
7:00 – 4:30 ASRC MKT
- Some new papers from ICLR 2018
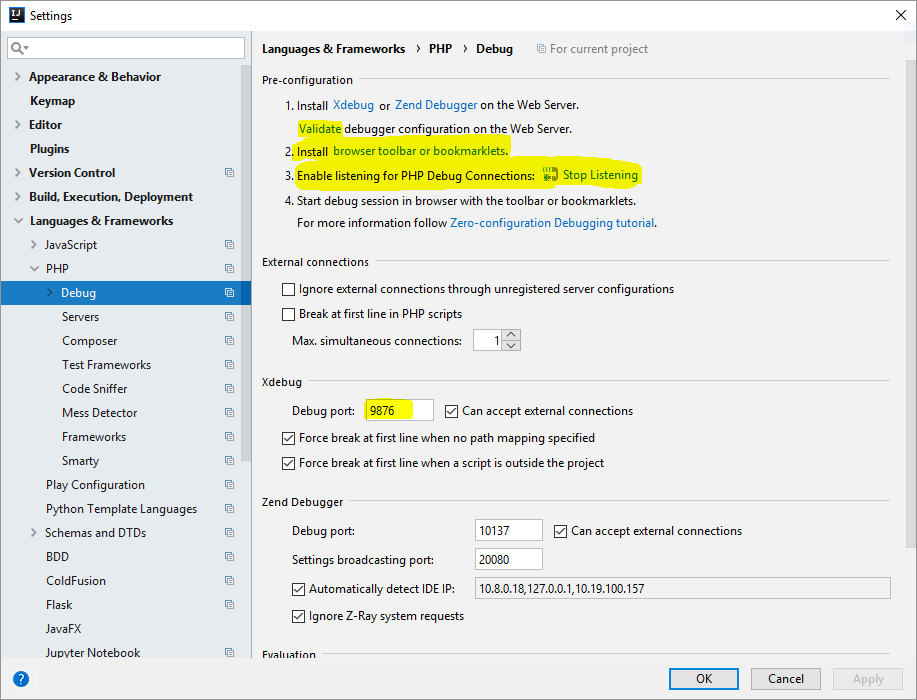
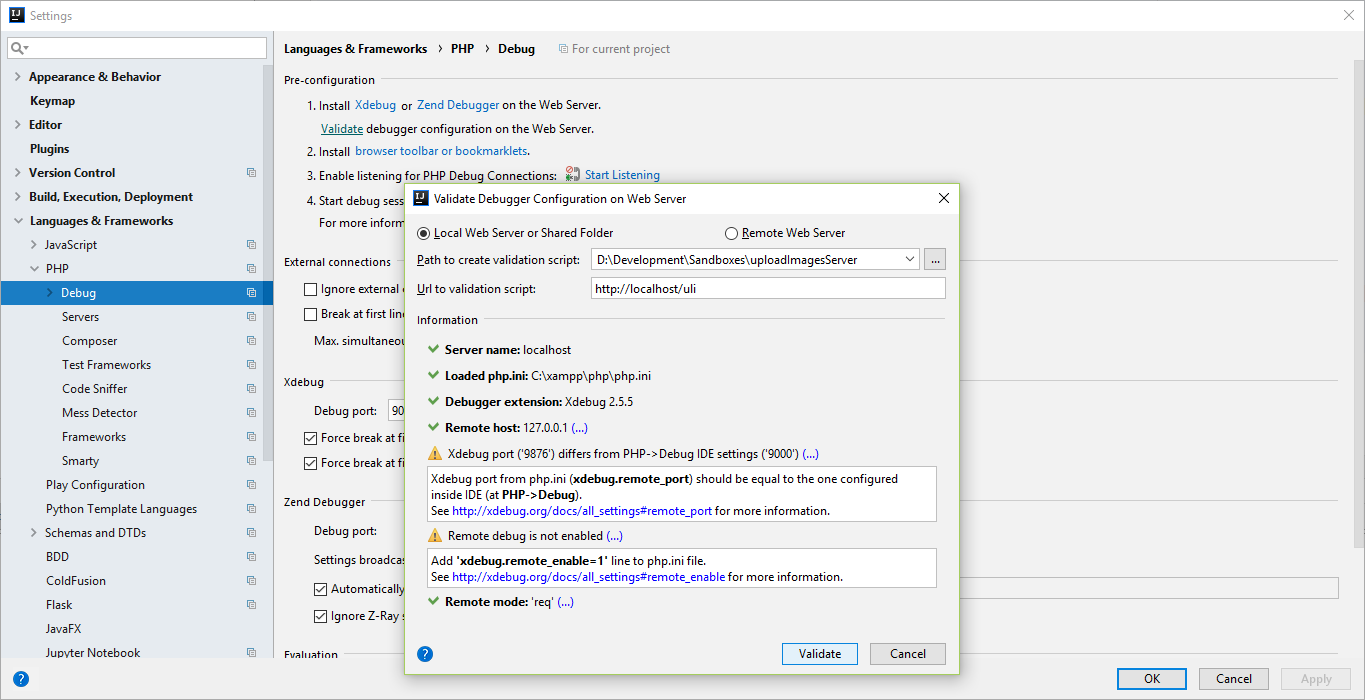
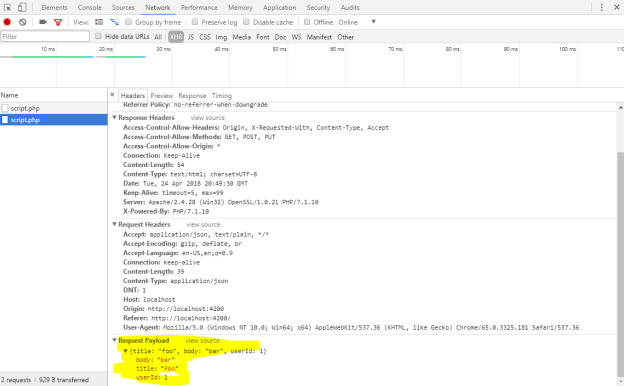
- Need to write up a quick post for communicating between Angular and a (PHP) server, with an optional IntelliJ configuration section
- JuryRoom this morning and then GANs + Agents this afternoon?
- Next steps for JuryRoom
- Start up the AngularPro course
- Set up PHP access to DB, returning JSON objects
- Starting Agent/GAN project
- Need to set up an ACM paper to start dumping things into – done.
- Looking for a good source for Jack London. Gutenberg looks nice, but there is a no-scraping rule, so I guess, we’ll do this by hand…
- We will need to check for redundant short stories
- We will need to strip the front and back matter that pertains to project Gutenburg
- *** START OF THIS PROJECT GUTENBERG EBOOK BROWN WOLF AND OTHER JACK ***
- *** END OF THIS PROJECT GUTENBERG EBOOK BROWN WOLF AND OTHER JACK ***
- Fika: Accessibility at the Intersection of Users and Data
- Nice talk and followup discussion with Dr. Hernisa Kacorri, who’s combining machine learning and HCC
- My research goal is to build technologies that address real-world problems by integrating data-driven methods and human-computer interaction. I am interested in investigating human needs and challenges that may benefit from advancements in artificial intelligence. My focus is both in building new models to address these challenges and in designing evaluation methodologies that assess their impact. Typically my research involves application of machine learning and analytics research to benefit people with disabilities, especially assistive technologies that model human communication and behavior such as sign language avatars and independent mobility for the blind.
- Nice talk and followup discussion with Dr. Hernisa Kacorri, who’s combining machine learning and HCC


 I think it is reasonable to consider this a measure of alignment
I think it is reasonable to consider this a measure of alignment





You must be logged in to post a comment.