
7:00 – 4:30 ASRC MKT
-
- Wrote up notes from yesterday’s meeting
- Look for JCMC requirements
- Change the rest of the “we” to “I” in the DC, then submit. Done, did a spell check because I had forgotten to integrate a spell checker!
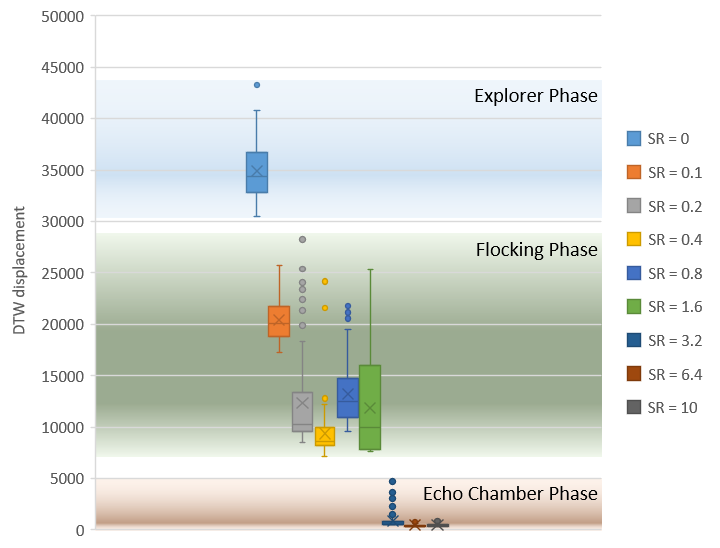
- Saw this today on the Google Research Blog: Closing the Simulation-to-Reality Gap for Deep Robotic Learning. In it they show how simulation can be used to improve deep learning because of the vast increase in conditions that can be simulated rather than found or built in the real world. The reason that it’s important in my work is that the simulation can feed and support the training of the classifiers once the simulation becomes sufficiently realistic.
- Because I can’t stop reading horrible things, ordered Totalitarianism, Terrorism and Supreme Values: History and Theory, by
- Not the most exciting thing, but yay!
ID posted message playerID parentID 1 1509458541 message 0 of 20 by Abbe, Karleen 5 6 2 1509458541 message 1 of 20 by Abbey, Abbi 7 6 3 1509458541 message 2 of 20 by Abbey, Abbi, responding to message 1 7 6 2 4 1509458542 message 3 of 20 by Abbe, Karleen, responding to message 2 5 6 3 5 1509458542 message 4 of 20 by Abbe, Karleen, responding to message 1 5 6 2 6 1509458542 message 5 of 20 by Abbe, Karleen, responding to message 4 5 6 5 7 1509458542 message 6 of 20 by Abbe, Karleen, responding to message 3 5 6 4 8 1509458542 message 7 of 20 by Abbe, Karleen, responding to message 1 5 6 2 9 1509458542 message 8 of 20 by Abbe, Karleen, responding to message 1 5 6 2 10 1509458542 message 9 of 20 by Aaren, Abbie, responding to message 2 3 6 3 11 1509458542 message 10 of 20 by Abbey, Abbi, responding to message 5 7 6 6 12 1509458542 message 11 of 20 by Abbe, Karleen, responding to message 10 5 6 11 13 1509458542 message 12 of 20 by Abbey, Abbi, responding to message 7 7 6 8 14 1509458542 message 13 of 20 by Aaren, Abbie 3 6 15 1509458542 message 14 of 20 by Abbe, Karleen, responding to message 8 5 6 9 16 1509458542 message 15 of 20 by Abbe, Karleen, responding to message 11 5 6 12 17 1509458542 message 16 of 20 by Abbe, Karleen 5 6 18 1509458542 message 17 of 20 by Abbe, Karleen, responding to message 4 5 6 5 19 1509458542 message 18 of 20 by Aaren, Abbie, responding to message 14 3 6 15 20 1509458542 message 19 of 20 by Aaren, Abbie, responding to message 2 3 6 3
- cleaning up some cases where scenario is set to null. Fixed. It’s the first array index problem. Grrrrr. Ok, broke some things trying to make things better….
- Then it’s time to make some REST interfaces
- Meeting with Cindy. Much progress!
- User-specified scenarios, seeded with some fun topics like conspiracy theories
- Private deliberations.
- Esperanto for verdict: verdikto
- Lobbies for collecting users
- Game starts when an DM-specified minimum is met, though there may be time to accumulate into a max as well
- Game ‘dies’ if no contribution (by all players?) in a certain window
- One user can kill a game by withdrawing. This can be attached to a user (troll), so the player can anonymously block in the future
- Games can be respawned, optionally without a triggering troll from the last time
- Games/Scenarios can be cloned
- Highest-quality games that reach a verdict are featured on the site. Quality could be determined by tagging or NLP+heuristics.










You must be logged in to post a comment.