
Get bike?
- These services had been shaved down to the point where most of us were only a hair’s breadth away from quitting, because all the surplus had been transferred from us and from business users to the companies.
- And the incentives are different for different users. Lurking is cheaper than posting, trolling by robot is free, etc. Would be interesting to try to model that
Book
- Finish today!
- Shutterstock first – done
- Finish with footnotes – done
SBIRs
- More writing – rolling in Rukan’s work
- Send a date in December for Lauren – done
- Chat with Aaron about JMOR paper
GPT Agents
- Set up a weekly meeting with Jason for Tuesdays at 2:00
- 4:00 Meeting – going to do some pulls for COVID racism. I tried out some new prompts using openAI’s chatbot and got some good results that I need to test.
- fediverse.space is a tool to visualize networks and communities on the fediverse. It works by crawling every instance it can find and aggregating statistics on communication between these.




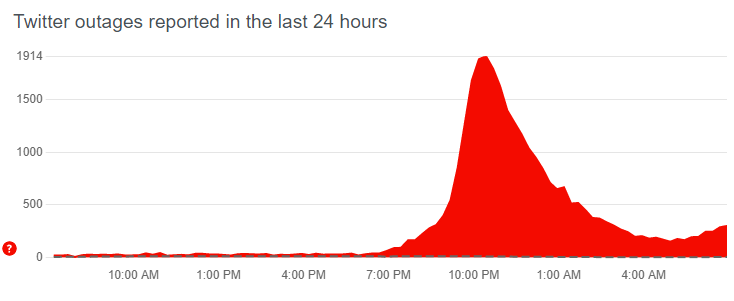

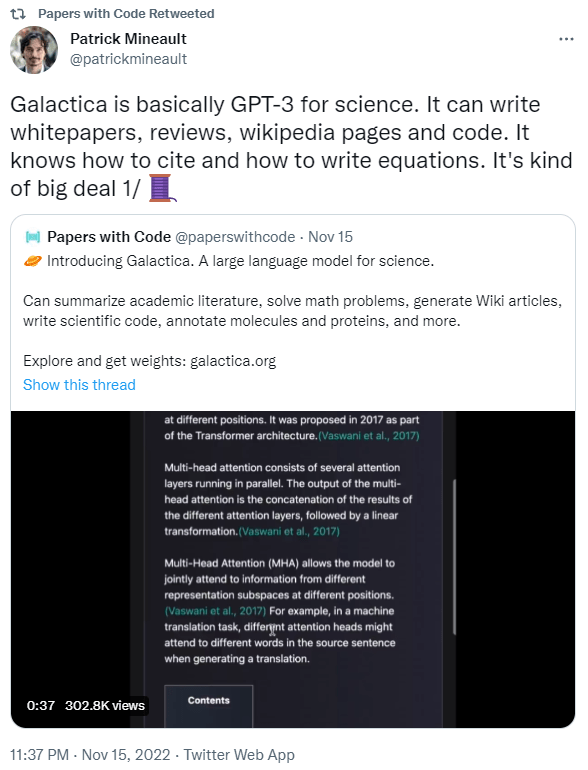



You must be logged in to post a comment.