Kicked off the run on the adjusted UMAP. Lt’s see what happens. Blew up immediately. I need to refactor so I’m not storing things smarter. Fixed
Still killed the box at 160 files though
I think Monday I’m going to try the batch version of the code and see if I can get something reasonable
I should be able to just use the last UMAP model that was saved out
Also, just for kicks, I’d like to see if a NN could be trained to do manifold mapping based on maintaining the distance between high-dimensional points in lower-dimensional spaces. The distance function (linear, log, exponential, etc.) would adjust the learning behavior. And since the data could be loaded in batches, the memory issues are better. It’s basically an autoencoder? In fact, training an autoencoder that necks down to the desired number of dimensions (e.g 2 or 3) then attempts to reconstruct the original vector could be an interesting approach too.
The leopard expands the circle of faces it will eat:
I remember overhearing a conversation in a grocery store a few days before election day. An older white guy was telling a young woman that he was sure that he was expecting prices to come down “real soon.” She was looking concerned and trying to edge away. He was giddy. I am pretty sure that not enough has happened to change that dynamic.
But I want to suggest that what we are witnessing from the Trump administration is not just skillful manipulation of social media—it’s something more profoundly worrying. Today, we live in a clicktatorship, ruled by a LOLviathan. Our algothracy is governed by poster brains.1
But instead, the “contentification” of President Donald Trump’s policy is indeed the logical next step for a team that won the election with the help of influencers and content creators. Following suit, Trump’s cabinet has basically created the White House’s own cinematic universe.
Elon Musk hasn’t stopped Grok, the chatbot developed by his artificial intelligence company xAI, from generating sexualized images of women. After reports emerged last week that the image generation tool on X was being used to create sexualized images of children, Grok has created potentially thousands of nonconsensual images of women in “undressed” and “bikini” photos.
LNEC – Laboratório Nacional de Engenharia Civil (National Laboratory for Civil Engineering) is a public institute of Science and Technology (S&T), with the status of a State Laboratory that carries out research in all fields of civil engineering, giving it a unique multidisciplinary perspective. (Research fellowships)
Tasks
Lunch ride. Nice!
3:00 Alden meeting – just chatting. More stuff in 2 weeks.
Added a section about community financial instruments toP33
SBIRs
Kick off embedding timing run – and pretty promptly killed the machine. Need to see how to minimize memory use. Had a chat with Gemini that produced some things worth trying.
9:00 Meeting with Aaron. Time to revisit these charts:
Chat-based cybercrime has emerged as a pervasive threat, with attackers leveraging real-time messaging platforms to conduct scams that rely on trust-building, deception, and psychological manipulation. Traditional defense mechanisms, which operate on static rules or shallow content filters, struggle to identify these conversational threats, especially when attackers use multimedia obfuscation and context-aware dialogue. In this work, we ask a provocative question inspired by the classic Imitation Game: Can machines convincingly pose as human victims to turn deception against cybercriminals? We present LURE (LLM-based User Response Engagement), the first system to deploy Large Language Models (LLMs) as active agents, not as passive classifiers, embedded within adversarial chat environments. LURE combines automated discovery, adversarial interaction, and OCR-based analysis of image-embedded payment data. Applied to the setting of illicit video chat scams on Telegram, our system engaged 53 actors across 98 groups. In over 56 percent of interactions, the LLM maintained multi-round conversations without being noticed as a bot, effectively “winning” the imitation game. Our findings reveal key behavioral patterns in scam operations, such as payment flows, upselling strategies, and platform migration tactics.
Now, to be clear, those workers haven’t been laid off because their jobs are now being done by AI, and they’ve been replaced by bots. Instead, they’ve been laid off by execs who now have AI to use as an excuse for going after workers they’ve wanted to cut all along. (From Anil Dash)
Tasks
Light cleaning
4:00 Showing
Working with Terry on getting out hotel sorted
SBIRs
Created an enormous tar file of all the pkl files
Start on the UMAP recoding
Reading in the lists of lists and extracting the embeddings
“In some cases, one of the biggest problems Venezuelans have is they have to declare independence from Cuba,” Rubio added. “They tried to basically colonize it from a security standpoint. So, yeah, look, if I lived in Havana and I was in the government, I’d be concerned at least a little bit.”
A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at this https URL.
However, on real-world data (DROID and Robocasa), both larger encoders and deeper predictors yield consistent improvements, suggesting that scaling benefits depend on task complexity. We introduced an interface for planning with Nevergrad optimizers, leaving room for exploration of optimizers and hyperparameters. On the planning side, we found that CEM performs best overall. The NG planner performs similarly to CEM on real-world manipulation data (DROID and Robocasa) while requiring less hyperparameter tuning, making it a practical alternative when transitioning to new tasks or datasets.
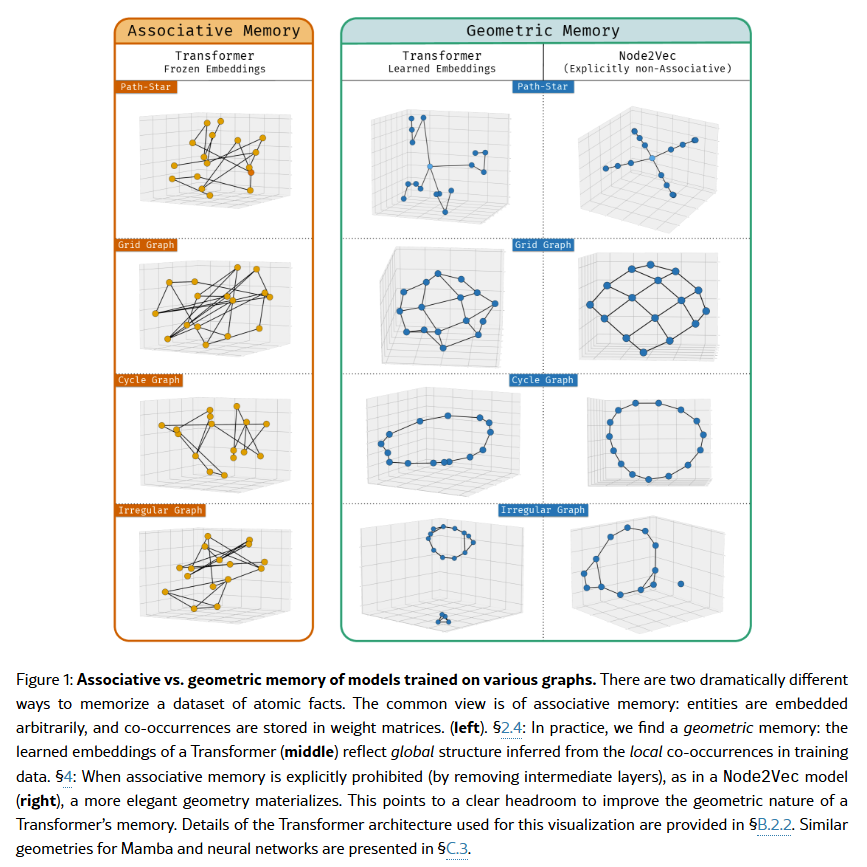
Deep sequence models are said to store atomic facts predominantly in the form of associative memory: a brute-force lookup of co-occurring entities. We identify a dramatically different form of storage of atomic facts that we term as geometric memory. Here, the model has synthesized embeddings encoding novel global relationships between all entities, including ones that do not co-occur in training. Such storage is powerful: for instance, we show how it transforms a hard reasoning task involving an l-fold composition into an easy-to-learn 1-step navigation task. From this phenomenon, we extract fundamental aspects of neural embedding geometries that are hard to explain. We argue that the rise of such a geometry, as against a lookup of local associations, cannot be straightforwardly attributed to typical supervisory, architectural, or optimizational pressures. Counterintuitively, a geometry is learned even when it is more complex than the brute-force lookup. Then, by analyzing a connection to Node2Vec, we demonstrate how the geometry stems from a spectral bias that – in contrast to prevailing theories –indeed arises naturally despite the lack of various pressures. This analysis also points out to practitioners a visible headroom to make Transformer memory more strongly geometric. We hope the geometric view of parametric memory encourages revisiting the default intuitions that guide researchers in areas like knowledge acquisition, capacity, discovery, and unlearning.
Abstract! Touched it but mostly to make sure that elements from this piece are mentioned.
Went to see Avatar. It is in fact a lot like a fireworks display. Some of the CGI of human faces is crazy good – basically no uncanny valley of any kind. And I like the themes of the series, even if it’s all a bit heavy-handed and not subtle.
Well, that was a year. Or something. Let’s try to do better, everyone!
Got myself some Therm-IC heated socks, and am going to try them out on the sub-freezing end-of-year ride today. Looks like I will have moved over 8k miles under my own power this year.
Tasks
Groceries
Work on the abstracts
SBIRs
Kick off a run and call it a day. At 26k books done
Machine learning models of vastly different modalities and architectures are being trained to predict the behavior of molecules, materials, and proteins. However, it remains unclear whether they learn similar internal representations of matter. Understanding their latent structure is essential for building scientific foundation models that generalize reliably beyond their training domains. Although representational convergence has been observed in language and vision, its counterpart in the sciences has not been systematically explored. Here, we show that representations learned by nearly sixty scientific models, spanning string-, graph-, 3D atomistic, and protein-based modalities, are highly aligned across a wide range of chemical systems. Models trained on different datasets have highly similar representations of small molecules, and machine learning interatomic potentials converge in representation space as they improve in performance, suggesting that foundation models learn a common underlying representation of physical reality. We then show two distinct regimes of scientific models: on inputs similar to those seen during training, high-performing models align closely and weak models diverge into local sub-optima in representation space; on vastly different structures from those seen during training, nearly all models collapse onto a low-information representation, indicating that today’s models remain limited by training data and inductive bias and do not yet encode truly universal structure. Our findings establish representational alignment as a quantitative benchmark for foundation-level generality in scientific models. More broadly, our work can track the emergence of universal representations of matter as models scale, and for selecting and distilling models whose learned representations transfer best across modalities, domains of matter, and scientific tasks.
Neuronpedia is a free and open source platform for AI interpretability. It may be a nice way at getting at the layer activations that I’ve been looking for.
Set up the example chapters in the ACM book format – done. That took a while. I can’t get the whole booke to work either.
Cleaning/Organizing – done
7:00 – 7:45 showing – done
Pick up Barbara 9:50 – done
Terry at 6:00 – done
SBIRs
9:00 standup – done
More runs started
Start looking at how to run UMAP across multiple pickle files. Probably just iterate over the files to create the mapping and save it, then a second stage to calculate the mapped points
Send the Gemini analysis to Clay and CC Aaron – done. Clay says “Sounds like a good shrooms date, but not a collaborator” L.O.L.
Current Large Language Models (LLMs) safety approaches focus on explicitly harmful content while overlooking a critical vulnerability: the inability to understand context and recognize user intent. This creates exploitable vulnerabilities that malicious users can systematically leverage to circumvent safety mechanisms. We empirically evaluate multiple state-of-the-art LLMs, including ChatGPT, Claude, Gemini, and DeepSeek. Our analysis demonstrates the circumvention of reliable safety mechanisms through emotional framing, progressive revelation, and academic justification techniques. Notably, reasoning-enabled configurations amplified rather than mitigated the effectiveness of exploitation, increasing factual precision while failing to interrogate the underlying intent. The exception was Claude Opus 4.1, which prioritized intent detection over information provision in some use cases. This pattern reveals that current architectural designs create systematic vulnerabilities. These limitations require paradigmatic shifts toward contextual understanding and intent recognition as core safety capabilities rather than post-hoc protective mechanisms.
My reaction to this is that either 1) It may be a mechanism where bad actors can learn to manipulate intent or 2) bad actors can use this mechanism to search for the deeper intentions in potential candidates that align with the goals of the actors.
Also interesting implications for WH/AI filtering. What is the intent behind a scam, post, or news article?
The Raines’ lawsuit alleges that OpenAI caused Adam’s death by distributing ChatGPT to minors despite knowing it could encourage psychological dependency and suicidal ideation. His parents were the first of five families to file wrongful-death lawsuits against OpenAI in recent months, alleging that the world’s most popular chatbot had encouraged their loved ones to kill themselves. A sixth suit filed this month alleges that ChatGPT led a man to kill his mother before taking his own life.
Tasks
10:00 showing, and a 2:00 showing, which kinda upended the day
Finish script that goes though all the URLs in a file and looks for 404 errors – done. Found one too!
Finish ACM proposal – not done, but closer
Winterize mower – tomorrow?
1:00 ride. Looks less cold. Monday looks nice, then BRRR.
Kick off a (5k book?) run and go for a hike – done and done. Also started another run. I have managed to spend $10!
Tried to load Linux on the dev box, but was thwarted by the inability to boot from the thumb drive. Rather than struggle , I dropped it off with actual professionals. Should be ready in a few days. They were fixing a Kitchen Aid mixer when I arrived. Was not expecting that.
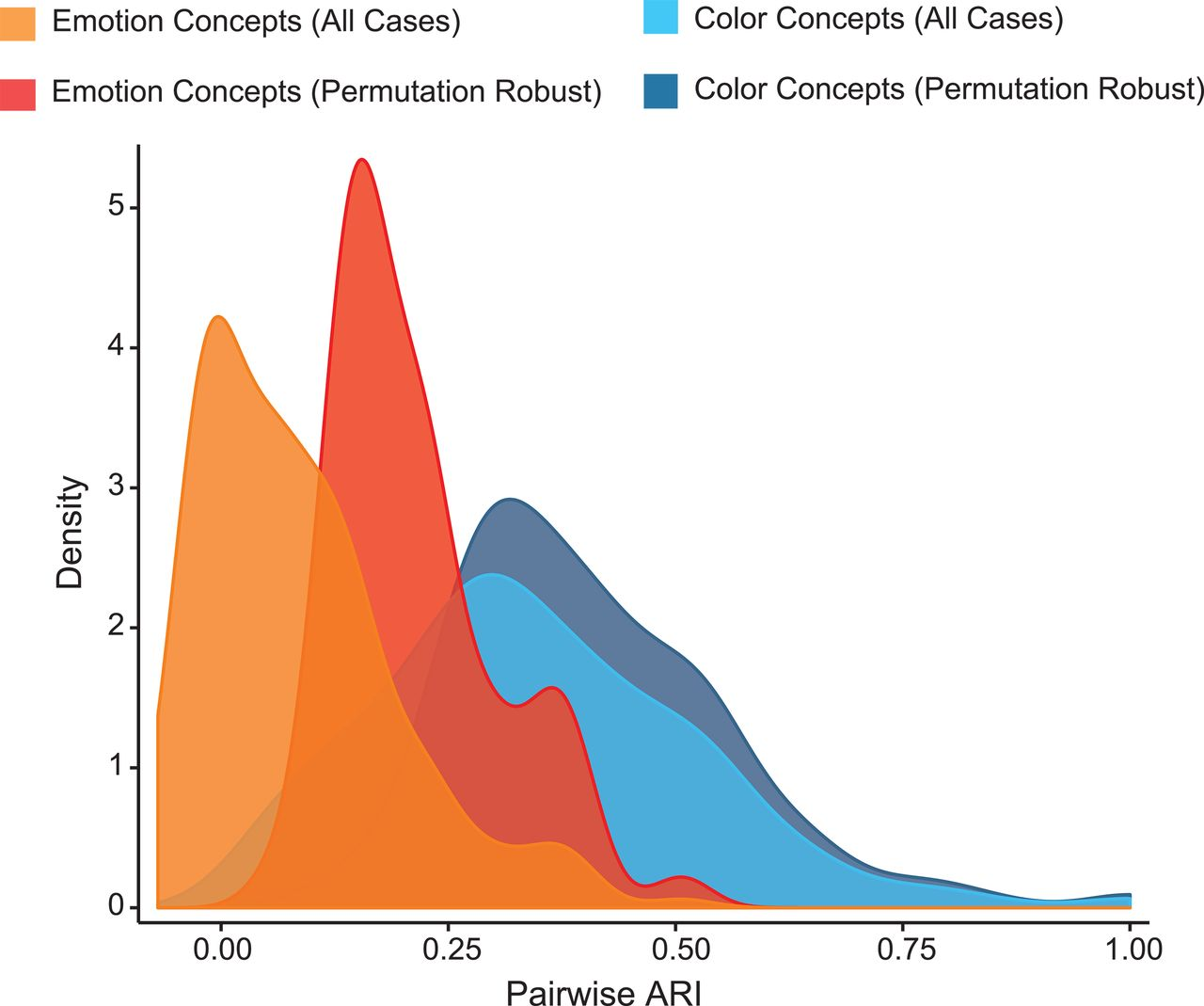
Many human languages have words for emotions such as “anger” and “fear,” yet it is not clear whether these emotions have similar meanings across languages, or why their meanings might vary. We estimate emotion semantics across a sample of 2474 spoken languages using “colexification”—a phenomenon in which languages name semantically related concepts with the same word. Analyses show significant variation in networks of emotion concept colexification, which is predicted by the geographic proximity of language families. We also find evidence of universal structure in emotion colexification networks, with all families differentiating emotions primarily on the basis of hedonic valence and physiological activation. Our findings contribute to debates about universality and diversity in how humans understand and experience emotion.
These people look interesting (Unbreaking). They are documenting the disintegration of USA norms(?) using a timeline of summaries among other things. Once I get the embedding mapping done, it would be a good thing to try to run through the system. One of their founding members wrote this:
All this year, as I have chewed my way along the edges of this almost unfathomable problem, what happened in Valdez came to feel less like a metaphor and more like a model. That’s how I’ll work with it here. Not because the circumstances of megathrust earthquakes in fjords are literally the same as the societal problem of collective derangement, but because the model gives me new ways to take problem apart and see how the pieces interact.






You must be logged in to post a comment.