
Discovered State Azure, which is some very nice chill music
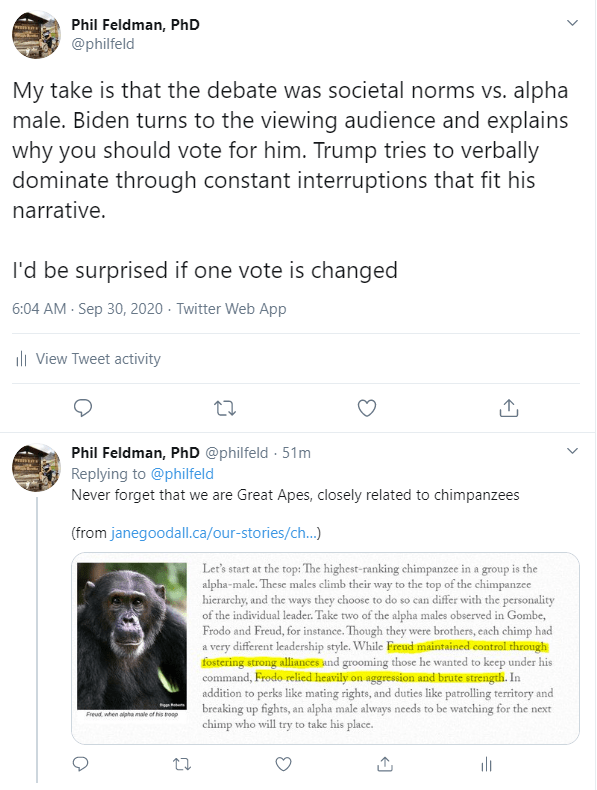
My thoughts on the debate last night:
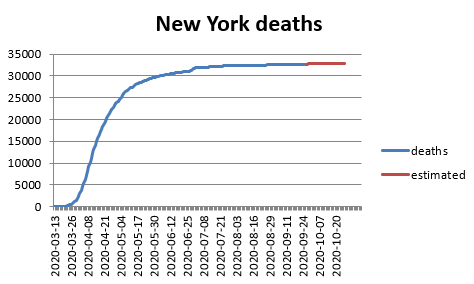
#COVID
- Creating a list of distinct content that translated to “elderman”. Going to see if I can get the Google Translate API to deal with these problem children
- Installing the python libraries for google translate
- Because I love pain, upgraded tensorflow. Let’s see if anything still works! It does! At least for translation and GPT, which is good enough for me at the moment
- Working on getting the translate API running
GPT-2 Agents
- The paper’s submitted!
- Had a good chat with Shimei and Sim last night. The db has been uploaded, and we talked about next steps. I also showed how to install the Huggingface transformers library from source. That involved uninstalling the Typing library for some reason. Seems there are conflicts?
GOES
- 10:00 Meeting with Vadim & Erik
- 2:00 Status report











You must be logged in to post a comment.