
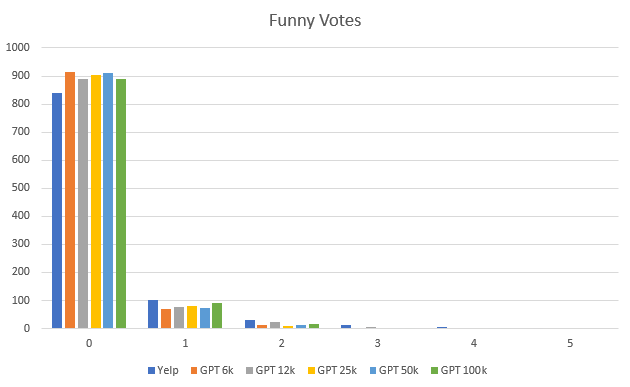
I had some perplexing runs trying different epoch counts on corpora recently. Here’s the 6k:
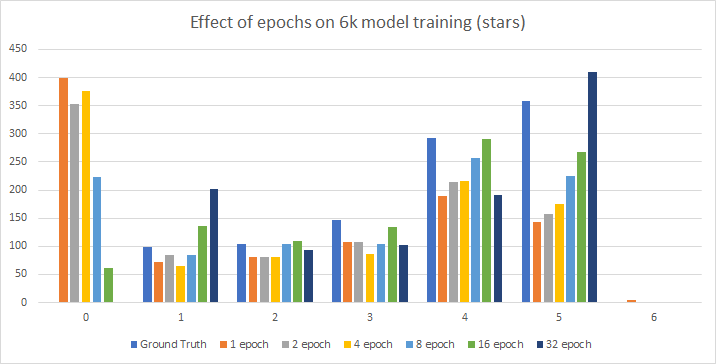
As you can see, only the 32 epoch can figure out there are no 0 star ratings, though the best overall match is the 16 epoch.
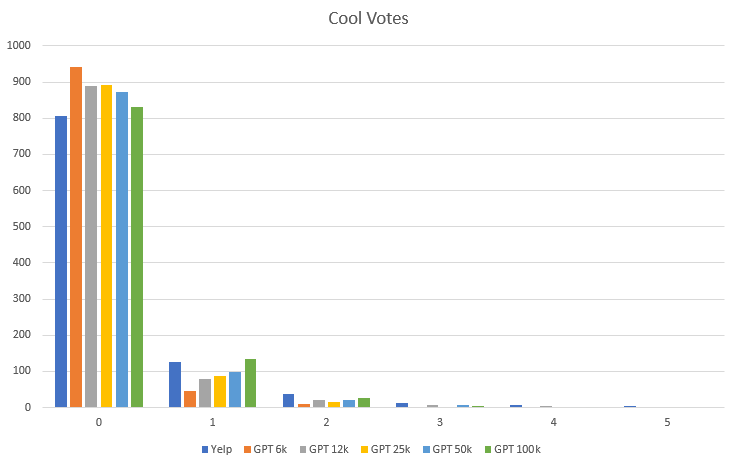
The 100k is weirder, and makes more sense when you look at the raw data:

As you can see, the 16 and 32 epoch miss the two star rating entirely, though aside(!) from that the fit isn’t bad:
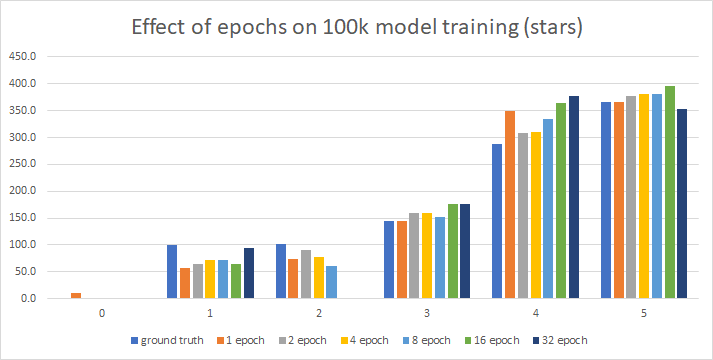
Looking at this, I’d say that 2-4 epochs seem to work well, and when I take out the explicit epoch, run_clm determines the epochs should be 3:
[INFO|trainer.py:1164] 2021-07-31 06:31:02,447 >> ***** Running training *****
[INFO|trainer.py:1165] 2021-07-31 06:31:02,447 >> Num examples = 1649
[INFO|trainer.py:1166] 2021-07-31 06:31:02,448 >> Num Epochs = 3
[INFO|trainer.py:1167] 2021-07-31 06:31:02,448 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1168] 2021-07-31 06:31:02,449 >> Total train batch size (w. parallel, distributed & accumulation) = 1
[INFO|trainer.py:1169] 2021-07-31 06:31:02,449 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1170] 2021-07-31 06:31:02,449 >> Total optimization steps = 4947
{'loss': 0.1737, 'learning_rate': 4.494643218111988e-05, 'epoch': 0.3}
I’m going to try an ensemble of these 3-epoch models to see what that looks like











You must be logged in to post a comment.