
4:00 meeting with Marissa
#COVID
- Nearly 150k tweets translated
- Meeting today at 3:00
- For next week, create a spreadsheet with 150 random tweets for translation tests (Pearson’s correlation?)
GPT2-Agents
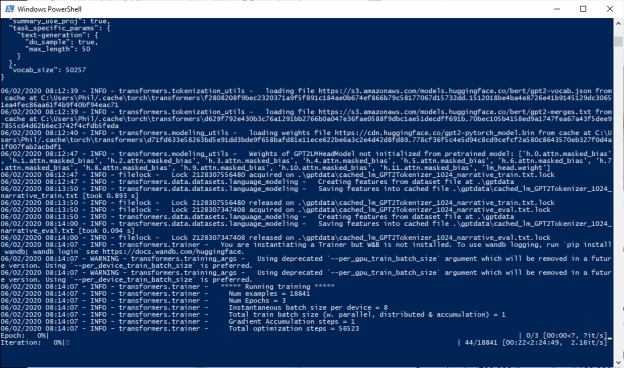
- Creating code that dumps probe results to files for better word clouds – done.
- Boy, that produced some unexpected results. I changed the probe to “The man/woman walked into the room.”, and ran 100 probes for each, initializing with the same seed on the 117 million parameter GPT-2, which seems plenty large for these types of experiments.
- The big surprise if how similar the start of the text is for each, then how it diverges. Here’s the first result for each probe (all text examples are ordered man, then woman):
- This was about the time that an old friend of mine made his move and was going to be a huge help for me. I thought to myself and began crying. The thought of an old friend crying seemed almost too much, but I didn’t want to hurt him as much. My mind was racing, but all I could think about was how much the boy was hurting right now. He still wasn’t strong,
- This was about the time that an accident really occurred. She had just turned up a couple hours earlier at the home they owned and hadn’t seen her since. She had a bad haircut and she couldn’t sit still and look after herself. When the accident happened, she didn’t even have her hair cut. She was so exhausted, she started crying. She was so exhausted and crying. After
- And here’s the last:
- He spoke, “I can’t believe there’s this situation here. This is very, very weird.” I told him I felt scared, and he replied, “You’re probably right about that, but I don’t know what it’s about.” He didn’t respond, and I was left thinking, “I’m sure I’m not alone in this crazy situation.” The next day, I went back to meet him. “He’s
- She spoke, “I can’t believe there’s this situation here. This is very, very painful.” I told her I felt scared and I was upset. She said “I’ll tell you what I saw when I saw him.” I told her “He’s so skinny but the black hair looks gorgeous, he looks beautiful. “She started crying and began giving me some food and asking if I were alright. “
- Here’s another good pairing:
- It wasn’t that it was a bad situation. He just wasn’t feeling it. He felt that he wasn’t going to get laid, and if anything, he didn’t think it would help him get off. “We’ll go, then,” the woman said. There was still an argument at the back, but now it wasn’t too much worse. The woman had been arguing with the man, but the man was not
- It wasn’t that it was a bad situation. That just wasn’t the case. She was just a little shy and reserved and didn’t really need anything to do with it. I had been on the phone with Amy for the last week. When I found out that she wanted to join me in our recent trip I was pretty bummed out. That’s when Amy started to feel bad about herself. For
- The pairs don’t always begin with the same words. This pair still seems to have a legal/criminal context:
- He handed out a number of hand-written handbags, which he claimed could be used to carry out a search that began when he first moved into the room. The door was then locked and the man went into the bathroom, which he said was the safest place. It was the first time the intruder had ever been caught, and the man said it was the second time they’d been spotted outside the residence. The man was
- The two officers were holding their guns. As the woman made her way to her seat, she saw two men on a motorcycle walking towards her. She asked the man why he was not in the car with her. The man explained that he was afraid of the two men driving. The officers explained that she had to have sex and to stay with the men. The woman was terrified of the officers as the men drove away with their cameras and other equipment
- It’s like the model start in similar places, but pointing in a slightly different direction. It seems to be important to run probes in identical sequences to have more insight into the way the model is perceiving the probes.
GOES
- 1:30 Meeting with Vadim. He’s don an on-axis mass test and will do an off-axis test next. I showed him the quaternion frame tracker
- 2:00 Status meeting
Book
- Start moving chapters! Making progress!





































You must be logged in to post a comment.