
Had some kind of power hiccup this morning and discovered that my computer was connected to the surge-suppressor part of the UPS. My box is now most unhappy as it recovers. On the plus side, computer recover from this sort of thing now.
D20
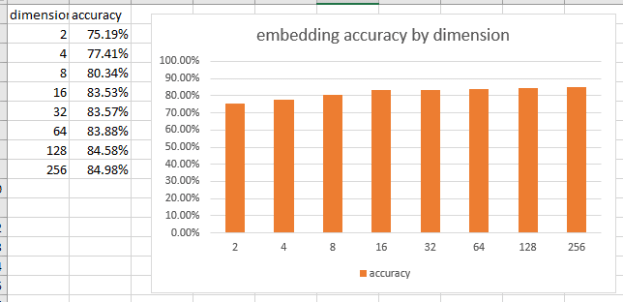
- Fixed the neighbor list and was pleasantly surprised that it worked for the states
GPT-2Agents
- Set up input and output files
- Pull char count of probe out and add that to the total generated
- Start looking into finetuning
- Here are all the hugingface examples
-
export TRAIN_FILE=/path/to/dataset/wiki.train.raw export TEST_FILE=/path/to/dataset/wiki.test.raw python run_language_modeling.py \ --output_dir=output \ --model_type=gpt2 \ --model_name_or_path=gpt2 \ --do_train \ --train_data_file=$TRAIN_FILE \ --do_eval \ --eval_data_file=$TEST_FILE
- run_language_modeling.py source in GitHub
- Tried running without any arguments as a sanity check, and got this: huggingface ImportError: cannot import name ‘MODEL_WITH_LM_HEAD_MAPPING’. Turns out that it won’t work without PyTorch being installed. Everything seems to be working now:
usage: run_language_modeling.py [-h] [--model_name_or_path MODEL_NAME_OR_PATH] [--model_type MODEL_TYPE] [--config_name CONFIG_NAME] [--tokenizer_name TOKENIZER_NAME] [--cache_dir CACHE_DIR] [--train_data_file TRAIN_DATA_FILE] [--eval_data_file EVAL_DATA_FILE] [--line_by_line] [--mlm] [--mlm_probability MLM_PROBABILITY] [--block_size BLOCK_SIZE] [--overwrite_cache] --output_dir OUTPUT_DIR [--overwrite_output_dir] [--do_train] [--do_eval] [--do_predict] [--evaluate_during_training] [--per_gpu_train_batch_size PER_GPU_TRAIN_BATCH_SIZE] [--per_gpu_eval_batch_size PER_GPU_EVAL_BATCH_SIZE] [--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS] [--learning_rate LEARNING_RATE] [--weight_decay WEIGHT_DECAY] [--adam_epsilon ADAM_EPSILON] [--max_grad_norm MAX_GRAD_NORM] [--num_train_epochs NUM_TRAIN_EPOCHS] [--max_steps MAX_STEPS] [--warmup_steps WARMUP_STEPS] [--logging_dir LOGGING_DIR] [--logging_first_step] [--logging_steps LOGGING_STEPS] [--save_steps SAVE_STEPS] [--save_total_limit SAVE_TOTAL_LIMIT] [--no_cuda] [--seed SEED] [--fp16] [--fp16_opt_level FP16_OPT_LEVEL] [--local_rank LOCAL_RANK] run_language_modeling.py: error: the following arguments are required: --output_dirAnd I still haven’t broken my text generation code. Astounding!
-
- Moby Dick from Gutenberg
- Chess
- Covid tweets
- Here’s the cite:
@article{Wolf2019HuggingFacesTS, title={HuggingFace's Transformers: State-of-the-art Natural Language Processing}, author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R'emi Louf and Morgan Funtowicz and Jamie Brew}, journal={ArXiv}, year={2019}, volume={abs/1910.03771} }
- Here are all the hugingface examples
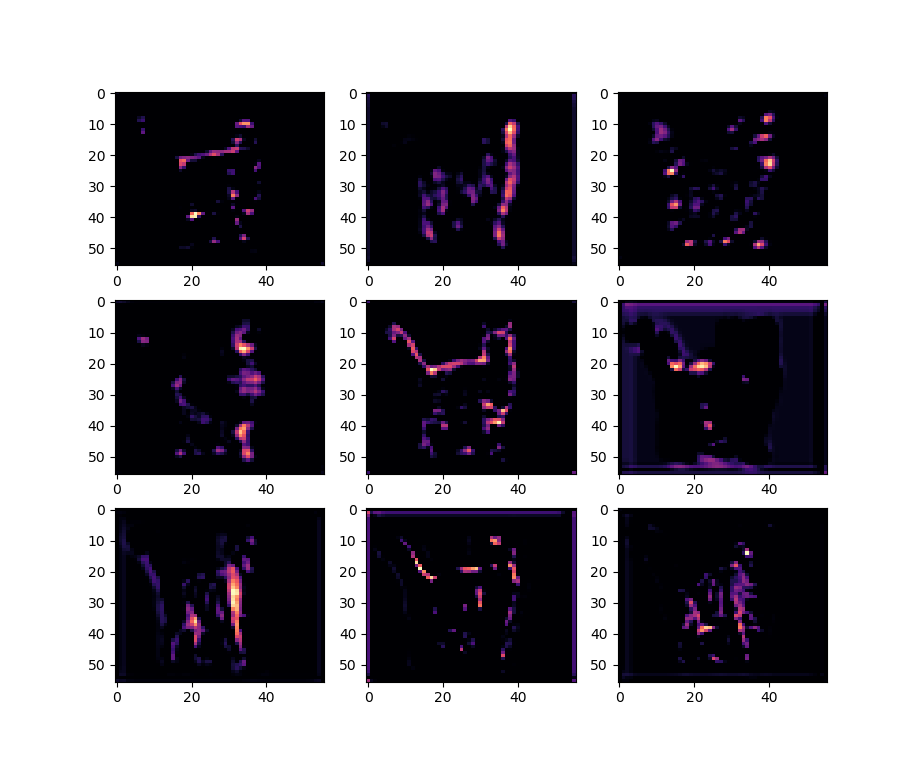
GOES
- Set up meeting with Issac and Vadim for control
- Continue with GAN
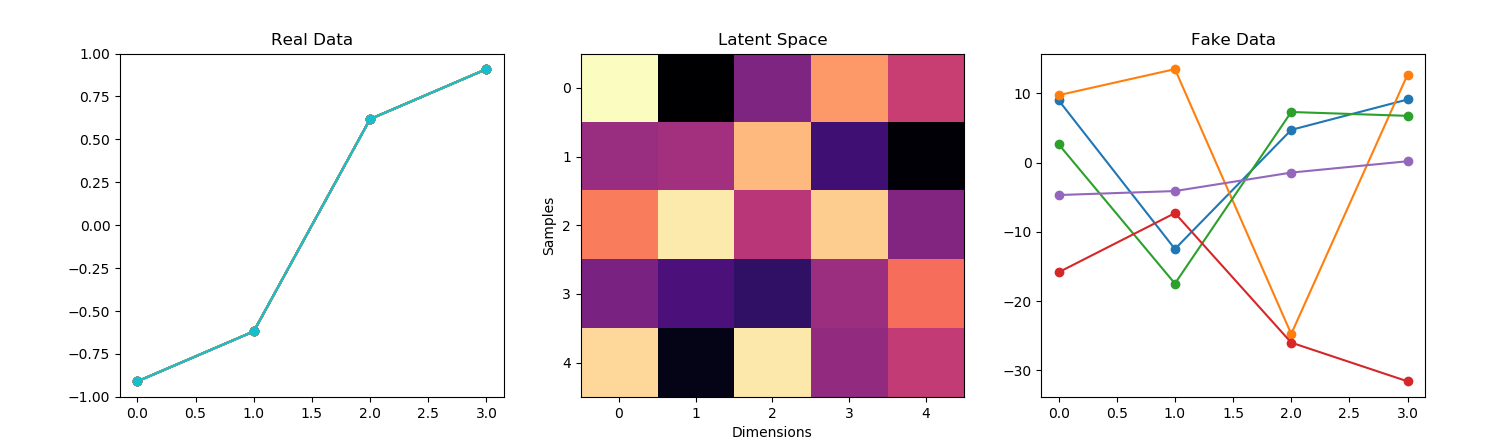
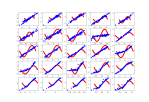
- Struggled with getting training to work for a while. I started by getting all the code to work, which included figuring out how the class labels worked (they just classify “real” vs “fake”. Then my results were terrible, basically noise. So I went back and parameterized the training and real data generation to try it on a smaller vector size. That seems to be working. Here’s the untrained model on a time series four elements long:

- And here’s the result after 10,000 epochs and a batch size of 64:

- That’s clearly not an accident. So progress!
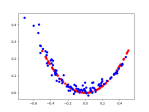
- playing around with options based on this post and changed my Adam value from 0.01 to 0.001, and the output function from linear to tanh based on this random blog post. Better!

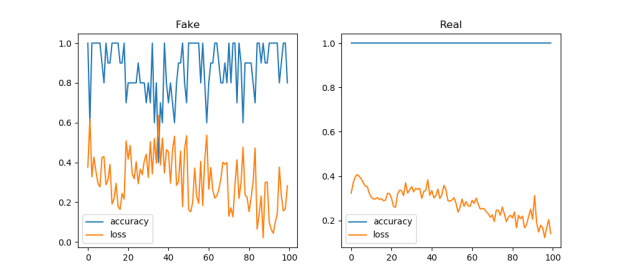
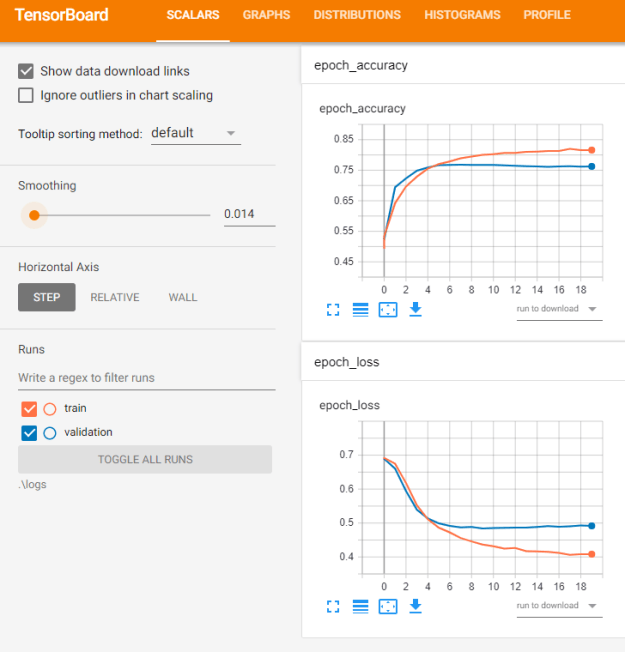
- I do not understand the loss/accuracy behavior though


I think this is a good starting point! This is 16 points, and clearly the real loss function is still improving:

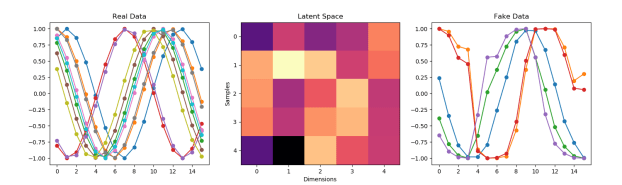
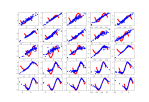
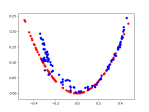
- Adding more variety of inputs:
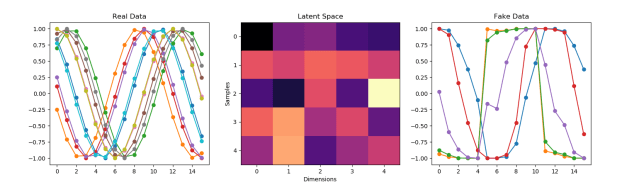
- Trying adding layers. Nope, it generalized to a single sin wave
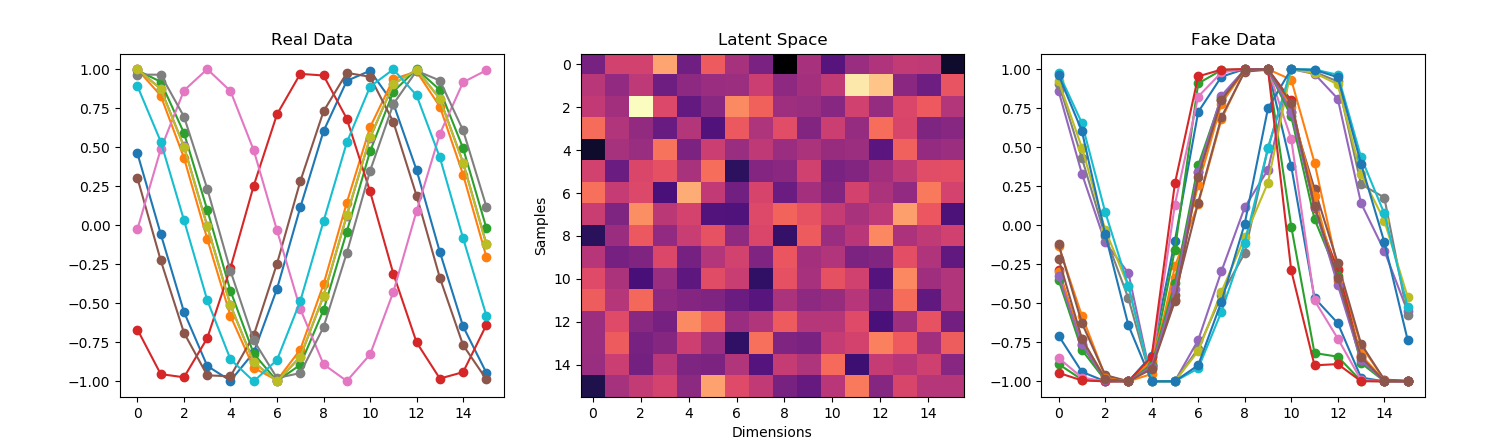
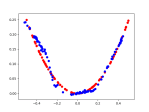
- Trying a bigger latent space of 16 dimensions up from 5:

- Splitting the difference and trying 8. Let’s see 5 again?
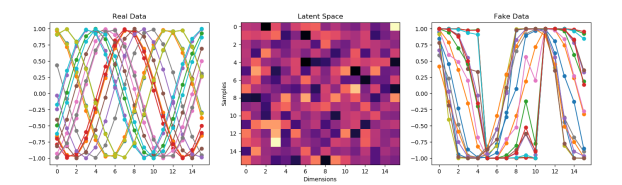
- Hmmm. I think I like the 16 better. Let’s go back to that with a batch size of 128 rather than 64. Better? I think?


- Let’s see what more samples does. Let’s try 100! Bad move. Let’s try 20, with a bigger random offset
- Ok, as a last thing for the day, I’m going to try more epochs. Going from 10,000 to 50,000:


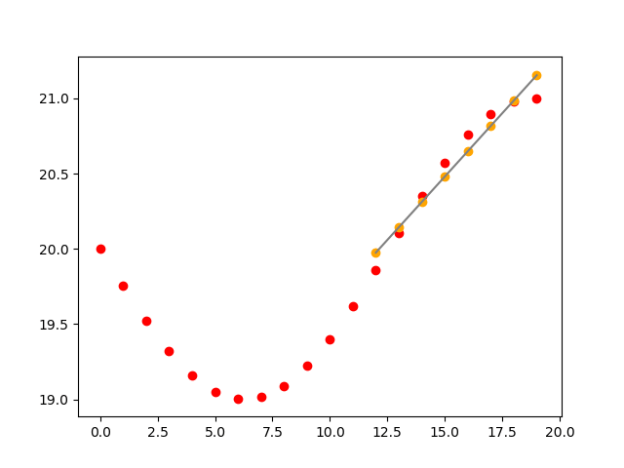
- It definitely finds the best curve to forge. Have to think about that
- Struggled with getting training to work for a while. I started by getting all the code to work, which included figuring out how the class labels worked (they just classify “real” vs “fake”. Then my results were terrible, basically noise. So I went back and parameterized the training and real data generation to try it on a smaller vector size. That seems to be working. Here’s the untrained model on a time series four elements long:
- Status report – done




















You must be logged in to post a comment.