
#COVID
- The Arabic translation program is chunking along. It’s translated over 27,000 tweets so far. I think I’m seeing the power and risks of AI/ML in this tiny example. See, I’ve been programming since the late 1970’s, in many, many, languages and environments, and the common thread in everything I’ve done was the idea of deterministic execution. That’s the idea that you can, if you have the time and skills, step through a program line by line in a debugger and figure out what’s going on. It wasn’t always true in practice, but the idea was conceptually sound.
- This translation program is entirely different. To understand why, it helps to look at the code:

- This is the core of the code. It looks a lot like code I’ve written over the years. I open a database, get some lines, manipulate them, and put them back. Rinse, lather, repeat.
- That manipulation, though…
- The six lines in yellow are the Huggingface API, which allow me to access Microsoft’s Marian Neural Machine Translation models, and have them use the pretrained models generated by the University of Helsinki. The one I’m using translates Arabic (src = ‘ar’) to English (trg = ‘en’). The lines that do the work are in the inner loop:
batch = tok.prepare_translation_batch(src_texts=[d['contents']]) gen = model.generate(**batch) # for forward pass: model(**batch) words: List[str] = tok.batch_decode(gen, skip_special_tokens=True)
- The first line is straightforward. It converts the Arabic words to tokens (numbers) that the language model works in. The last line does the reverse, converting result tokens to english.
- The middle line is the new part. The input vector of tokens is goes to the input layer of the model, where they get sent through a 12-layer, 512-hidden, 8-heads, ~74M parameter model. Tokens that can be converted to English pop put the other side. I know (roughly) how it works at the neuron and layer level, but the idea of stepping through the execution of such a model to understand the translation process is meaningless.
- In the time it took to write this, its translated about 1,000 more tweets. I can have my Arabic-speaking friends to a sanity check on a sample of these words, but we’re going to have to trust the overall behavior of the model to do our research in, because some of these systems only work on English text.
- So we’re trusting a system that we cannot verify to to research at a scale that would otherwise be impossible. If the model is good enough, the results should be valid. If the model behaves poorly, then we have bad science. The problem is right now there is only one Arabic to English translation model available, so there is no way to statistically examine the results for validity.
- And I guess that’s really how we’ll have to proceed in this new world where ML becomes just another API. Validity of results will depend on diversity on model architectures and training sets. That may occur naturally in some areas, but in others, there may only be one model, and we may never know the influences that it has on us.
GOES
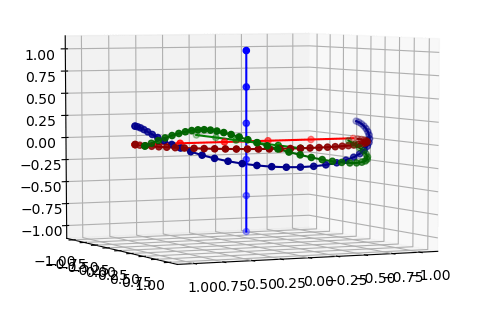
- More quaternions. Need to do multiple axis movement properly. Can you average two quaternions and have something meaningful?
- Here’s the reference frame with two rotations based off of the origin, so no drift. Now I need to do an incremental rotation to track these points:
GPT-2 Agents
- Start digging into knowledge graphs





















You must be logged in to post a comment.