Looks like I’ll need to add XBB.1.5 and XBB15 to the pull list


I wrote a new blog post! Some thoughts on the ChatGPT
Really not feeling motivated. It’s been raining for 36 hours or so, and then it’s going to get cold. By Tuesday, things should be getting back to seasonal, and then even a little nice by Friday
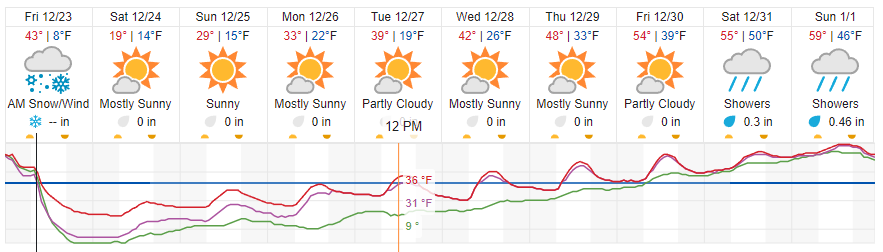
SBIRs
The days are (marginally) getting longer
Book
SBIRs
GPT Agents
Shortest day of the year! It gets better from here
Book
SBIRs
import pandas as pd
from random import random
from pathlib import Path
from typing import List
class FindLowest:
size:int
num_items:int
rows:int
input_matrix:List
output_matrix:List
def __init__(self, num_items, size:int, rows:int = 100):
self.num_items = num_items
self.size = size
self.rows = rows
def int_to_bin_list(self, val:int, places:int = 16) -> List:
l = []
for i in range(places):
b = int(val & 1 << i != 0)
l.append(b)
return l
def calc_data(self, bin_list_len:int = 4):
row = 0
self.input_matrix = []
self.output_matrix = []
for r in range(self.rows):
i = r % self.num_items
d = {}
#d['id'] = i
for j in range(self.size):
d[j] = random()
sd = dict(sorted(d.items(), key=lambda item: item[1]))
#print("{}, {}".format(sd.keys(), d.values()))
best_choice = list(sd.keys())[i]
bc_list = self.int_to_bin_list(best_choice, bin_list_len)
id_list = self.int_to_bin_list(i, bin_list_len)
input_d = {}
output_d = {}
for i in range(bin_list_len):
input_d["b{}".format(i)] = id_list[i]
output_d["b{}".format(i)] = bc_list[i]
input_d.update(d)
#print("row {}: id = {}, inout = {}, output = {}".format(row, id_list.reverse(), d, bc_list.reverse()))
print("row {}: input_d = {}, output_d = {}".format(row, input_d, output_d))
self.input_matrix.append(input_d)
self.output_matrix.append(output_d)
row += 1
def to_csv(self, prefix:str, directory:str = None):
if directory == None:
directory = str(Path.home())
df = pd.DataFrame(self.input_matrix)
filename = "{}/{}_input.csv".format(directory, prefix)
print("saving {}".format(filename))
df.to_csv(filename, index=False)
df = pd.DataFrame(self.output_matrix)
filename = "{}/{}_output.csv".format(directory, prefix)
print("saving {}".format(filename))
df.to_csv(filename, index=False)
def main():
fl = FindLowest(5, 10)
fl.calc_data()
fl.to_csv("test")
if __name__ == "__main__":
main()
GPT Agents
Agreed to go on this podcast – should be interesting
Elixir: Train a Large Language Model on a Small GPU Cluster
I think the ChatGPT article should be on teaching critical thinking with large language models
Book
SBIRs
Book
SBIRs

Mastodon new users
Developer platforms are all about trust, and Twitter lost it
Twitter is banning journalists and links to Mastodon instances. I did discover that you can follow a particular instance, which is very nice, but not supported in the API. All you have to do though is create a browser tab for the local timeline for that instance. For example
I need to code up a web page that can do that in a tweetdeck format and handle replies from your particular account. I think that it should be pretty easy. Something for January. Regardless, here’s the basics of accessing any instance timeline:
import json
import requests
# A playground for exploring the Mastodon REST interface (https://docs.joinmastodon.org/client/public/)
# Mastodon API: https://docs.joinmastodon.org/api/
# Mastodon client getting started with the API: https://docs.joinmastodon.org/client/intro/
def create_timeline_url(instance:str = "mastodon.social", limit:int=10):
url = "https://{}/api/v1/timelines/public?limit={}".format(instance, limit)
print("create_timeline_url(): {}".format(url))
return url
def connect_to_endpoint(url) -> json:
response = requests.request("GET", url)
print("Status code = : {}".format(response.status_code))
if response.status_code != 200:
raise Exception(
"Request returned an error: {} {}".format(
response.status_code, response.text
)
)
return response.json()
def print_response(title:str, j:json):
json_str = json.dumps(j, indent=4, sort_keys=True)
print("\n------------ Begin '{}':\nresponse:\n{}\n------------ End '{}'\n".format(title, json_str, title))
def main():
print("post_lookup")
instance_list = ["fediscience.org", "sigmoid.social"]
for instance in instance_list:
url = create_timeline_url(instance, 1)
rsp = connect_to_endpoint(url)
print_response("{} test:".format(instance), rsp)
if __name__ == "__main__":
main()
Book
SBIRs
GPT Agents

Bookend for the day


This is what I mean when I talk about the power of social communication vs monolithic models. The idea of using models to generate IP-protected work moved quickly through the artist community, while the process of producing models that won’t generate these images will be harder. Either the models have to be re-trained or filtered.
Book
GPT Agents

SBIRs
Book
SBIR

GPT Agents
7:00 Meet Brian at Sapwood
Decided not to go ahead with the counter “Student Essay is Dead” since I’m not really getting meaningful traction for a positive spin
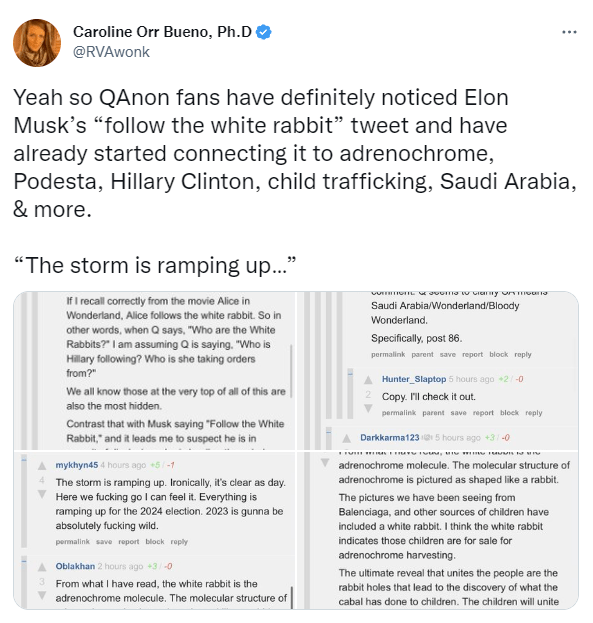
When Freedom Meant the Freedom to Oppress Others
GPT Agents
SBIRs
Book
I uploaded a model to HuggingFace this weekend!
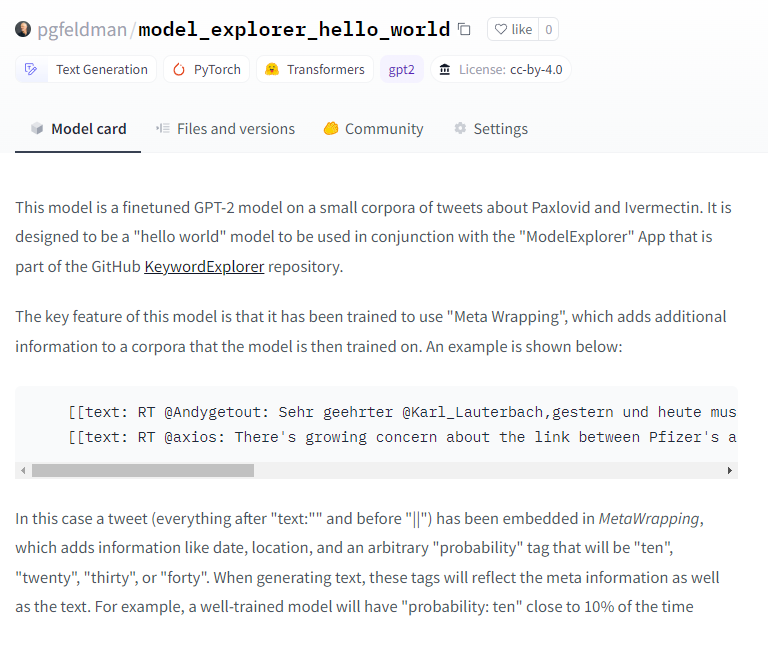
Also lots of chatting about the new GPT chatbot and what it means for education. Particularly this article from the Atlantic. My response:
GPT Agents
SBIRs
Book
Had some wild interactions with the new GPTChatbot generating ivermectin claims. Also, the new GPT is much more succinct.
Finished review!
GPT Agents

SBIRs
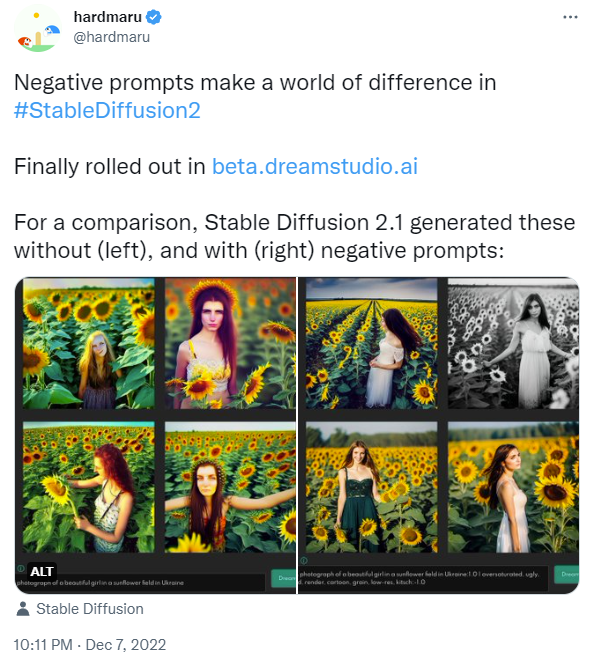

Write review of steganography paper
Does LaTeX work here? Here’s an equation: 
Here’s an enumeration? 
SBIRs
GPT Agents
Haven’t posted about BBC business daily, but this is a good one: What’s happened to the titans of big tech?
SBIRs
GPT Agents
🤗/Transformers implementation of RoBERTa. Enter some text in the text box; the predicted probabilities will be displayed below. The results start to get reliable after around 50 tokens.
Book
GPT Agents
SBIRs

You must be logged in to post a comment.