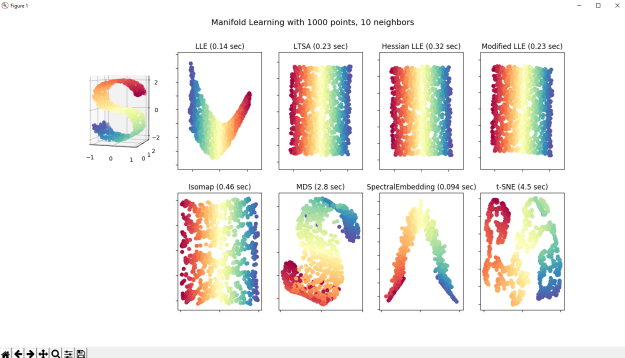
Finishing up temporal coherence in clustering. Getting differences, now I have to figure out how to sort, and when to make a new cluster.
timestamp = 10.07
t=10.07, id=0, members = ['ExploitSh_54', 'ExploitSh_65', 'ExploitSh_94', 'ExploreSh_0', 'ExploreSh_1', 'ExploreSh_17', 'ExploreSh_2', 'ExploreSh_21', 'ExploreSh_24', 'ExploreSh_29', 'ExploreSh_3', 'ExploreSh_35', 'ExploreSh_38', 'ExploreSh_4', 'ExploreSh_40', 'ExploreSh_43', 'ExploreSh_48', 'ExploreSh_49', 'ExploreSh_8']
t=10.07, id=1, members = ['ExploitSh_50', 'ExploitSh_51', 'ExploitSh_52', 'ExploitSh_53', 'ExploitSh_55', 'ExploitSh_56', 'ExploitSh_57', 'ExploitSh_58', 'ExploitSh_59', 'ExploitSh_60', 'ExploitSh_61', 'ExploitSh_62', 'ExploitSh_64', 'ExploitSh_66', 'ExploitSh_67', 'ExploitSh_69', 'ExploitSh_70', 'ExploitSh_71', 'ExploitSh_72', 'ExploitSh_73', 'ExploitSh_74', 'ExploitSh_75', 'ExploitSh_76', 'ExploitSh_77', 'ExploitSh_78', 'ExploitSh_79', 'ExploitSh_80', 'ExploitSh_81', 'ExploitSh_82', 'ExploitSh_83', 'ExploitSh_84', 'ExploitSh_85', 'ExploitSh_87', 'ExploitSh_88', 'ExploitSh_89', 'ExploitSh_90', 'ExploitSh_91', 'ExploitSh_92', 'ExploitSh_93', 'ExploitSh_95', 'ExploitSh_96', 'ExploitSh_97', 'ExploitSh_99', 'ExploreSh_10', 'ExploreSh_11', 'ExploreSh_13', 'ExploreSh_14', 'ExploreSh_15', 'ExploreSh_16', 'ExploreSh_18', 'ExploreSh_19', 'ExploreSh_20', 'ExploreSh_23', 'ExploreSh_25', 'ExploreSh_26', 'ExploreSh_27', 'ExploreSh_28', 'ExploreSh_30', 'ExploreSh_31', 'ExploreSh_32', 'ExploreSh_33', 'ExploreSh_34', 'ExploreSh_36', 'ExploreSh_37', 'ExploreSh_41', 'ExploreSh_42', 'ExploreSh_45', 'ExploreSh_46', 'ExploreSh_47', 'ExploreSh_5', 'ExploreSh_7', 'ExploreSh_9']
t=10.07, id=-1, members = ['ExploitSh_63', 'ExploitSh_68', 'ExploitSh_86', 'ExploitSh_98', 'ExploreSh_12', 'ExploreSh_22', 'ExploreSh_39', 'ExploreSh_44', 'ExploreSh_6']
timestamp = 10.18
t=10.18, id=0, members = ['ExploitSh_50', 'ExploitSh_51', 'ExploitSh_52', 'ExploitSh_53', 'ExploitSh_55', 'ExploitSh_56', 'ExploitSh_57', 'ExploitSh_58', 'ExploitSh_59', 'ExploitSh_60', 'ExploitSh_61', 'ExploitSh_62', 'ExploitSh_63', 'ExploitSh_64', 'ExploitSh_65', 'ExploitSh_66', 'ExploitSh_67', 'ExploitSh_69', 'ExploitSh_70', 'ExploitSh_71', 'ExploitSh_72', 'ExploitSh_73', 'ExploitSh_74', 'ExploitSh_75', 'ExploitSh_76', 'ExploitSh_77', 'ExploitSh_78', 'ExploitSh_79', 'ExploitSh_80', 'ExploitSh_81', 'ExploitSh_82', 'ExploitSh_83', 'ExploitSh_84', 'ExploitSh_85', 'ExploitSh_86', 'ExploitSh_87', 'ExploitSh_88', 'ExploitSh_89', 'ExploitSh_90', 'ExploitSh_91', 'ExploitSh_92', 'ExploitSh_93', 'ExploitSh_94', 'ExploitSh_95', 'ExploitSh_96', 'ExploitSh_97', 'ExploitSh_99', 'ExploreSh_0', 'ExploreSh_1', 'ExploreSh_10', 'ExploreSh_11', 'ExploreSh_13', 'ExploreSh_14', 'ExploreSh_15', 'ExploreSh_16', 'ExploreSh_17', 'ExploreSh_18', 'ExploreSh_19', 'ExploreSh_2', 'ExploreSh_20', 'ExploreSh_21', 'ExploreSh_23', 'ExploreSh_24', 'ExploreSh_25', 'ExploreSh_26', 'ExploreSh_27', 'ExploreSh_28', 'ExploreSh_29', 'ExploreSh_3', 'ExploreSh_30', 'ExploreSh_31', 'ExploreSh_32', 'ExploreSh_33', 'ExploreSh_34', 'ExploreSh_35', 'ExploreSh_36', 'ExploreSh_37', 'ExploreSh_38', 'ExploreSh_4', 'ExploreSh_40', 'ExploreSh_41', 'ExploreSh_42', 'ExploreSh_43', 'ExploreSh_45', 'ExploreSh_46', 'ExploreSh_47', 'ExploreSh_48', 'ExploreSh_49', 'ExploreSh_5', 'ExploreSh_7', 'ExploreSh_8', 'ExploreSh_9']
t=10.18, id=-1, members = ['ExploitSh_54', 'ExploitSh_68', 'ExploitSh_98', 'ExploreSh_12', 'ExploreSh_22', 'ExploreSh_39', 'ExploreSh_44', 'ExploreSh_6']
current[0] 32.43% similar to previous[0]
current[0] 87.80% similar to previous[1]
current[0] 3.96% similar to previous[-1]
current[-1] 7.41% similar to previous[0]
current[-1] 82.35% similar to previous[-1]
In the above example, we originally have 3 clusters and then 2. The two that map are pretty straightforward: current[0] 87.80% similar to previous[1], and current[-1] 82.35% similar to previous[-1]. Not sure what to do about the group that fell away. I think there should be an increasing ID number for clusters, with the exception of [-1], which is unclustered. Once a cluster goes away, it can’t come back.

 Republicans registered the biggest uptick in support for the deal, which has been heavily criticized by GOP lawmakers since its inception in July 2015: 53 percent of Republican voters said they supported it, compared with 37 percent who backed it last summer and just 10 percent who supported it shortly after it was announced. Democratic support for the deal has been largely unchanged since August, and a larger share of independents are getting on board, from 41 percent in August to 48 percent now.
Republicans registered the biggest uptick in support for the deal, which has been heavily criticized by GOP lawmakers since its inception in July 2015: 53 percent of Republican voters said they supported it, compared with 37 percent who backed it last summer and just 10 percent who supported it shortly after it was announced. Democratic support for the deal has been largely unchanged since August, and a larger share of independents are getting on board, from 41 percent in August to 48 percent now.




You must be logged in to post a comment.