
Do today
7:00 – 8:00 Research
- I have a server! tacjour.rs.umbc.edu
- Starting Filter bubbles, echo chambers, and online news consumption
- Seth R. Flaxman – I am currently undertaking a postdoc with Yee Whye Teh at Oxford in the computational statistics and machine learning group in the Department of Statistics. My research is on scalable methods and flexible models for spatiotemporal statistics and Bayesian machine learning, applied to public policy and social science areas including crime, emotion, and public health. I helped make a very accessible animation answering the question, What is Machine Learning?
- Sharad Goel – I’m an Assistant Professor at Stanford in the Department of Management Science & Engineering (in the School of Engineering). I also have courtesy appointments in Sociology and Computer Science. My primary area of research is computational social science, an emerging discipline at the intersection of computer science, statistics, and the social sciences. I’m particularly interested in applying modern computational and statistical techniques to understand and improve public policy.
- Justin M. Rao – I am a Senior Researcher at Microsoft Research. A member of our New York City lab, an interdisciplinary research group combining social science with computational and theoretical methods, I am currently located at company HQ in the Seattle area, where I am also an Affiliate Professor of Economics at the University of Washington.
- Spearman’s Rank-Order Correlation
- Goel, Mason, and Watts (2010) show that a substantial fraction of ties in online social networks are between individuals on opposite sides of the political spectrum, opening up the possibility for diverse content discovery. [p 299]
- I think this helps in areas where flocking can occur. Changing heading is hardest when opinions are moving in opposite directions. Finding a variety of perspectives may change the dynamic.
- Specifically, users who predominately visit left-leaning news outlets only very
rarely read substantive news articles from conservative sites, and vice versa
for right-leaning readers, an effect that is even more pronounced for opinion
articles.- Is the range of information available from left or right-leaning sites different? Is there another way to look at the populations? I think it’s very easy to get polarized left or right, but seeking diversity is different, and may have a pattern of seeking less polarized voices?
- Interestingly, exposure to opposing perspectives is higher for the
channels associated with the highest segregation, search, and social. Thus,
counterintuitively, we find evidence that recent technological changes both
increase and decrease various aspects of the partisan divide.- To me this follows, because anti belief helps in the polarization process.
- We select an initial universe of news outlets (i.e., web domains) via the Open Directory Project (ODP, dmoz.org), a collective of tens of thousands of editors who hand-label websites into a classification hierarchy. This gives 7,923 distinct domains labeled as news, politics/news, politics/media, and regional/news. Since the vast majority of these news sites receive relatively little traffic,
- Still a good option for mapping. Though I’d like to compare with schema.org
- Specifically, our primary analysis is based on the subset of users who have read at least ten substantive news articles and at least two opinion pieces in the three-month time frame we consider. This first requirement reduces our initial sample of 1.2 million individuals to 173,450 (14 percent of the total); the second requirement further reduces the sample to 50,383 (4 percent of the total). These numbers are generally lower than past estimates, likely because of our focus on substantive news and opinion (which excludes sports, entertainment, and other soft news), and our explicit activity measures (as opposed to self-reports).
- Good indicator of explore-exploit in the user population at least in the context of news.
- We now define the polarity of an individual to be the typical polarity of the news outlet that he or she visits. We then define segregation to be the expected distance between the polarity scores of two randomly selected users. This definition of segregation, which is in line with past work (Dandekar, Goel, and Lee 2013), intuitively captures the idea that segregated populations are those in which pairs of individuals are, on average, far apart.
- This fits nicely with my notion of belief space
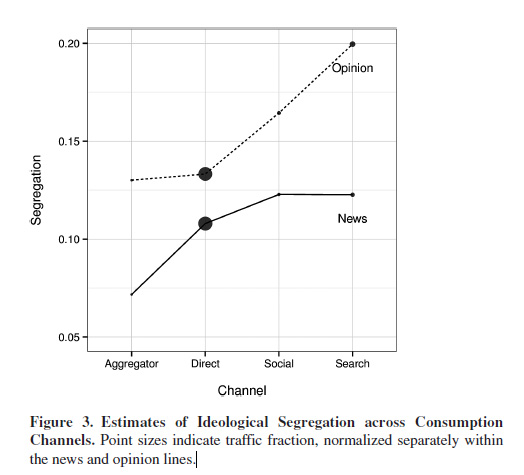
- This is interesting. Figure 3 shows that aggregators and direct (which have some level of external curation, are substantially less polarized than the social and search-based channels. That’s a good indicator that the visible information horizon makes a difference in what is accessed.
- our findings do suggest that the relatively recent ability to instantly query large corpora of news articles—vastly expanding users’ choice sets—contributes to increased ideological segregation
- The frictionlessness of being able to find exactly what you want to see, without being exposed to things that you disagree with.
- In particular, that level of segregation corresponds to the ideological distance between Fox News and Daily Kos, which represents meaningful differences in coverage (Baum and Groeling 2008) but is within the mainstream political spectrum. Consequently, though the predicted filter bubble and echo chamber mechanisms do appear to increase online segregation, their overall effects at this time are somewhat limited.
- But this depends on how opinion is moving. We are always redefining normal. It would also be good to look at the news producers using this approach…?
- This finding of within-user ideological concentration is driven in part by the fact that individuals often simply turn to a single news source for information: 78 percent of users get the majority of their news from a single publication, and 94 percent get a majority from at most two sources. …even when individuals visit a variety of news outlets, they are, by and large, frequenting publications with similar ideological perspectives.

- Although I think focussing on ‘opposing’ rather than ‘diverse’ biases these results, this still shows that populations of users behave differently, and that the channel has a distinct effect.
- …relatively high within-user variation is a product of reading a variety of centrist and right-leaning outlets, and not exposure to truly ideologically diverse content.
- So left leaning is more diverse across ideology
- the outlets that dominate partisan news coverage are still relatively mainstream, ranging from the New York Times on the left to Fox News on the right; the more extreme ideological sites (e.g., Breitbart), which presumably benefited from the rise of online publishing, do not appear to qualitatively impact the dynamics of news consumption.
- This (reasonably) does not take into account how more extreme sites influence the more moderates sites. This could be examined by looking at the outbound links from the channels (NYT pointing to kos, Fox pointing to Breitbart). Some work has been done on this, (though this isn’t peer reviewed): https://medium.com/@d1gi/the-election2016-macro-propaganda-machine-8a283b4e1d24#.xs0j4wxxq
8:30 – 4:00 BRC
- Finished a second pass through the ResearchBrowser white paper
- Thinking about optimal sequential clustering
- A Framework of Mining Semantic Regions from Trajectories
- This also makes me wonder if we should be looking at our patients as angle from mean
- Phase 1 : optimize current algorithm to hillclimb for most cluster and least unclustered by varying EPS for a given cluster minimum
- Phase 2: Do NMF analysis of patient clusters to extract meaningful labels
- Phase 3: Model patient trajectories through diagnosis space




You must be logged in to post a comment.