I really need to get back to the book:

Also, make the D2Z trend based on the last 14 days this weekend. Done!

I really need to get back to the book:
Also, make the D2Z trend based on the last 14 days this weekend. Done!
The initial version of DaysToZero is up! Working on adding states now
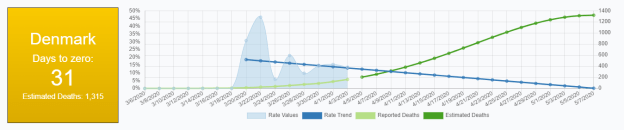
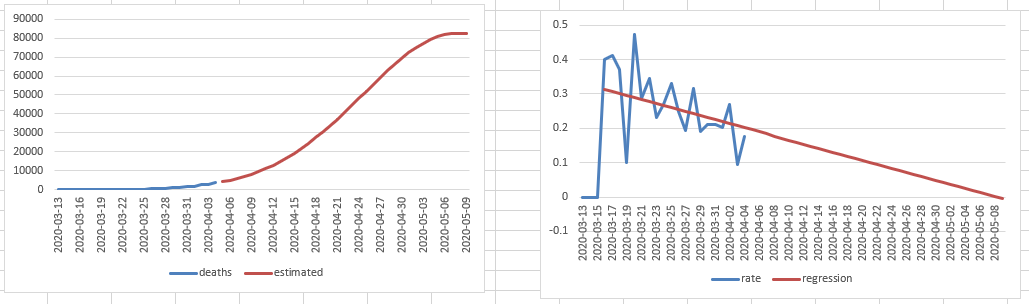
Got USA data working. New York looks very bad:
Evaluating the fake news problem at the scale of the information ecosystem
7:00 – 9:00 ASRC GOES
The brains of birds synchronize when they sing duets
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering

7:00 – 5:00 ASRC PhD
\def\changemargin#1#2{\list{}{\rightmargin#2\leftmargin#1}\item[]}
\let\endchangemargin=\endlist
\begin{changemargin}{1.5cm}{1.5cm}
They were one man, not thirty. For as the one ship that held them all; though it was put together of all contrasting things-oak, and maple, and pine wood; iron, and pitch, and hemp-yet all these ran into each other in the one concrete hull, which shot on its way, both balanced and directed by the long central keel; even so, all the individualities of the crew, this man’s valor, that man’s fear; guilt and guiltiness, all varieties were welded into oneness, and were all directed to that fatal goal which Ahab their one lord and keel did point to.
\end{changemargin}
ASRC PhD 6:30 – 9:30
7:00 – 5:00 ASRC
7:00 – 4:00 ASRC GOES
7:00 – 3:00 ASRC
3rd Annual DoD AI Industry Day
From Stewart Russell, via BBC Business Daily and the AI Alignment podcast:
Although people have argued that this creates a filter bubble or a little echo chamber where you only see stuff that you like and you don’t see anything outside of your comfort zone. That’s true. It might tend to cause your interests to become narrower, but actually that isn’t really what happened and that’s not what the algorithms are doing. The algorithms are not trying to show you the stuff you like. They’re trying to turn you into predictable clickers. They seem to have figured out that they can do that by gradually modifying your preferences and they can do that by feeding you material. That’s basically, if you think of a spectrum of preferences, it’s to one side or the other because they want to drive you to an extreme. At the extremes of the political spectrum or the ecological spectrum or whatever image you want to look at. You’re apparently a more predictable clicker and so they can monetize you more effectively.
So this is just a consequence of reinforcement learning algorithms that optimize click-through. And in retrospect, we now understand that optimizing click-through was a mistake. That was the wrong objective. But you know, it’s kind of too late and in fact it’s still going on and we can’t undo it. We can’t switch off these systems because there’s so tied in to our everyday lives and there’s so much economic incentive to keep them going.
So I want people in general to kind of understand what is the effect of operating these narrow optimizing systems that pursue these fixed and incorrect objectives. The effect of those on our world is already pretty big. Some people argue that operation’s pursuing the maximization of profit have the same property. They’re kind of like AI systems. They’re kind of super intelligent because they think over long time scales, they have massive information, resources and so on. They happen to have human components, but when you put a couple of hundred thousand humans together into one of these corporations, they kind of have this super intelligent understanding, manipulation capabilities and so on.

Capacity, Bandwidth, and Compositionality in Emergent Language Learning
7:00 – ASRC GOES

The dynamics of norm change in the cultural evolution of language
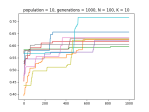
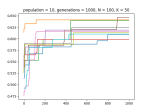
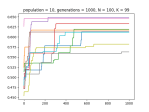
When Hillclimbers Beat Genetic Algorithms in Multimodal Optimization
7:00 – 4:00 ASRC GOES
7:00 – 4:30 ASRC GEOS


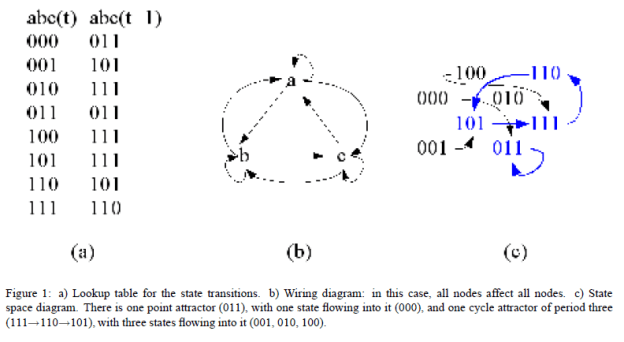
7:00 – 6:30ASRC GEOS
Phil 7:00 – 5:00 ASRC NASA GEOS

You must be logged in to post a comment.