2020 for me, in pictures



2020 for me, in pictures
Last work day of the year.
Still looking at COVID deaths. Here’s what’s going on in a sample of countries as of today

And here are the worst performing states over the duration of the epidemic. Georgia continues to be a mess. Those states at the bottom are coming up fast…
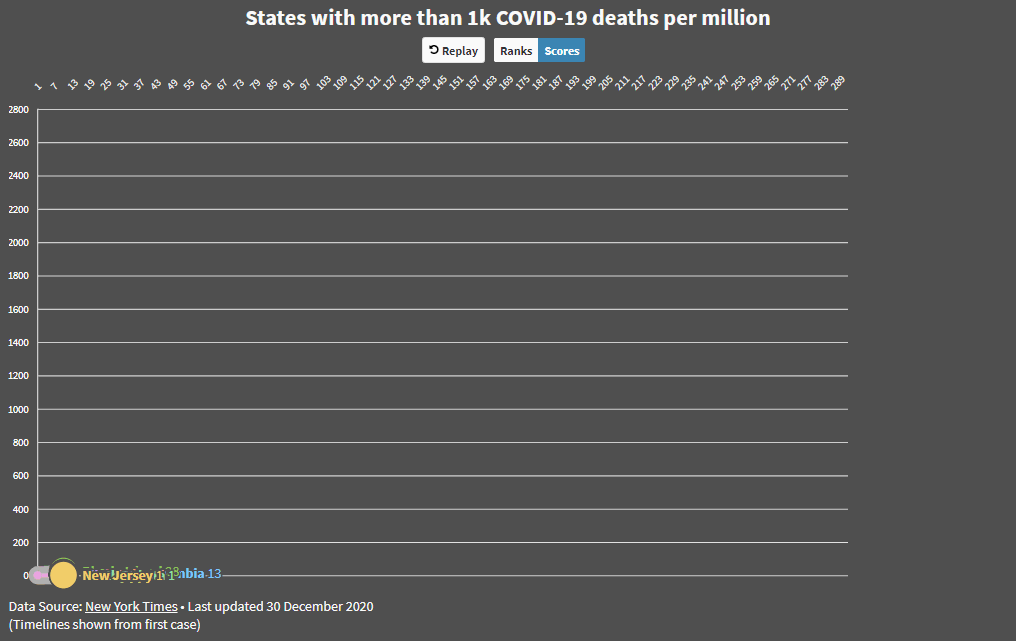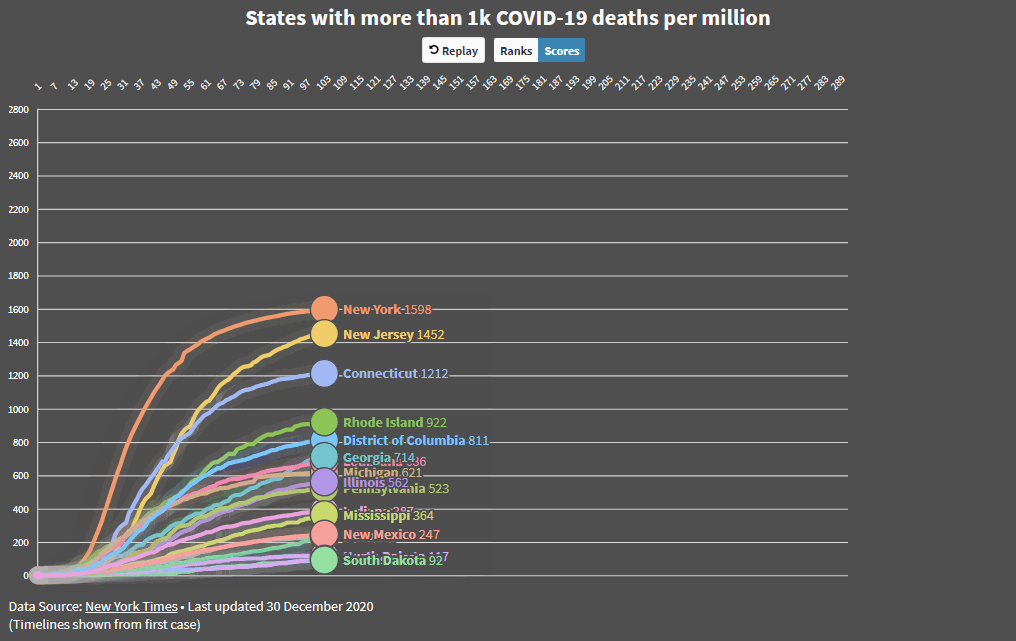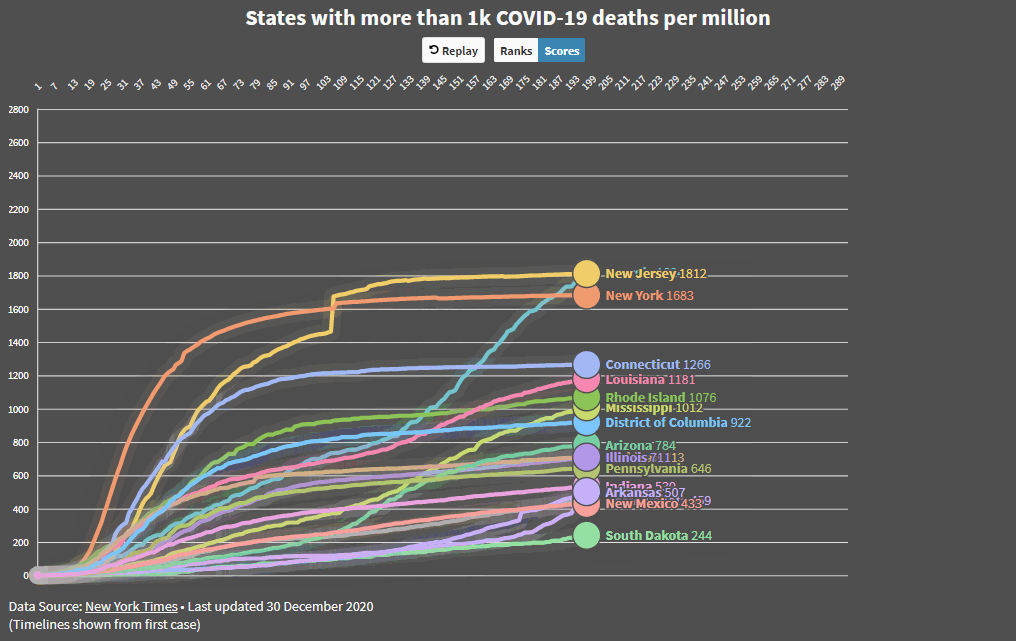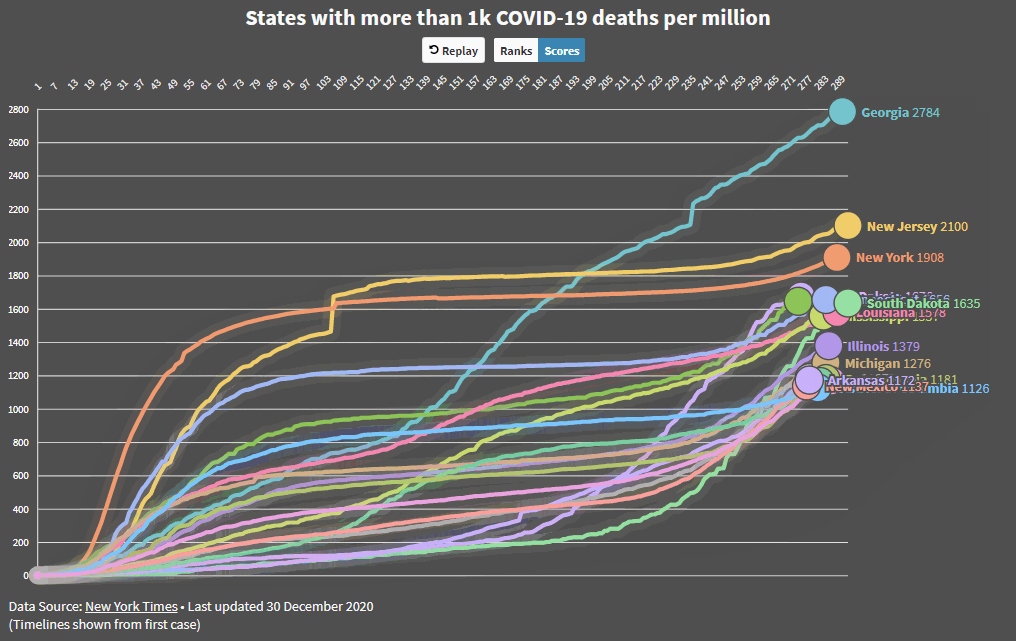
Book
GPT Agents
GOES
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
GPT Agents
create or replace view combined as
select distinct t_1.root_id, t_1.experiment_id, t_1.probe as 'probe', DATE_FORMAT(t_1.content, "%M, %Y") as 'date', t_2.content as 'text'
from table_output as t_1
inner join table_output as t_2
on t_1.root_id = t_2.root_id and t_1.tag = 'date' and t_2.tag = 'trimmed';
Book
It’s the slowest week of the year
GPT Agents
Understanding journalist killings
A very nice set of examples on using mysqldump
GPT Agents
GOES
Next year, this date will be very symmetric. Is it going to be the last palandromic date for a while? like for about 1,000 years?
GPT-2 Agents:
GOES

Book
Solstice! Now the days get longer!
Interfaces for Explaining Transformer Language Models
GPT-2Agents
GOES
Book
It is feeling very dark and wintery as we near the winter solstice.
Struggling to get my changes committed. Sheesh
GPT Agents
GOES
Book
Scraped the ice/snow that fell last night off the driveway
The espresso machine that I thought had been broken turns out to have been a victim of the Trader Joe’s espresso? I had noticed with my hand pump that Wegmans espresso was far easier, so I pulled the machine from the basement and tried it with that. Success! Crema! Life is good.
Book
GOES
ML Group
Snow!
I have broken some of my GPT code. Started upgrading various things, like Tensorflow. The most recent version of Numpy seems to be broken, so I had to install an older version. Also, it looks like it’s time for a CUDA update. Here’s the list of work so far
Book
GOES
MDS SBIR
JuryRoom
Rolls-Royce’s Aletheia Framework is a practical toolkit that helps organizations to consider the impacts on people of using artificial intelligence prior to deciding whether to proceed. It looks across 32 facets of societal impact, governance and trust, and transparency and requires executives and boards to provide evidence that these have been rigorously considered.
10:00 – 1:00 Meeting with Mike D
GPT-Agents
from scipy.spatial.transform import Rotation as R
import numpy as np
kv = we.create_embedding_from_query("select content from table_output where experiment_id = 2 and probe = '{}' and tag = 'tweet';".format(probe), key_list)
# calculate the rotations to map one embedding onto the other
r:R
mapping = False
if len(kv_list) > 0:
kv0 = kv_list[0]
intersect = list(set(kv.index2word) & set(kv0.index2word))
primary = []
secondary = []
for w in intersect:
pi = kv0.index2word.index(w)
si = kv.index2word.index(w)
primary.append(kv0.vectors[pi])
secondary.append(kv.vectors[si])
A, res, rank, s = np.linalg.lstsq(primary, secondary, rcond=None)
r = R.from_matrix(A)
mapping = True
kv_list.append(kv)
GOES

MDS
I’m very conflicted about global warming in the winter. We just had a lovely weekend, where temperatures reached 60F. That’s very bad, but it sure feels nice. Didn’t stop me from getting my annual load of carbon offsets from the UN
GOES
GPT Agents
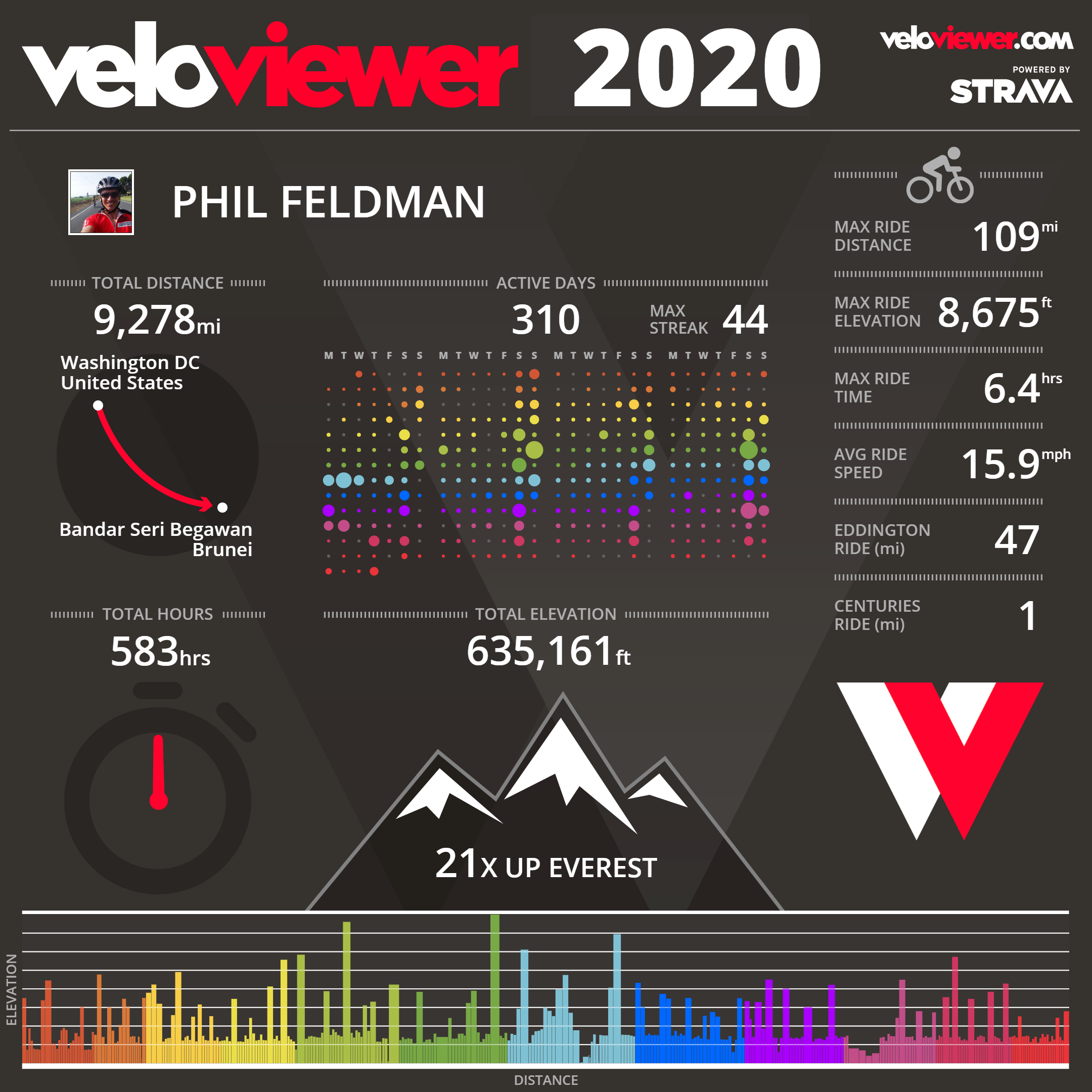
Post this ride for tomorrow
Word embeddings quantify 100 years of gender and ethnic stereotypes (2018 paper)
Book
GOES
app = dash.Dash(__name__, title = 'Interactive!')
GPT-Agents


High-Dimensional Data Analysis with Low-Dimensional Models: Principles, Computation, and Applications (textbook preprint)
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
MORS
Center for Informed Democracy & Social – cybersecurity (IDeaS)
Social Cybersecurity Working Group Focused on:
Glamorous Toolkit is the moldable development environment. It is a live notebook. It is a flexible search interface. It is a fancy code editor. It is a software analysis platform. It is a data visualization engine. All in one.
“The antibody response to the virus has been shown to be transient and these antibodies start to wane after 3 to 4 months,” he said, adding that at 6 months they are “mostly undetectable” in many people who were infected early on in the epidemic,” (via Reuters)
MORS
4:00 Meeting with Matthew?
JuryRoom

You must be logged in to post a comment.