
7:00 – very, very, late ASRC
- Tomorrow is March! I need to write a few paragraphs for Antonio this weekend
- YouTube stops recommending alt-right channels
- For the first two weeks of February, YouTube was recommending videos from at least one of these major alt-right channels on more than one in every thirteen randomly selected videos (7.8%). From February 15th, this number has dropped to less than one in two hundred and fifty (0.4%).
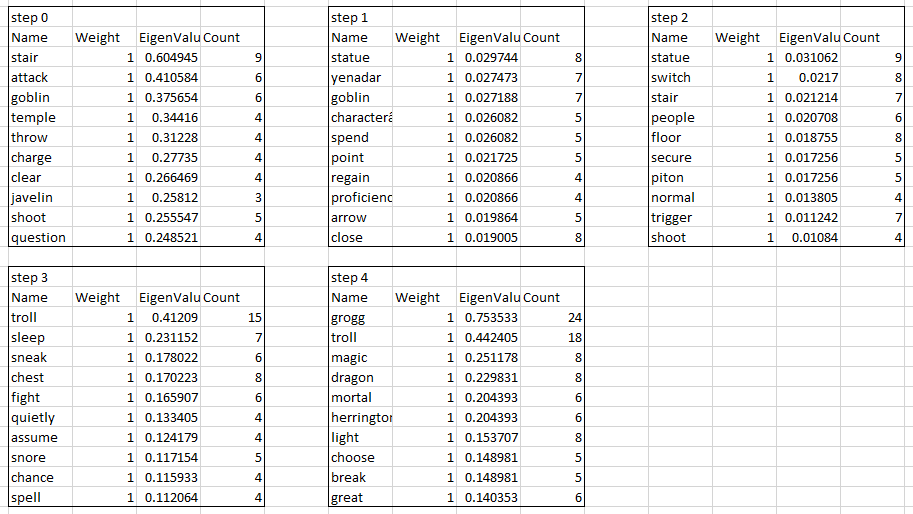
- Working on text splitting Group1 in the PHPBB database
- Updated the view so the same queries work
- Discovered that you can do this: …, “message” as type, …. That gives you a column of type filled with “message”. Via stackoverflow
- Mostly working, I’m missing the last bucket for some reason. But it’s good overlap with the Slack data.
- Was debugging on my office box, and was wondering where all the data after the troll was! Ooops, not loaded
- Changed the time tests to be > ts1 and <= ts2
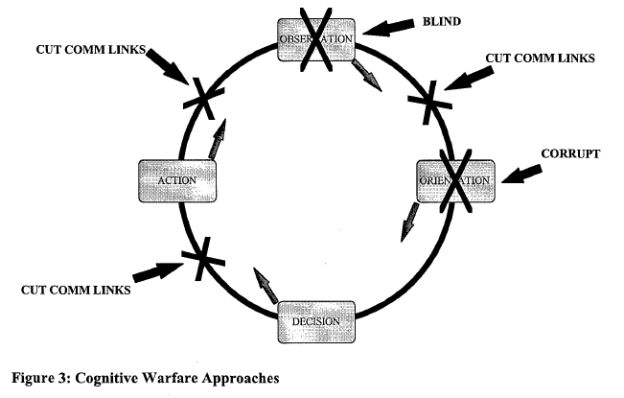
- Working on the white paper. Deep into strategy, Cyberdefense, and the evolution towards automatic active response in cyber.
- Looooooooooooooooooooooooooong meeting of Shimei’s group. Interesting but difficult paper: Learning Dynamic Embeddings from Temporal Interaction Networks
- Emily’s run in the dungeon finishes tonight!
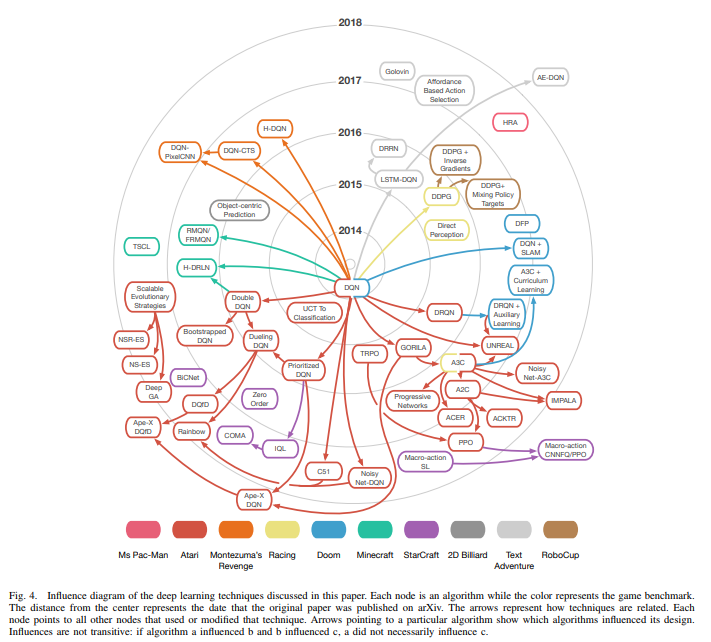
- Looks like I’m going to the TF Dev conference after all….

 \
\

You must be logged in to post a comment.