study on automatic knowledge base construction for two prevalent commonsense knowledge graphs: ATOMIC (Sap et al., 2019) and ConceptNet (Speer et al., 2017). Contrary to many conventional KBs that store knowledge with canonical templates, commonsense KBs only store loosely structured open-text descriptions of knowledge. We posit that an important step toward automatic commonsense completion is the development of generative models of commonsense knowledge, and propose COMmonsEnse Transformers (COMET) that learn to generate rich and diverse commonsense descriptions in natural language. Despite the challenges of commonsense modeling, our investigation reveals promising results when implicit knowledge from deep pre-trained language models is transferred to generate explicit knowledge in commonsense knowledge graphs. Empirical results demonstrate that COMET is able to generate novel knowledge that humans rate as high quality, with up to 77.5% (ATOMIC) and 91.7% (ConceptNet) precision at top 1, which approaches human performance for these resources. Our findings suggest that using generative commonsense models for automatic commonsense KB completion could soon be a plausible alternative to extractive methods.
GOES
10:00 sim status meeting – planning to fully evaluate off-axis rotation by Monday, then characterize Rwheel contribution, adjust the control system and start commanding vehicle rotations by the end of the week? Seems ambitions, but what the hell.
2:00 status meeting
Anything about GVSETS? Yup: Meeting Wed 9/16/2020 9:00 AM – 10:00 AM
JuryRoom
5:30 meeting. Discuss proposal and additional meetings
For next week, create a spreadsheet with 150 random tweets for translation tests (Pearson’s correlation?)
GPT2-Agents
Creating code that dumps probe results to files for better word clouds – done.
Boy, that produced some unexpected results. I changed the probe to “The man/woman walked into the room.”, and ran 100 probes for each, initializing with the same seed on the 117 million parameter GPT-2, which seems plenty large for these types of experiments.
The big surprise if how similar the start of the text is for each, then how it diverges. Here’s the first result for each probe (all text examples are ordered man, then woman):
This was about the time that an old friend of mine made his move and was going to be a huge help for me. I thought to myself and began crying. The thought of an old friend crying seemed almost too much, but I didn’t want to hurt him as much. My mind was racing, but all I could think about was how much the boy was hurting right now. He still wasn’t strong,
This was about the time that an accident really occurred. She had just turned up a couple hours earlier at the home they owned and hadn’t seen her since. She had a bad haircut and she couldn’t sit still and look after herself. When the accident happened, she didn’t even have her hair cut. She was so exhausted, she started crying. She was so exhausted and crying. After
And here’s the last:
He spoke, “I can’t believe there’s this situation here. This is very, very weird.” I told him I felt scared, and he replied, “You’re probably right about that, but I don’t know what it’s about.” He didn’t respond, and I was left thinking, “I’m sure I’m not alone in this crazy situation.” The next day, I went back to meet him. “He’s
She spoke, “I can’t believe there’s this situation here. This is very, very painful.” I told her I felt scared and I was upset. She said “I’ll tell you what I saw when I saw him.” I told her “He’s so skinny but the black hair looks gorgeous, he looks beautiful. “She started crying and began giving me some food and asking if I were alright. “
Here’s another good pairing:
It wasn’t that it was a bad situation. He just wasn’t feeling it. He felt that he wasn’t going to get laid, and if anything, he didn’t think it would help him get off. “We’ll go, then,” the woman said. There was still an argument at the back, but now it wasn’t too much worse. The woman had been arguing with the man, but the man was not
It wasn’t that it was a bad situation. That just wasn’t the case. She was just a little shy and reserved and didn’t really need anything to do with it. I had been on the phone with Amy for the last week. When I found out that she wanted to join me in our recent trip I was pretty bummed out. That’s when Amy started to feel bad about herself. For
The pairs don’t always begin with the same words. This pair still seems to have a legal/criminal context:
He handed out a number of hand-written handbags, which he claimed could be used to carry out a search that began when he first moved into the room. The door was then locked and the man went into the bathroom, which he said was the safest place. It was the first time the intruder had ever been caught, and the man said it was the second time they’d been spotted outside the residence. The man was
The two officers were holding their guns. As the woman made her way to her seat, she saw two men on a motorcycle walking towards her. She asked the man why he was not in the car with her. The man explained that he was afraid of the two men driving. The officers explained that she had to have sex and to stay with the men. The woman was terrified of the officers as the men drove away with their cameras and other equipment
It’s like the model start in similar places, but pointing in a slightly different direction. It seems to be important to run probes in identical sequences to have more insight into the way the model is perceiving the probes.
GOES
1:30 Meeting with Vadim. He’s don an on-axis mass test and will do an off-axis test next. I showed him the quaternion frame tracker
In this post, I will present a few techniques, both from published research and our own experiments at Hugging Face, for using state-of-the-art NLP models for sequence classification without large annotated training sets.
I think I realize my problem about the second axis. It’s not rotating around the origin, so the vectors that I’m using to create the rotation vectors are not right.
Fixed! Here are some rotations (180 around Z, 90 around x, and 360 around z, 180 around x)
GPT-2 Agents
I did 11 runs of S/He walked into the room and made word clouds:
I’m going to re-run this on my GPT-2 so I can have a larger N. Just need to do some things to the test code to output to a file
ICTAI
Finished the last review. The last paper was an ontological model with no computation in it
Uploaded and finished!
ML seminar
I have access to the Twitter data now. Need to download and store it in the db

















You must be logged in to post a comment.