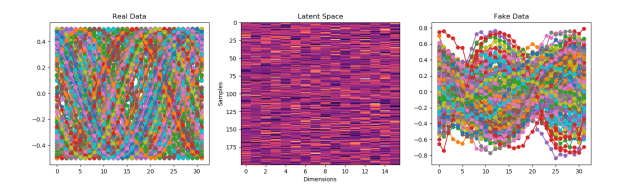
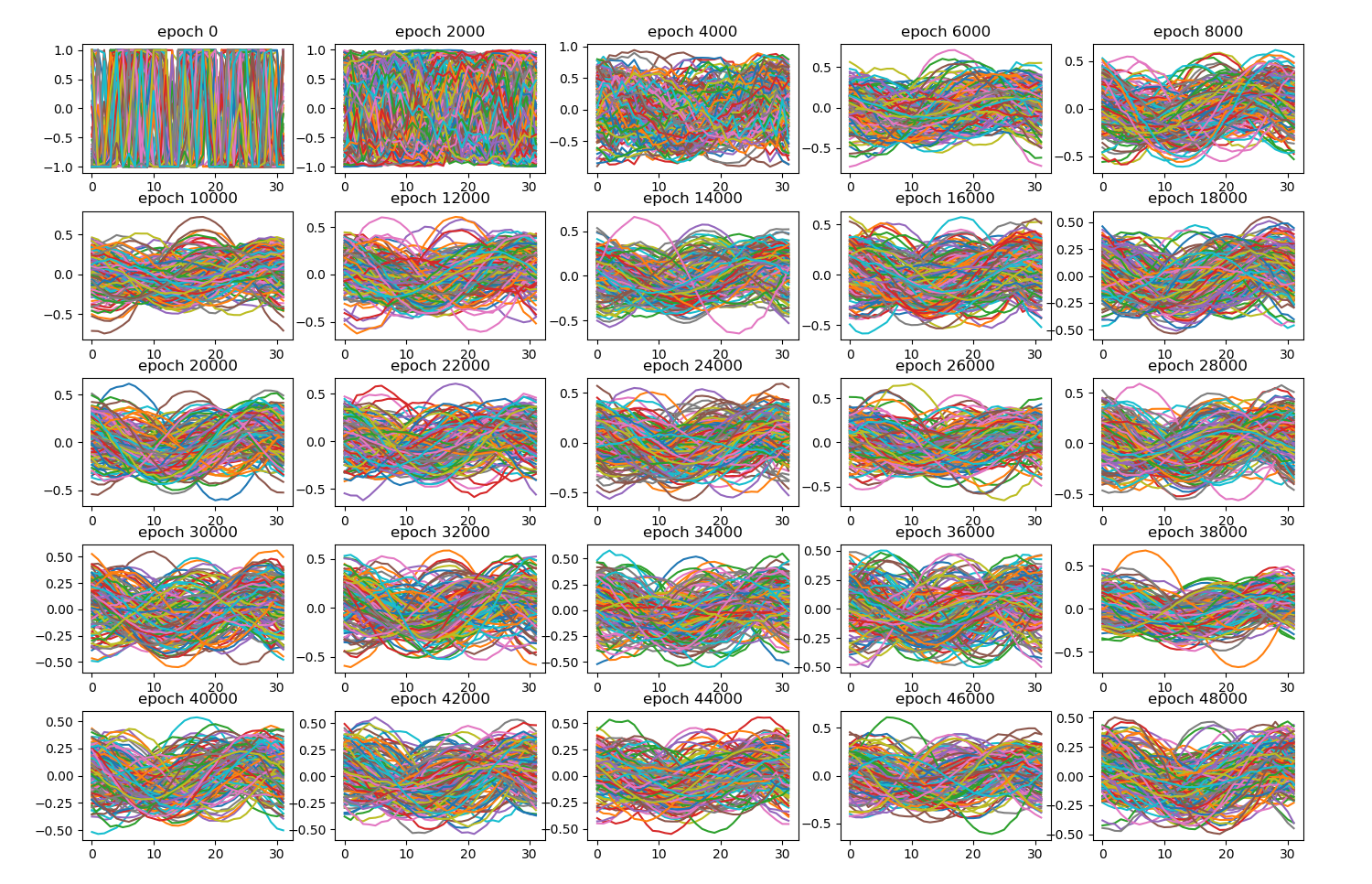
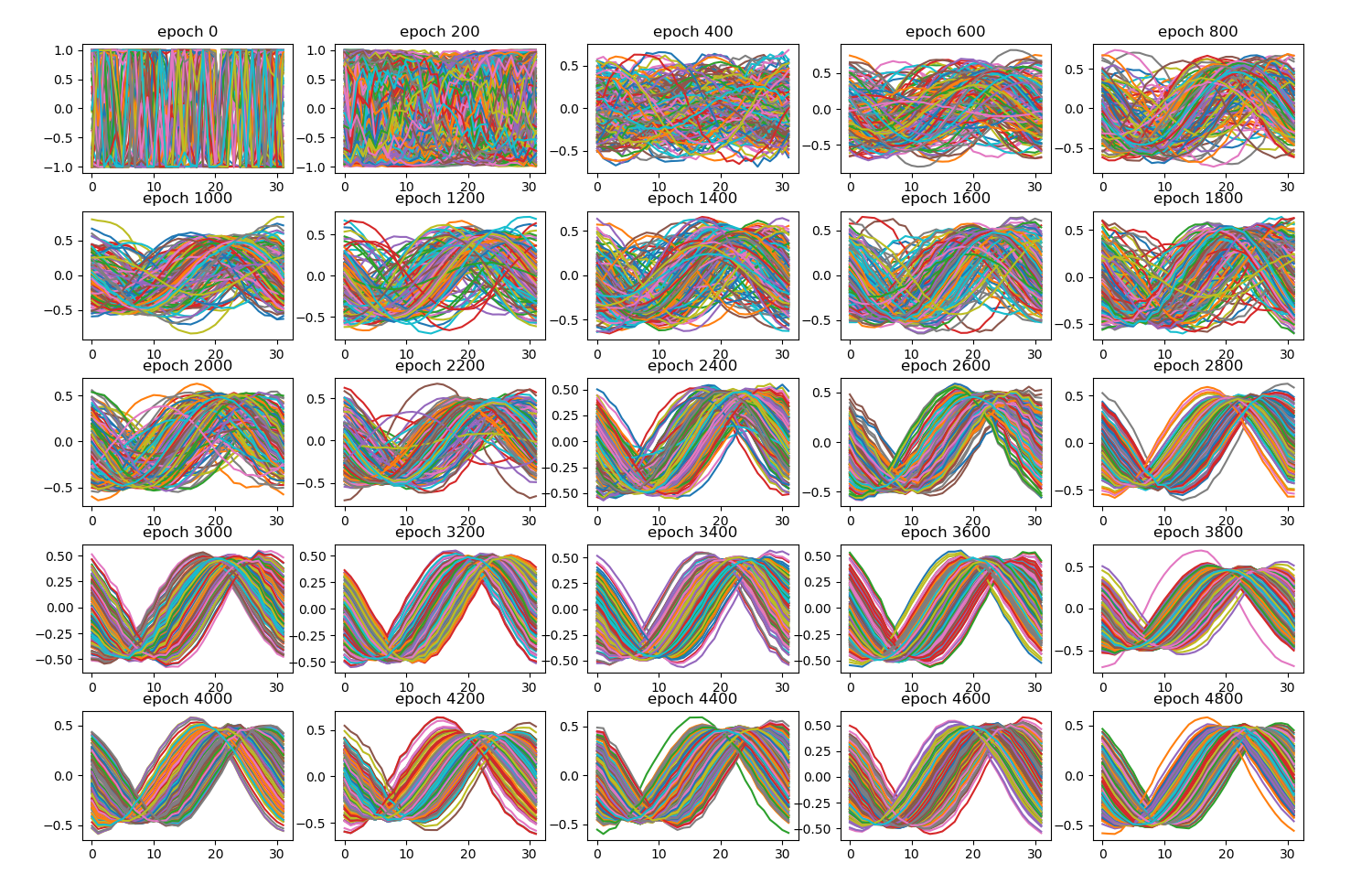
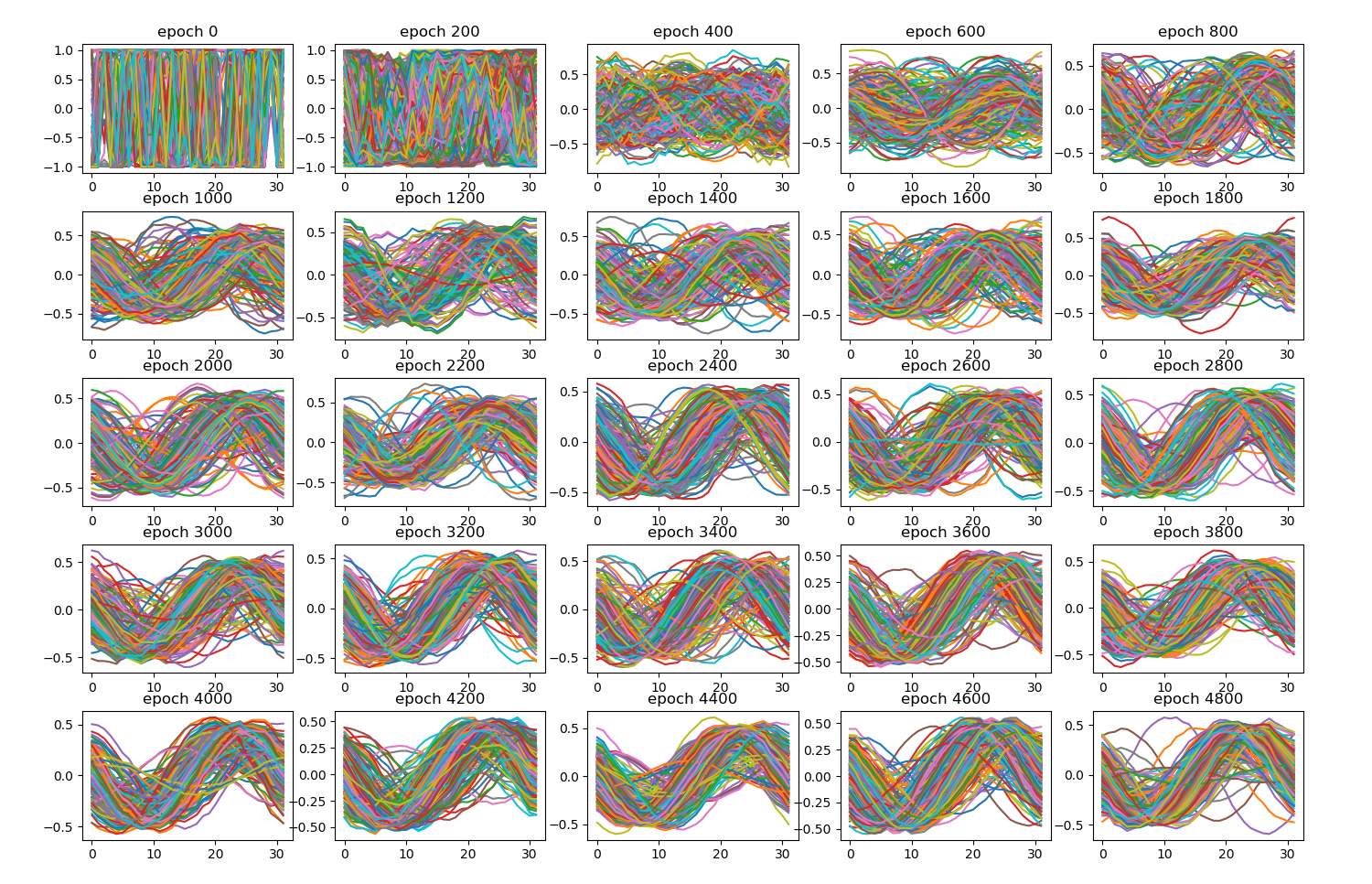
Started the to_narrative() method. Here’s the first result!
In 1987, Fred Van der Vliet played Loek Van Wely. Fred Van der Vliet was the higer-ranked player, with an Elo rating of 2330. Loek Van Wely was unrated.
The game began with ECO opening E69:
In move 1, Fred Van der Vliet moves white pawn from d2 to d4. Black moves knight from g8 to f6.
this is a comment
In move 2, White moves pawn from c2 to c4. Black moves pawn from g7 to g6.
In move 3, Fred Van der Vliet moves white pawn from g2 to g3. Loek Van Wely moves black bishop from f8 to g7.
In move 4, Fred Van der Vliet moves white bishop from f1 to g2. Loek Van Wely kingside castles.
In move 5, White moves knight from g1 to f3. Black moves pawn from c7 to c6.
In move 6, Fred Van der Vliet kingside castles. Loek Van Wely moves black pawn from d7 to d6.
In move 7, White moves knight from b1 to c3. Black moves knight from b8 to d7.
In move 8, White moves pawn from e2 to e4. Loek Van Wely moves black pawn from e7 to e5.
In move 9, White moves pawn from h2 to h3. Loek Van Wely moves black rook from f8 to e8.
In move 10, White moves rook from f1 to e1. Loek Van Wely moves black queen from d8 to b6.
In move 11, White moves pawn from d4 to d5. Black moves knight from d7 to c5.
In move 12, White moves rook from a1 to b1. Black moves pawn from a7 to a5.
In move 13, White moves bishop from c1 to e3. Black moves queen from b6 to c7.
In move 14, Fred Van der Vliet moves white knight from f3 to d2. Loek Van Wely moves black knight from f6 to h5.
In move 15, White moves queen from d1 to e2. Black moves pawn from h7 to h6.
In move 16, White moves pawn from d5 to c6. White takes black pawn. Black moves queen from c7 to c6. Black takes white pawn.
In move 17, White moves knight from c3 to d5. Black moves bishop from c8 to e6.
In move 18, White moves rook from e1 to c1. Black moves king from g8 to h7.
In move 19, White moves pawn from b2 to b3. Black moves rook from e8 to b8.
In move 20, White moves pawn from a2 to a3. Loek Van Wely moves black pawn from b7 to b6.
In move 21, White moves king from g1 to h2. Black moves queen from c6 to c8.
In move 22, Fred Van der Vliet moves white pawn from f2 to f4. Black moves pawn from e5 to f4. Black takes white pawn.
In move 23, Fred Van der Vliet moves white pawn from g3 to f4. White takes black pawn. Black moves rook from a8 to a7.
In move 24, Fred Van der Vliet moves white knight from d5 to c3. Black moves queen from c8 to d8.
In move 25, White moves knight from c3 to b5. Black moves rook from a7 to d7.
In move 26, Fred Van der Vliet moves white pawn from b3 to b4. Black moves pawn from a5 to b4. Black takes white pawn.
In move 27, White moves pawn from a3 to b4. White takes black pawn. Black moves knight from c5 to a6.
In move 28, White moves knight from d2 to f3. Loek Van Wely moves black queen from d8 to f6.
In move 29, White moves queen from e2 to d2. Black moves rook from b8 to c8.
In move 30, White moves knight from b5 to d6. White takes black pawn. Black moves bishop from e6 to c4. Black takes white pawn.
In move 31, White moves pawn from e4 to e5. Loek Van Wely moves black queen from f6 to d8.
In move 32, White moves pawn from b4 to b5. Loek Van Wely moves black knight from a6 to b8.
In move 33, White moves queen from d2 to b4. Black moves rook from d7 to d6. Black takes white knight.
In move 34, White moves pawn from e5 to d6. White takes black rook. Black moves bishop from c4 to d3.
In move 35, White moves rook from c1 to c8. White takes black rook. Black moves queen from d8 to c8. Black takes white rook.
In move 36, White moves rook from b1 to d1. Black moves bishop from d3 to e2.
In move 37, White moves rook from d1 to c1. Black moves queen from c8 to e8.
In move 38, Fred Van der Vliet moves white bishop from e3 to b6. White takes black pawn. Black moves bishop from e2 to f3. Black takes white knight.
In move 39, White moves bishop from g2 to f3. White takes black bishop. Loek Van Wely moves black knight from h5 to f4. Black takes white pawn.
In move 40, Fred Van der Vliet moves white rook from c1 to e1. Loek Van Wely moves black bishop from g7 to e5.
In move 41, White moves rook from e1 to e5. White takes black bishop. Loek Van Wely moves black queen from e8 to e5. Black takes white rook.
In move 42, White moves queen from b4 to d4. Black moves queen from e5 to b5. Black takes white pawn.
In move 43, White moves queen from d4 to f4. White takes black knight. Black moves queen from b5 to b6. Black takes white bishop.
In move 44, Fred Van der Vliet moves white queen from f4 to f7. White takes black pawn. Check. Black moves king from h7 to h8.
In move 45, White moves queen from f7 to f6. Check. Black moves king from h8 to h7.
In move 46, White moves bishop from f3 to e4. Black moves queen from b6 to a7.
In move 47, Fred Van der Vliet wins! Loek Van Wely resigns.



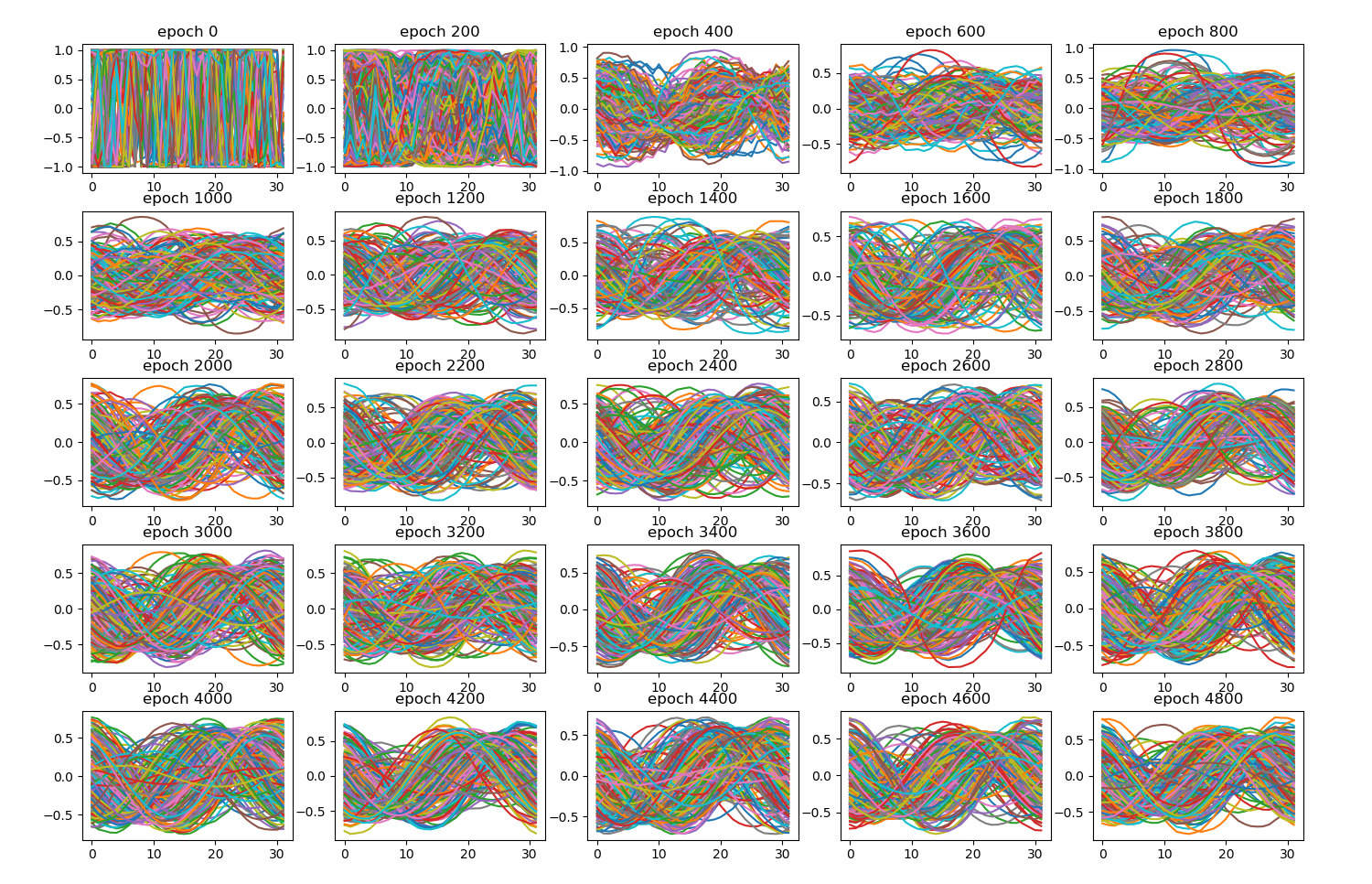

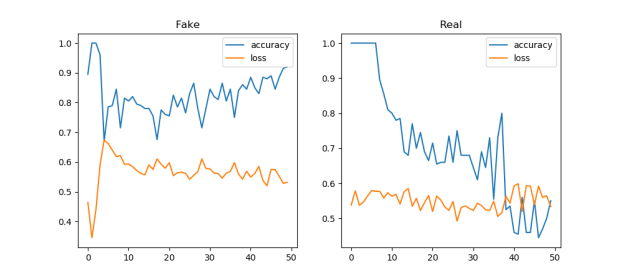

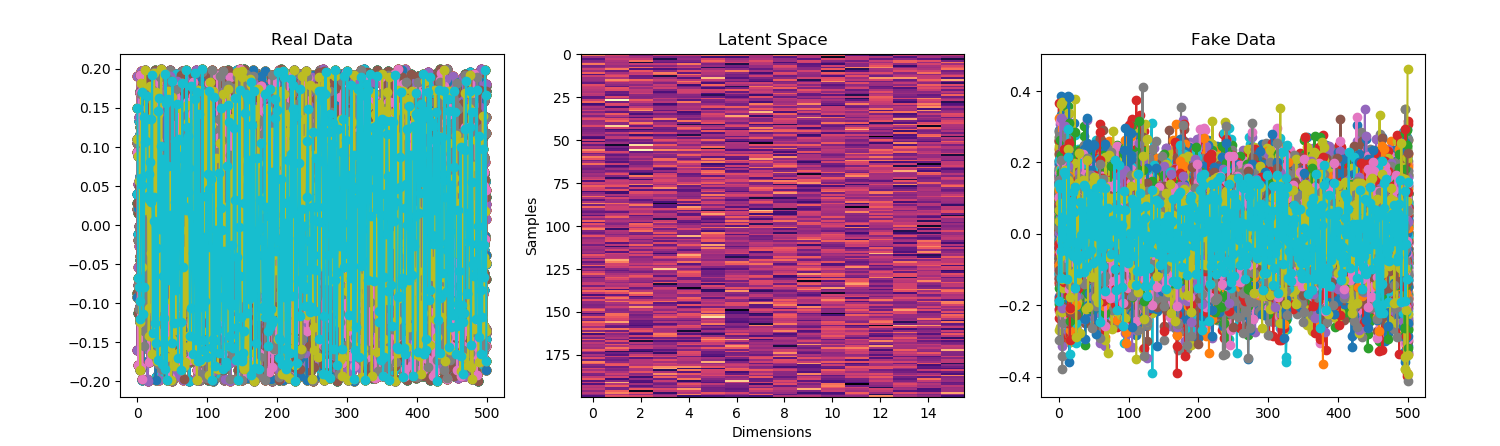
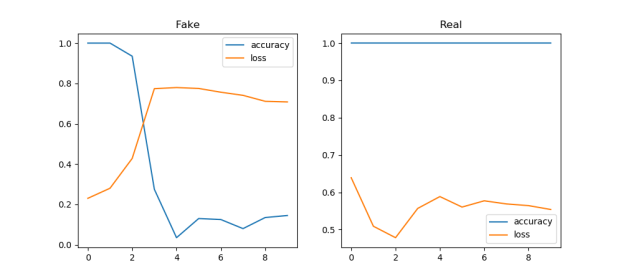
















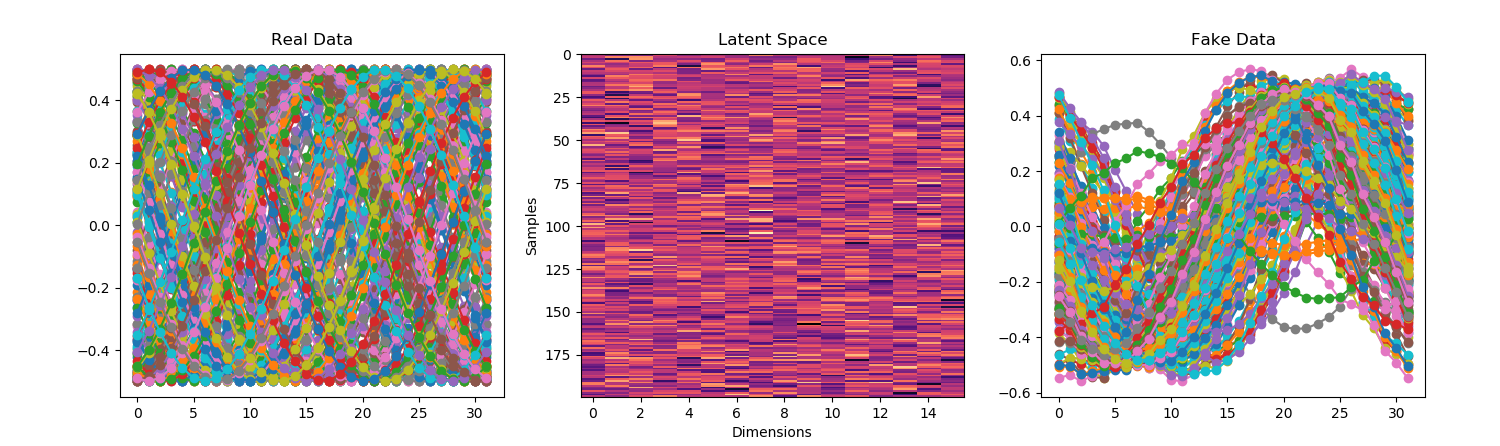
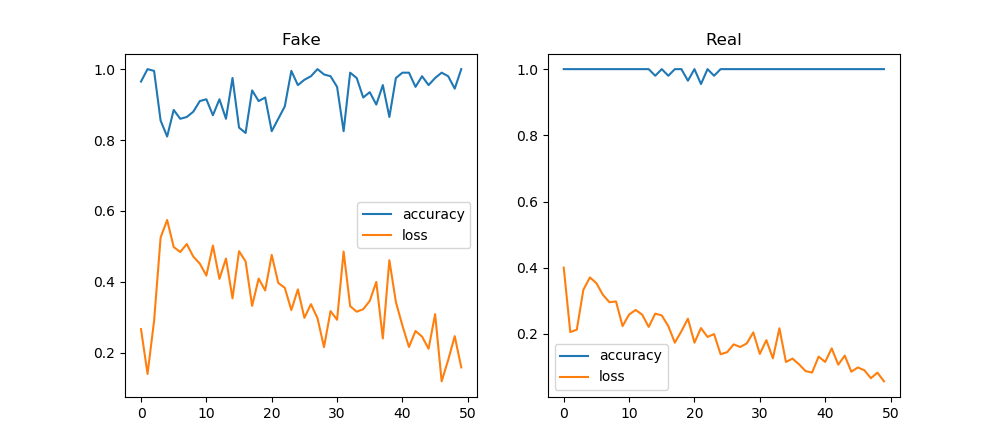










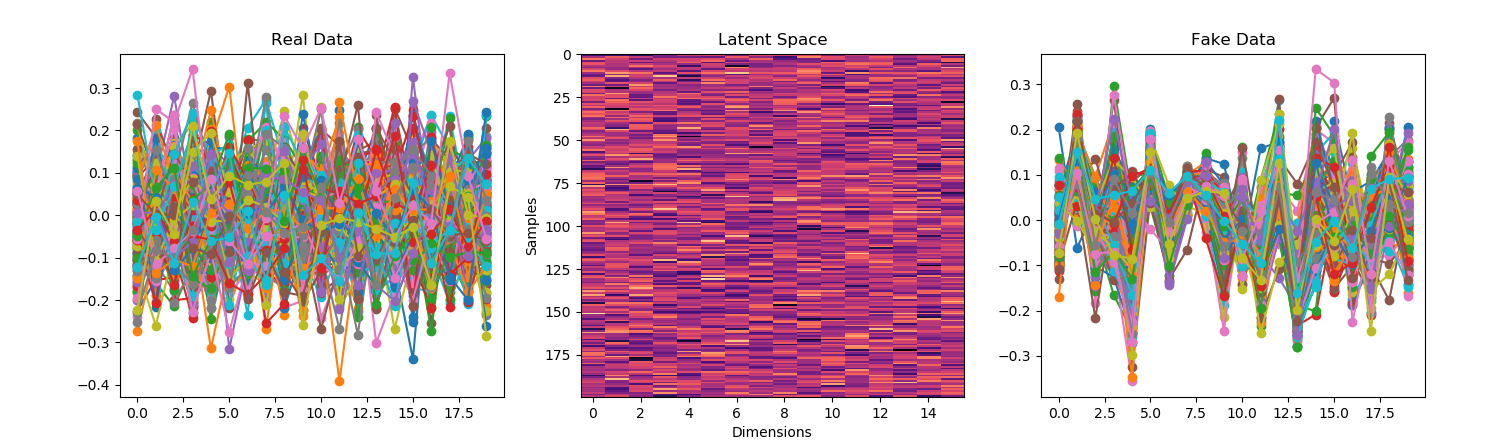











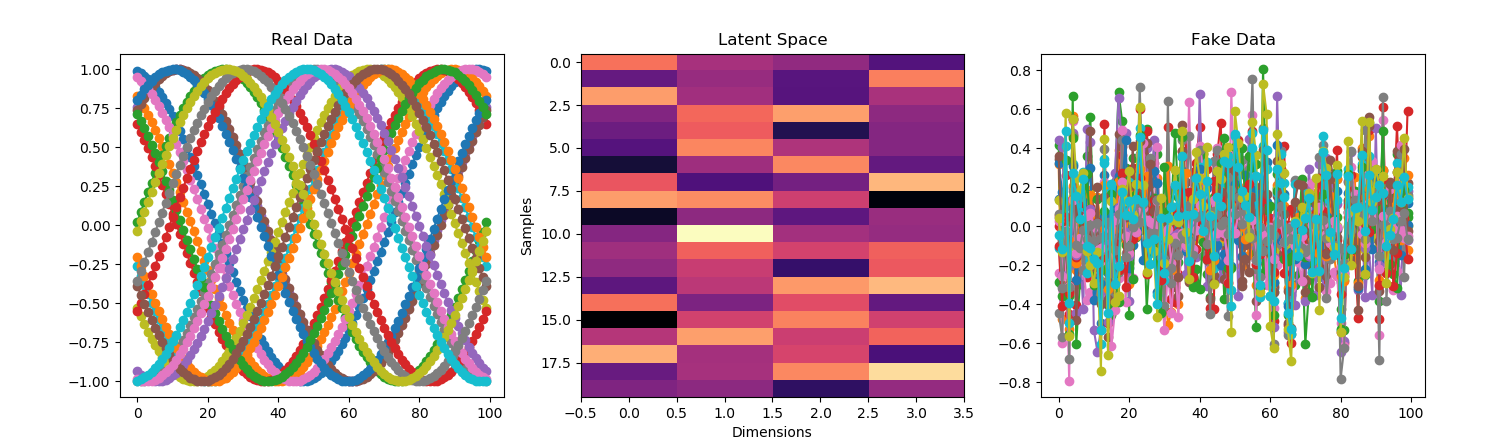








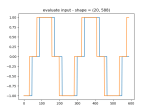
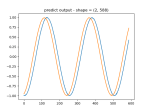

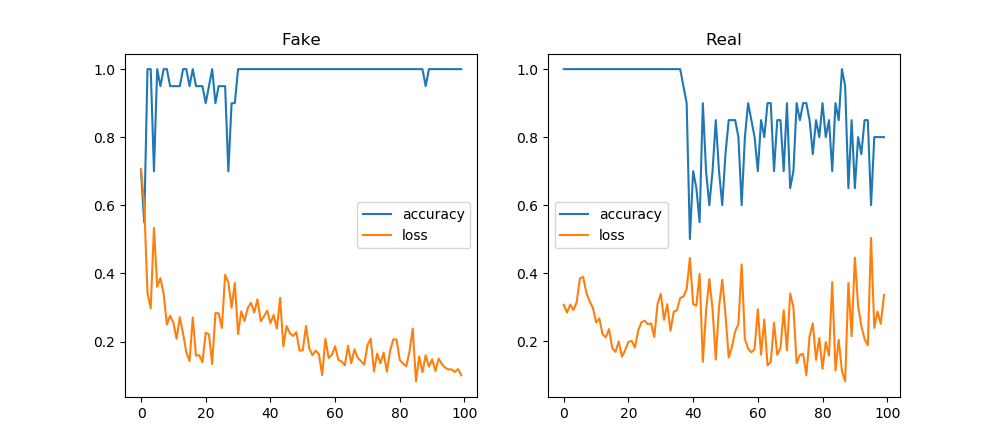
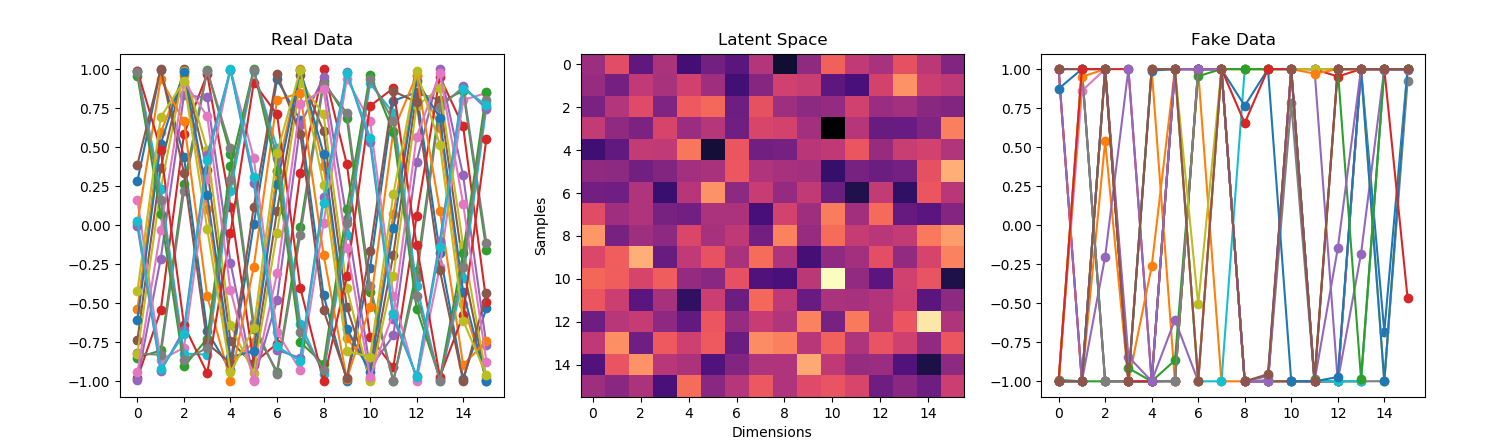





You must be logged in to post a comment.