
7:00 – 3:00 ASRC NASA
- Started Second Person, and learned about GURPS
- Added a section on navigating belief places and spaces to the dissertation
- It looks like I’m doing Computational Discourse Analysis, which has more to do with how the words in a discussion shift over time. Requested this chapter through ILL
- Looking at Cornell Conversational Analysis Toolkit
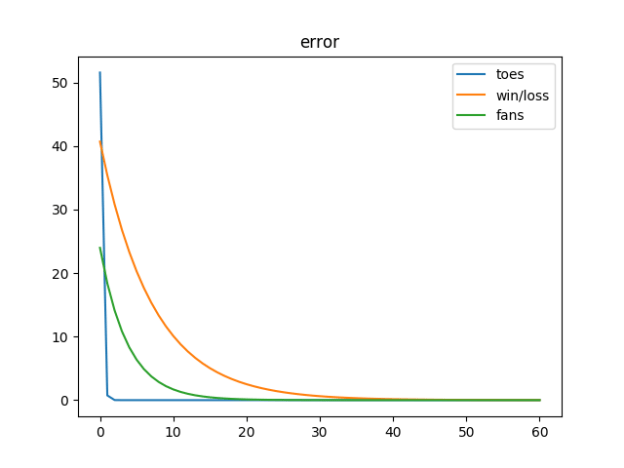
- More Grokking today so I don’t lose too much focus on understanding NNs
-
-
- Important numpy rules:
import numpy as np val = np.array([[0.6]]) row = np.array([[-0.59, 0.75, -0.94,0.34 ]]) col = np.array([[-0.59], [ 0.75], [-0.94], [ 0.34]]) print ("np.dot({}, {}) = {}".format(val, row, np.dot(val, row))) print ("np.dot({}, {}) = {}".format(col, val, np.dot(col, val))) ''' note the very different results: np.dot([[0.6]], [[-0.59 0.75 -0.94 0.34]]) = [[-0.354 0.45 -0.564 0.204]] np.dot([[-0.59], [ 0.75], [-0.94], [ 0.34]], [[0.6]]) = [[-0.354], [ 0.45 ], [-0.564], [ 0.204]] ''' - So here’s the tricky bit that I don’t get yet
# Multiply the values of the relu'd layer [[0, 0.517, 0, 0]] by the goal-output_layer [.61] weight_mat = np.dot(layer_1_col_array, layer_1_to_output_delta) # e.g. [[0], [0.31], [0], [0]] weights_layer_1_to_output_col_array += alpha * weight_mat # add the scaled deltas in # Multiply the streetlights [[1], [0], [1] times the relu2deriv'd input_to_layer_1_delta [[0, 0.45, 0, 0]] weight_mat = np.dot(input_layer_col_array, input_to_layer_1_delta) # e.g. [[0, 0.45, 0, 0], [0, 0, 0, 0], [0, 0.45, 0, 0]] weights_input_to_layer_1_array += alpha * weight_mat # add the scaled deltas in
- It looks to me that as we work back from the output layer, we multiply our layer’s weights by the manipulated (relu in this case) for the last layer, and the derivative in the next layer forward? I know that we are working out how to distribute the adjustment of the weights via something like the chain rule…
- Important numpy rules:
-
-











You must be logged in to post a comment.