

Sharpened Cosine Similarity (CosSim) is an alternative to Convolution for building features in neural networks. It performs as well as ConvNets with 10x-100x more parameters.
Current Stereotypes: A Little Fading, a Little Faking
- Examined the possibility that social-desirability-tainted responses emerge in the study of stereotypes. 60 white male undergraduates were randomly assigned to 1 of 4 experimental conditions. Ss were asked to indicate how characteristic each of 22 adjective traits was of either “Americans” or “Negroes.” 1/2 the Ss responded in a rating situation in which they were presumably free to distort their responses. The remaining Ss responded under “bogus pipeline” conditions; i.e., they were led to believe that the experimenter had an accurate, distortion-free physiological measure of their attitudes, and were asked to predict that measure. Results support the expectation that the stereotype ascribed to Negroes would be more favorable under rating than under bogus pipeline conditions. Americans were more favorably stereotyped under bogus pipeline than under rating conditions. A number of explanations for these results are discussed, and consideration is given to the relationship between verbally expressed attitudes and other, overt, behavior.
- Recent decades have seen a rise in the use of physics methods to study different societal phenomena. This development has been due to physicists venturing outside of their traditional domains of interest, but also due to scientists from other disciplines taking from physics the methods that have proven so successful throughout the 19th and the 20th century. Here we characterise the field with the term ‘social physics’ and pay our respect to intellectual mavericks who nurtured it to maturity. We do so by reviewing the current state of the art. Starting with a set of topics that are at the heart of modern human societies, we review research dedicated to urban development and traffic, the functioning of financial markets, cooperation as the basis for our evolutionary success, the structure of social networks, and the integration of intelligent machines into these networks. We then shift our attention to a set of topics that explore potential threats to society. These include criminal behaviour, large-scale migration, epidemics, environmental challenges, and climate change. We end the coverage of each topic with promising directions for future research. Based on this, we conclude that the future for social physics is bright. Physicists studying societal phenomena are no longer a curiosity, but rather a force to be reckoned with. Notwithstanding, it remains of the utmost importance that we continue to foster constructive dialogue and mutual respect at the interfaces of different scientific disciplines.
This is really clever: How does fake news spread? Understanding pathways of disinformation spread through APIs
- What are the pathways for spreading disinformation on social media platforms? This article addresses this question by collecting, categorizing, and situating an extensive body of research on how application programming interfaces (APIs) provided by social media platforms facilitate the spread of disinformation. We first examine the landscape of official social media APIs, then perform quantitative research on the open‐source code repositories GitHub and GitLab to understand the usage patterns of these APIs. By inspecting the code repositories, we classify developers’ usage of the APIs as official and unofficial, and further develop a four‐stage framework characterizing pathways for spreading disinformation on social media platforms. We further highlight how the stages in the framework were activated during the 2016 US Presidential Elections, before providing policy re-commendations for issues relating to access to APIs, algorithmic content, advertisements, and suggest rapid response to coordinate campaigns, development of collaborative, and participatory approaches as well as government stewardship in the regulation of social media platforms.
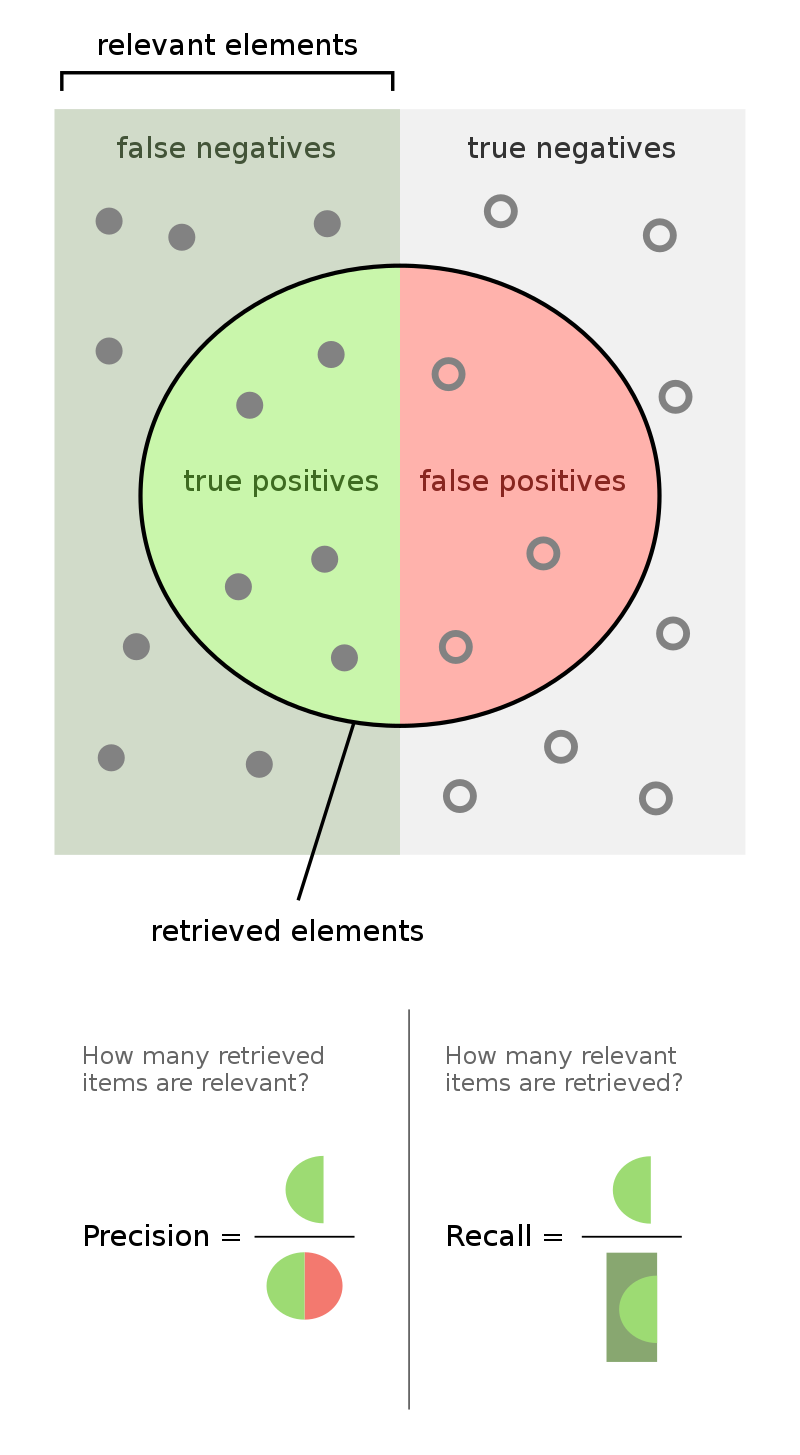
The Wikipedia folks have produced a very clear Precision/Recall diagram!
SBIRs
- Slides for demo
- 9:00 Demos
- 2:00 Meeting with Rukan
- Natural Language Processing with Transformers Book
- Train transformers from scratch and learn how to scale to multiple GPUs and distributed environments
Book
- More work on intro
GPT Agents
- Work on Twitter queries














You must be logged in to post a comment.