
8:00 – 4:00 ASRC
- Got my dissertation paperwork in!
- To Persuade As an Expert, Order Matters: ‘Information First, then Opinion’ for Effective Communication
- Participants whose stated preference was to follow the doctor’s opinion had significantly lower rates of antibiotic requests when given “information first, then opinion” compared to “opinion first, then information.” Our evidence suggests that “information first, then opinion” is the most effective approach. We hypothesize that this is because it is seen by non-experts as more trustworthy and more respectful of their autonomy.
- This matters a lot because what is presented and the order of presentation is itself, an opinion. Maps lay out the information in a way that provides a larger, less edited selection of information.
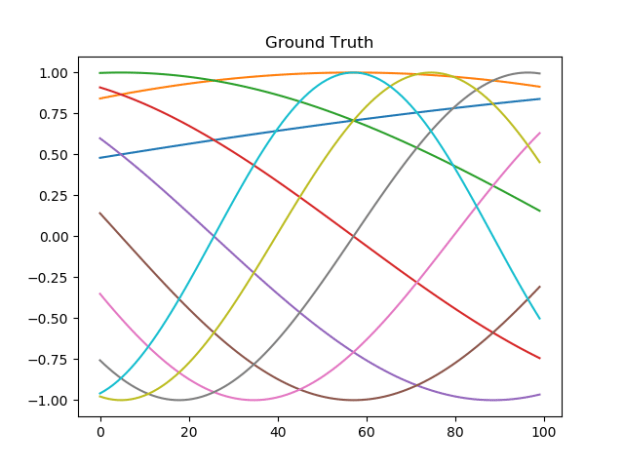
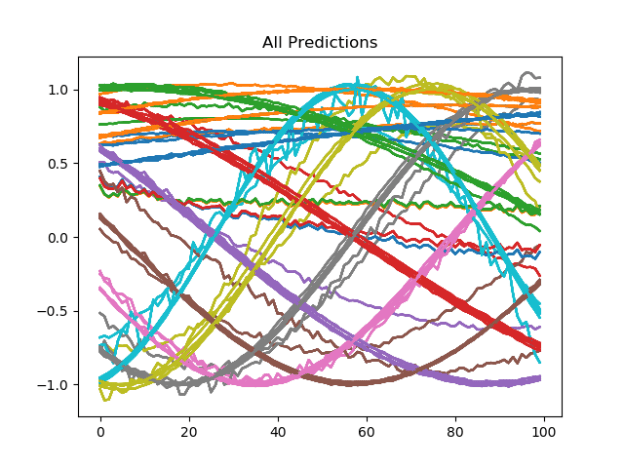
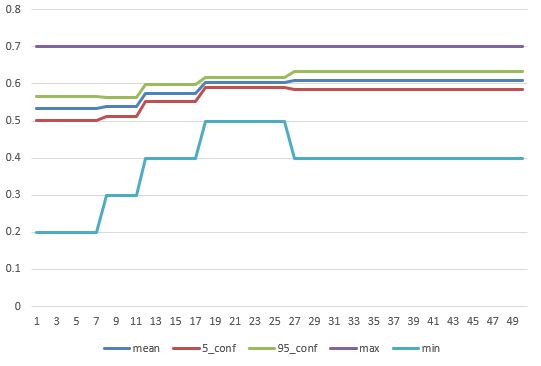
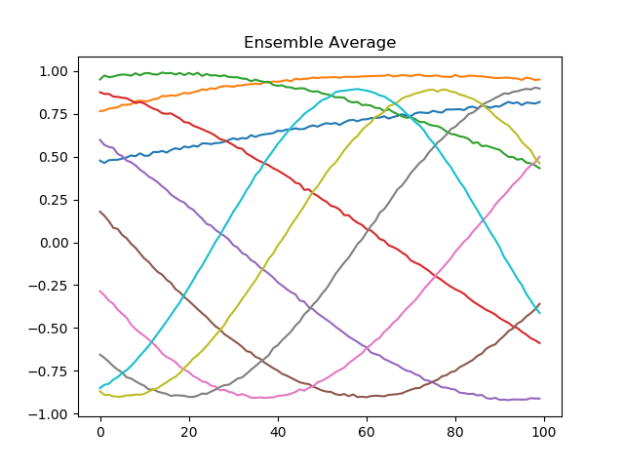
- Working on RW training set. Got the framework methods working. Here’s a particularly good run – 99% accuracy for 50 “functions” repeated 20 times each:


- Tomorrow I’ll roll them into the optomizer. I’ve already built the subclass, but had to flail a bit to find the right way to structure and scale the data












You must be logged in to post a comment.