7:00 – 4:30 ASRC PhD/NASA
- Sent Greg a couple of quick notes on using CNNs to match bacteria to phages.
- Continuing with Normal Accidents
- A Digital Test of the News: Checking the Web for Public Facts – Workshop report, December 2018
- The Digital Test of the News workshop brought together digital sociologists, data visualisation and new media researchers at the Centre for Interdisciplinary Methodologies at the University of Warwick on 8 and 9 May 2018. The workshop is part of a broader research collaboration between the Centre for Interdisciplinary Methodologies and the Public Data Lab which investigates the changing nature of public knowledge formation in digital societies and develops inventive methods to capture and visualise knowledge dynamics online. Below we outline the workshop’s aims and outcomes.
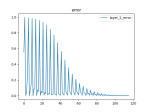
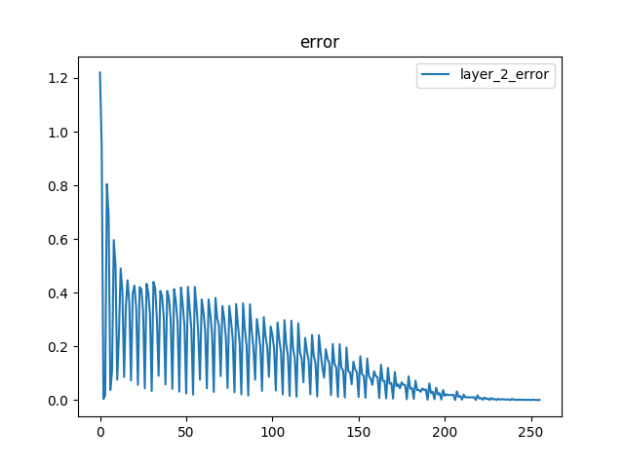
- Added plots to the NN code. Everything seems to look right. Looking at the individual weights in a layer is very informative. Need to add this kind of plotting to our keras code somehow:
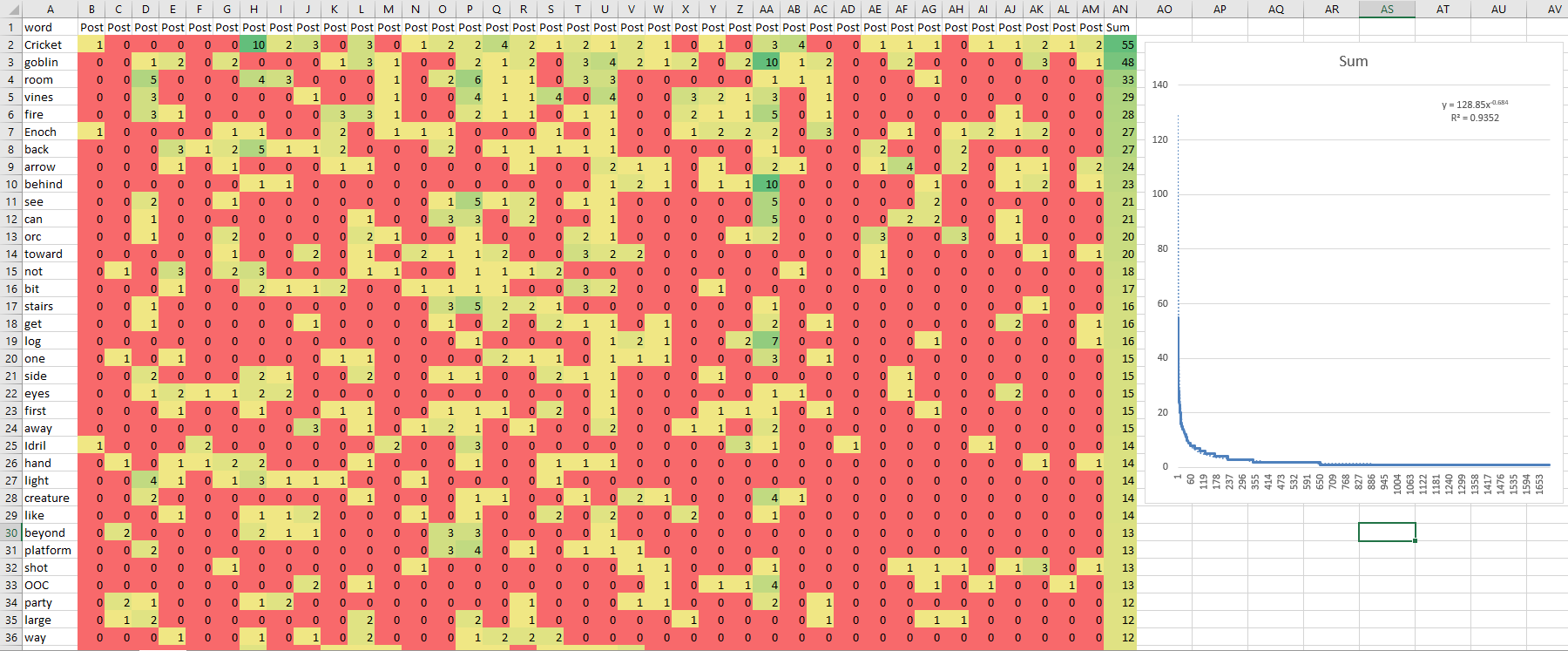
- Changing the coherence code so that the row values are zero or one. Actually, as the amount of data grows, BOW is getting more useful raw. This spreadsheet shows all posts, including the DM. Note that the word frequency is power law (R squared = .9352):

- Started the optimizer and excel utils classes
- NOAA meeting
- NOAA meeting 2
- Some thoughts from Aaron on our initial ML approach
-
I think for the first pass we do 1-2 models based on contract type focused on the $500k+ award contracts (120ish total).
-
We construct the inputs like sentences in the word generation LSTM with padded lengths equal to the longest running contract of that type, sorted by length. The model can be tested against current contracts held out in a test set using point by point prediction so we can show accuracy of the model against existing data and use that to set our accuracy threshold.
-
My guess is this will be at least an ORF/PAC model (two different primary contract types) which we can work on tuning with the learning_optimizer.py to get as accurate as possible in the timeframe we have.
-
One of the things we advertise as “next steps” is a detailed analysis of contracts based on similarity measures to identify a series of more accurate models. We can pair this with additional models such as Exponential Smoothing and ARIMA which use fundamentally the exact same pipeline.
-
The GUI will be plumbed up to show these analytic outputs on a per contract basis and we can show by the end of January a simple linear model and the LSTM model to demonstrate how Exponential Smoothing / ARIMA or model averages could be displayed. Once we have these outputs we can take the top 5 highest predicted UDO and display in a summary page so they can use those as a launching off point.
-
If we do it this way it means we only have to focus on the completion of TimeSeriesML LSTM and it’s data pipeline with a maximum of 2 initial models (contract type). I think that is a far more reasonable thing to complete in the timeframe and should still be really exciting to show off.







You must be logged in to post a comment.