
7:00 – 5:00 ASRC MKT
- The lightning round slides are in!
- Get Speaker – done
- Get posters – done
- Haircut – done
- drop off DME/KLR – done
- Under Pressure response – done, I think?
- upload ML excel files (done) to play around with graph laplacians some more – done
- Print out two travel packets – done
- create shared itinerary document – started. Aaron needs to finish his part
- From KQED Silicon Valley Conversations The Future of Music: Computer or Composer
- Ge Wang is an Associate Professor at Stanford University in the Center for Computer Research in Music and Acoustics (CCRMA). He specializes in the art of computer music design — researching programming languages and interactive software design for music, interaction design, expressive mobile music, new performance ensembles (laptop orchestra and mobile phone orchestra), human-computer interaction, visualization (sndpeek), music game design, aesthetics of technology-mediated design, and methodologies for education at the intersection of art, engineering, and design.
- Doug Eck is a research scientist working on Magenta, a research project exploring the role of machine learning in the process of creating art and music. Primarily this involves developing new deep learning and reinforcement learning algorithms for generating songs, images, drawings, and other materials. But it’s also an exploration in building smart tools and interfaces that allow artists and musicians to extend (not replace!) their processes using these models. Started by me in 2016, Magenta now involves several researchers and engineers from the Google Brain team as well as many others collaborating via open source. Aside from Magenta, I’m working on sequence learning models for summarization and text generation as well new ways to improve AI-generated content based on user feedback.
- Amy X Newburg has been developing her own brand of irreverently genre-crossing works for voice, live electronics and chamber ensembles for over 25 years, known for her innovative use of live looping technology with electronic percussion, her 4-octave vocal range and her colorful — often humorous — lyrics. One of the earliest performers to work with live digital looping, Amy has presented her solo “avant-cabaret” songs at such diverse venues as the Other Minds and Bang on a Can new music festivals, the Berlin International Poetry Festival, the Wellington and Christchurch Jazz Festivals (New Zealand), the Warsaw Philharmonic Hall, electronic music festivals, colleges, rock clubs and concert halls throughout the U.S. and abroad.
- Teens, Social Media & Technology 2018
- YouTube, Instagram and Snapchat are the most popular online platforms among teens. Fully 95% of teens have access to a smartphone, and 45% say they are online ‘almost constantly’
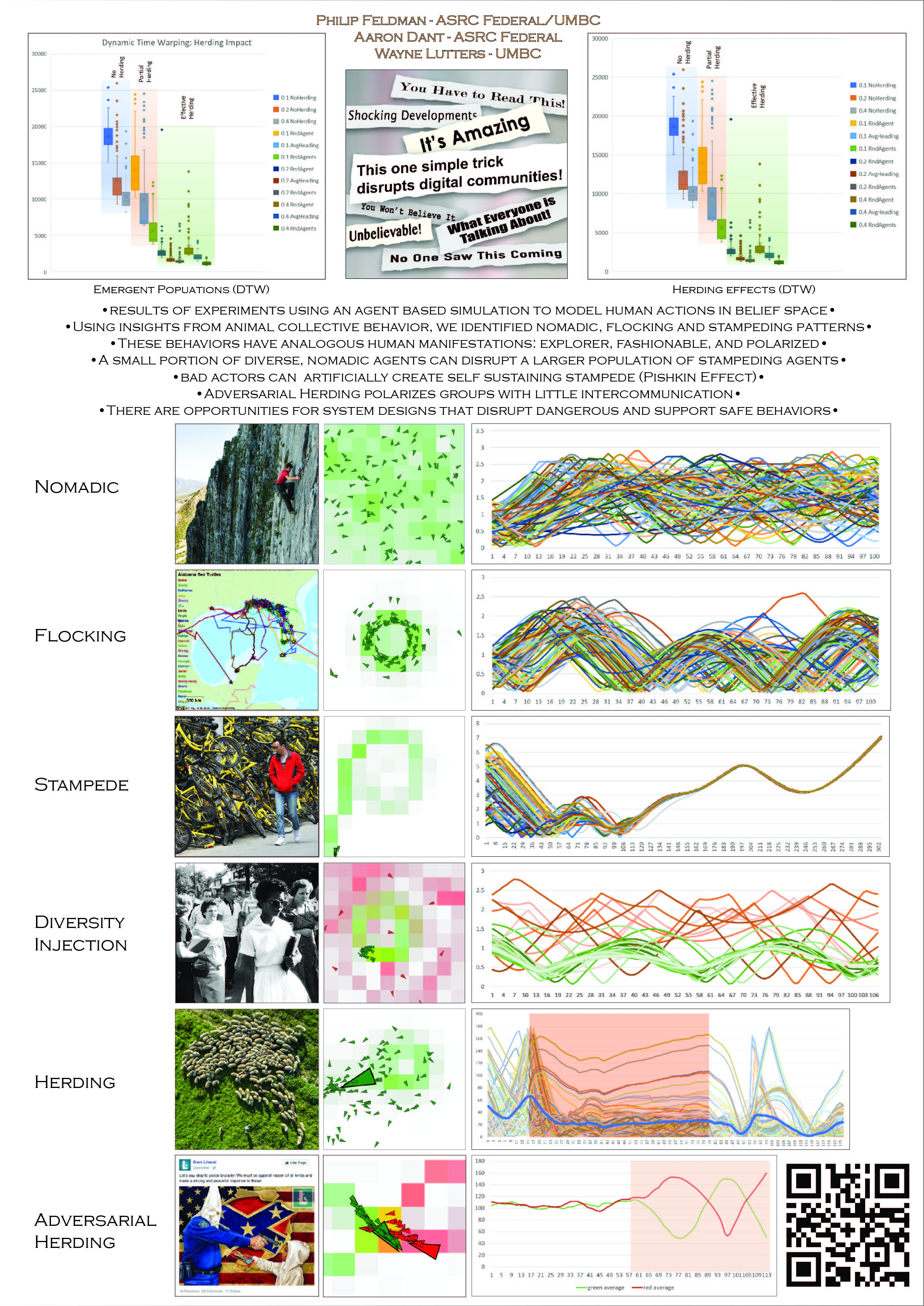
- Aaron found this: Density-functional fluctuation theory of crowds
- A primary goal of collective population behavior studies is to determine the rules governing crowd distributions in order to predict future behaviors in new environments. Current top-down modeling approaches describe, instead of predict, specific emergent behaviors, whereas bottom-up approaches must postulate, instead of directly determine, rules for individual behaviors. Here, we employ classical density functional theory (DFT) to quantify, directly from observations of local crowd density, the rules that predict mass behaviors under new circumstances. To demonstrate our theory-based, data-driven approach, we use a model crowd consisting of walking fruit flies and extract two functions that separately describe spatial and social preferences. The resulting theory accurately predicts experimental fly distributions in new environments and provides quantification of the crowd “mood”. Should this approach generalize beyond milling crowds, it may find powerful applications in fields ranging from spatial ecology and active matter to demography and economics.
- Here’s an interesting part: The DFFT analysis that we present is particularly powerful because it separates the influence of the environment on agents from interactions among those agents.
- This implies that it should (could? might?) be possible to calculate a social/environmental ratio for individual agents. High environmental are nomadic. High social are stampede-prone. Need to dig in further.
- Mechanical Vibrations and Waves » Lecture 4: Coupled Oscillators, Normal Modes
Lecture 4: Coupled Oscillators, Normal Modes (MIT opencourseware)- Prof. Lee analyzes a highly symmetric system which contains multiple objects. By physics intuition, one could identify a special kind of motion – the normal modes. He shows that there is a general strategy for solving the normal modes.
- Every part of the system is oscillating at the same frequency and the same phase
- Stopped at 42:07 to take a break. I think this is the right track though. Download this for the plane?
- Prof. Lee analyzes a highly symmetric system which contains multiple objects. By physics intuition, one could identify a special kind of motion – the normal modes. He shows that there is a general strategy for solving the normal modes.
- Chapter on normal modes










You must be logged in to post a comment.