
7:00 – 5:00 ASRC MKT
- Sent out copies of the draft to academic/work management. Waiting for comments
- Fix concepts
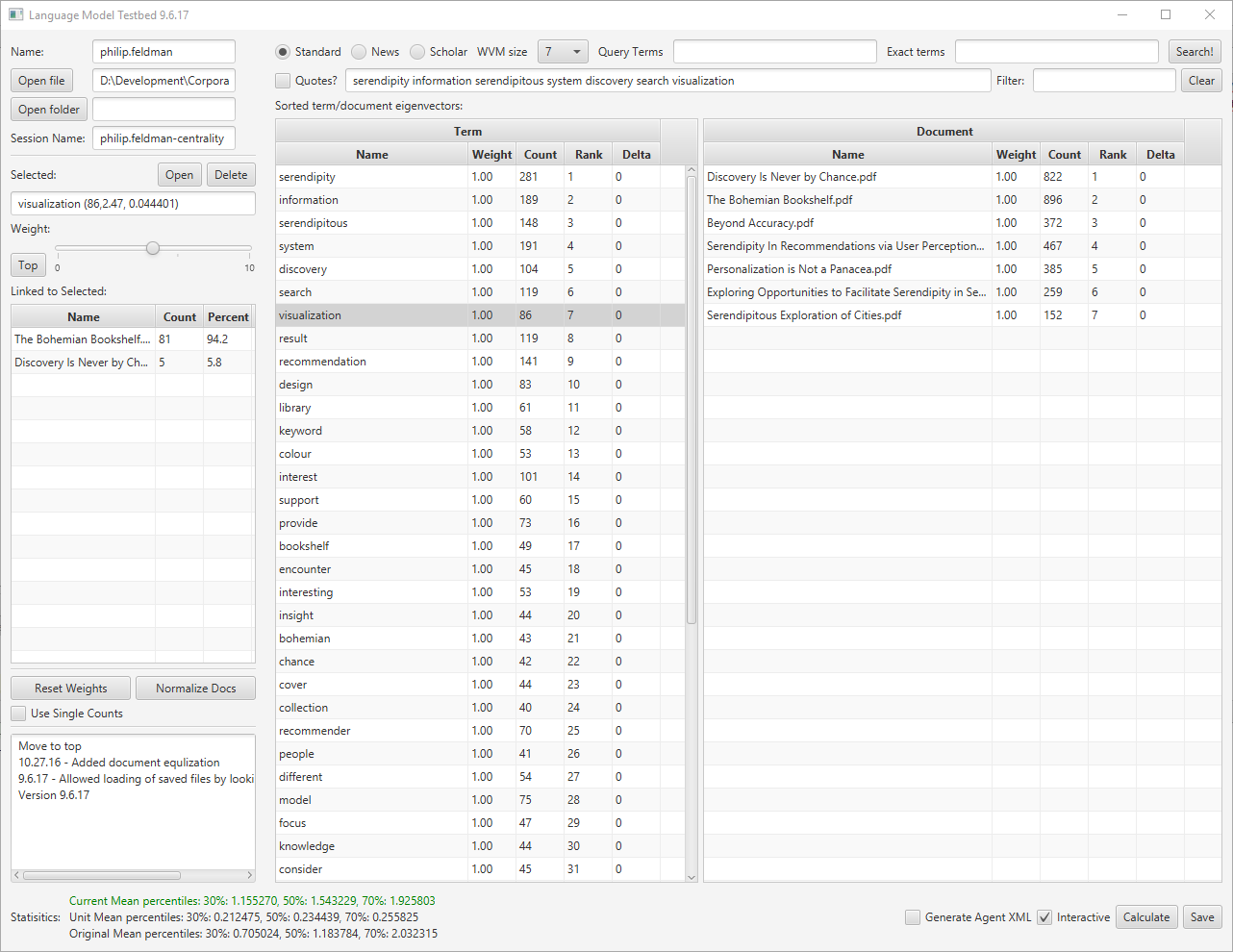
- Fix Keywords – going to try the LMN on the lit review and see what pops up

- Raw: platform model market dependence network effect simulation smartphone technology (Scholar search on these terms)
- Normalized: group information model study between social system individual change (Scholar search on these terms)
- Normalized is much better.
- Get page numbers
- Register for easychair, and make sure what the actual deadline is. Registered, but there is no date information WRT the submission. Going to submit Saturday night out of an abundance of caution.
- I had some more thoughts about how behavior patterns emerge from the interplay between trust and awareness. I think the following may be true:
- Healthy behaviors emerge when trust and awareness are equivalent.
- Low trust and low awareness is reasonable. It’s like walking through a dark, unknown space. You go slow, bump into things, and adjust.
- Low trust and high awareness is paralytic.
- High trust and low awareness is reckless. Runaway conditions like echo chambers.
- Diversity is a mechanism for extending awareness, but it depends on trusting those who are different. That may be the essence of the explore/exploit dilemma.
- In a healthy group context, trust falls off as a function of awareness. That’s why we get flocking. That is the pattern that emerges when you trust more those who are close, while they in turn do the same, building a web of interaction. It’s kind of like interacting ripples?
- This may work for any collection of entities that have varied states that undergo change in some predictable way. If they were completely random, then awareness of the state is impossible, and trust should be zero.
- Human agent trust chains might proceed from self to family to friends to community, etc.
- Machine agent trust chains might proceed from self to direct connections (thumb drives, etc) to LAN/WAN to WAN
- Genetic agent trust chain is short – self to species. Contact is only for reproduction. Interaction would reflect the very long sampling times.
- Note that (1) is evolved and is based on incremental and repeated interactions, while (2) is designed and is based on arbitrary rules that can change rapidly. Genetics are maybe dealing with different incentives? The only issue is persisting and spreading (which helps in the persisting)
- Computer-mediated-communication disturbs this process (as does probably every form of mass communication) because the trust in the system is applied to the trust of the content. This can work in both ways. For example, lowering trust in the press allows for claims of Fake News. Raising the trust of social networks that channel anonymous online sources allows for conspiracy thinking.
- An emerging risk is how this affects artificial intelligence, given that currently high trust in the algorithms and training sets is assumed by the builders
- Low numbers of training sets mean low diversity/awareness,
- Low numbers of algorithms (DNNs) also mean low diversity/awareness
- Since training/learning is spread by update, the installed base is essentially multiple instances of the same individual. So no diversity and very high trust. That’s a recipe for a stampede of 10,000 self driving cars.



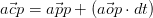
 SocInfo2017
SocInfo2017 


You must be logged in to post a comment.