
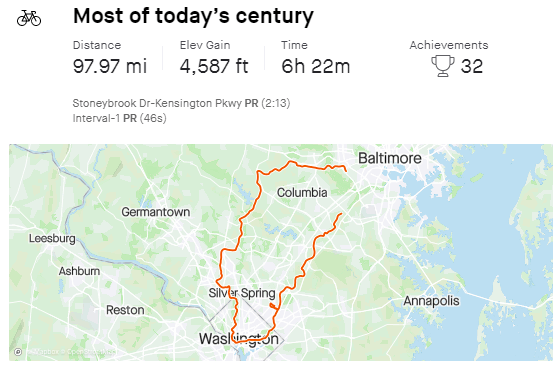
It’s all been a bit much recently, so yesterday I took advantage of the wonderful weather and went on a long ride with a few friends.
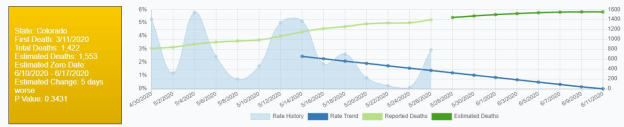
D20 – Nagged Zach with this image. He responses generally were “It is generally pretty optimistic around here”, and “According to google is is getting better. I wonder where their data comes from”.
GPT-2 Agents
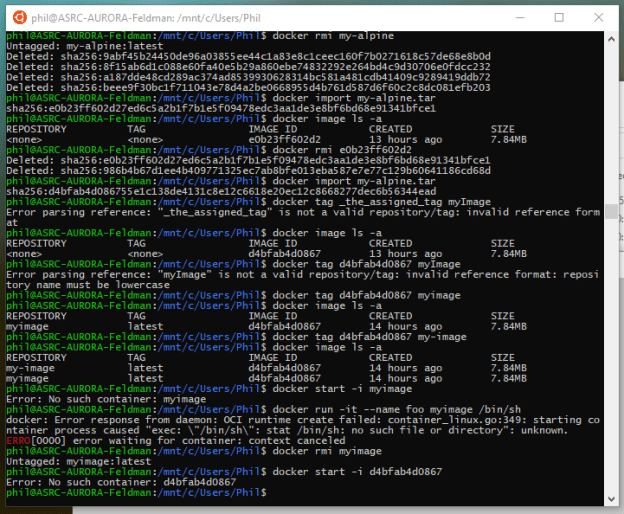
- Still some debugging. added output of the raw move files to find games better
- Dates aren’t right either – fixed
- Added some better triggering of the print_board method
- WOW! I mean it shouldn’t be that surprising, but the pgn is wrong. Going to add a flag for games with problem moves. Then I think I should be able to generate text.
GOES
- Put paper in the right format (word?)
- Create the slides. Verify the speaking duration – done. It’s 20 minuts, I think probably 15 for talk and 5 for questions
-
Found the technical paper repo. Looks like I didn’t have to worry about length! http://gvsets.ndia-mich.org/publications.php#MSTV
- Uploaded! Just use the info in the email from GVSETS Tech Session Admin
Google is profiting from dozens of websites that peddle hoaxes and conspiracy theories about Covid-19, according to a Tech Transparency Project (TTP) investigation, revealing a major hole in the company’s claims that it’s fighting misinformation about the pandemic.









You must be logged in to post a comment.