Two major types of aggression, proactive and reactive, are associated with contrasting expression, eliciting factors, neural pathways, development, and function. The distinction is useful for understanding the nature and evolution of human aggression. Compared with many primates, humans have a high propensity for proactive aggression, a trait shared with chimpanzees but not bonobos. By contrast, humans have a low propensity for reactive aggression compared with chimpanzees, and in this respect humans are more bonobo-like. The bimodal classification of human aggression helps solve two important puzzles. First, a long-standing debate about the significance of aggression in human nature is misconceived, because both positions are partly correct. The Hobbes–Huxley position rightly recognizes the high potential for proactive violence, while the Rousseau–Kropotkin position correctly notes the low frequency of reactive aggression. Second, the occurrence of two major types of human aggression solves the execution paradox, concerned with the hypothesized effects of capital punishment on self-domestication in the Pleistocene. The puzzle is that the propensity for aggressive behavior was supposedly reduced as a result of being selected against by capital punishment, but capital punishment is itself an aggressive behavior. Since the aggression used by executioners is proactive, the execution paradox is solved to the extent that the aggressive behavior of which victims were accused was frequently reactive, as has been reported. Both types of killing are important in humans, although proactive killing appears to be typically more frequent in war. The biology of proactive aggression is less well known and merits increased attention.
GPT-2 Agents
Look at topic extraction?
Moving models from the data directory to the model directory and sending them to svn
3:30 Meeting
Action items:
Try translating a few Chinese tweets and comparing them against Google
Continue with topic extraction
GOES
9:00 Meeting with Vadim – good progress. Found an important bug
Our new government is founded upon exactly the opposite idea; its foundations are laid, its corner-stone rests, upon the great truth that the negro is not equal to the white man; that slavery subordination to the superior race is his natural and normal condition. This, our new government, is the first, in the history of the world, based upon this great physical, philosophical, and moral truth.
Working out from the idea that a hierarchy depends on violence or the threat of violence, then all this is justified. You do slavery because you can. And the fact that you can, defines your place as superior in the hierarchy.
So, at the most primal (literally chimpanzee-level), violence is the most basic mechanism to determine hierarchy. Since a good place in the hierarchy has tremendous benefits, it is worth fighting for, and potentially dying for. The flip side of that is also worth killing for. And I think I can see how that can be a stable state for group activity. It could even be viewed as a behavior attractor that is wired into us as a hierarchical species. The balancing act for us is to work out how to not wind up in this state, even though it seems to be an attractive answer, particularly for those who feel as though they are loosing their high place in the hierarchy.
In December of 2019, @sparrow_e2 (7 followers, 250 following) posted a retweet, mentioning @b0_r9. It was sent from Saudi Arabia. @sparrow_e2 wrote: "RT @b0_r9 watch. ♪ Squirrels drowned in #Jeddah ♪ ♪ Now here shows the role ♪ ♪ Study suspension and drainage ♪ https://t.co/m3kIOZ0Gdk". The retweet was categorized as "Neutral".
Started training on the new dataset. Done! Here are some results:
“In December of 2019”
____MZN wrote "The United Arab Emirates today officially announces that the first case of the new Koruna virus has been confirmed, and the Ministry of Health and Social Protection confirms that the health status of the infected is stable and under medical observation.."
“In February of 2020”
ixoG5 wrote "RT @EremNews, a Yemeni student, crying out for not being evacuated and her colleagues from Wuhan, China. She addresses Yemeni officials: If you are unable to protect 180 students, how will you protect a country? #Term_News # Yemen # COVID19 #Coronaviruschina https://t.co/6wcevarxvQ."
“In March of 2020”
____2____2___2 wrote "If God wills, the Corona virus will remain invisible, because there is no way to detect it with the naked eye. God knows that because the veil of the Muslim nation remains the law of the polytheists, that even the hurricanes that hit the earth are not seen by God's wrath.."
“Is corona the will of Allah? “
In February of 2020, @Bader_Zayed wrote "RT @makkahnp Corona virus in China... the death toll rose to 80 and more than 11 thousand infections # Makkah Newspaper https://t.co/lxW8L9uE8X." In February of 2020, @Hn6YmR9cV4H1fv6 wrote "RT @jafarAbdeel A "Chinese Muslim" woman talks about how Muslims in China deal with # Corona disease https://t.co/vzW1dQy2Xm."
In “Measuring and Reducing Gendered Correlations in Pre-trained Models” we perform a case study on BERT and its low-memory counterpart ALBERT, looking at correlations related to gender, and formulate a series of best practices for using pre-trained language models. We present experimental results over public model checkpoints and an academic task dataset to illustrate how the best practices apply, providing a foundation for exploring settings beyond the scope of this case study. We will soon release a series of checkpoints, Zari1, which reduce gendered correlations while maintaining state-of-the-art accuracy on standard NLP task metrics.
#COVID/GPT-2 Agents
Going to generate a new set of text for the Saudi tweets and then do the same for the US set, then start training runs for the weekend
GOES
10:00 Meeting with Vadim
Book
More on cults
Looking at how alpha males influence chimpanzee travel patterns
Finished reading sections on violent cults. The need for an other to react against is really important to motivate extreme behaviors
Reading Goodall on dominance displays and alliances in the Chimpanzees of Gombe. In chimps, this is primarily a male issue, and happens most between males that are close to the same level in the hierarchy as they move up and down. There is often a blend of aggressive displays, violence, submissive behavior, and social activities such as grooming.
One of the most interesting phenomena that occurs with respect to violent displays is something that Goodall calls contagion. It’s when the violence of one male (often towards females) brings in other males who continue and spread the violence.
Stampedes are extreme behavior in low dimensional space. The most obvious example is cattle in a slot canyon that are spooked and can only run one way. Once everyone is moving in the same direction, it can be more dangerous to stop and get trampled than it is to keep on going. As such, stampedes often only stop when they encounter something that is impassible or they exhaust themselves.
But low dimensions don’t have to be physical. As we see in chimpanzee behavior, aggression and violence can become contagious. Just as with cattle in a slot canyon that have to keep running to keep from being trampled, a chimp may need to exhibit aggression and attack a lower-ranked member to keep from being attacked themselves.
In humans, this type of dominance behavior exists in a low-dimensional emotional space of threat, violence, and fear. Because it is such a simple alignment mechanism (do this or we kill you), it can be extremely effective in mass political movements. Arendt’s concept of terror in totalitarian states could be a manifestation of dominance at scale. There are two sides, the dominating and the dominated. They are low dimension in their own ways.
Also something about bullying vs. adversarial herding. Bullying is very low dimensional. It is generally reactive and not reflective. Herding can organize the power of bullying to move populations. It is extremely analytic. Consider the interactions between the Sheppard, the sheepdog, and and the sheep. Herding doesn’t have to be malevolent. It can simply be to sell products like supplements.
GOES
10:00 Meeting with Vadim and Erik. Progress. Hopefully we can start training models soon!
#COVID
Copy the ProbesToFile code over from GPT-2 Agents and try a few tests – Things are working nicely!
“In December of 2019, ”
____MZN wrote "The United Arab Emirates today officially announces that the first case of the new Koruna virus has been confirmed, and the Ministry of Health and Social Protection confirms that the health status of the infected is stable and under medical observation.." ____MZN wrote "The United Arab Emirates today officially announces that the first case of the new Koruna virus has been confirmed, and the Ministry of Health and Social Protection confirms that the health status of the infected is stable and under medical observation.." ____MZN wrote "RT @UAE_BARQ "Global Health": ABA defines the new Corona virus and its modes of transmission." ____MZN wrote "The United Arab Emirates today officially announces that the first case of the new Koruna virus has been confirmed, and the Ministry of Health and Social Protection confirms that the health status of the infected is stable and under medical observation.." ____MZN wrote "The United Arab Emirates today officially announces that the first case of the new Koruna virus has been confirmed, and the Ministry of Health and Social Protection confirms that the health status of the infected is stable and under medical observation.." ____MZN
“In January of 2020, ”
____3____3 wrote "RT @turkistanuzbah #China New Corona virus or Wuhan virus relative to the city from which it was launched is still spreading trains and airport traffic is on hold, the virus has arrived in Thailand, South Korea and America, and the spokesman for the Chinese Ministry of Health is addressing the Chinese: Don't go to Wuhan and no one gets out of Wuhan City. https://t.co/1v1i9h5nCP." ____3____3 wrote "RT @ahakawi Update on the fascism of the new Corona virus in China: Increase in the number of cases to 303 deaths: 6 cases of new regions: Taiwan and Zigging https://t.co/ryOMKChz2p." ____3____3 wrote "RT @Alroeya has reached 830 cases of detail: https://t.co/3WcOtPfHjF #Vision_bla_https://t.co/Q1YbRt7eE1v." ____3____3 wrote "RT @ahakawi Update on the fascism of the new Corona virus in China: Increase in the number of cases to 303 deaths:
“In February of 2020, ”
____10__ wrote "RT @cgtnarabic Chinese Health Committee: We still have to test the new Corona virus and assess the efficiency of the country ' s anti-corona system https://t.co/HfNh7y3t3r." @ahmd_alraaie wrote "RT @SaudiMOH traveling to China here health directions to limit the spread of the new virus Corona # Travel_Health https://t.co/Ln8GiujWtj." @Sultainalalshammari wrote "RT @nippon_ar said the Chinese health authorities confirmed 634 patients after 17 medical workers entered into effective control of the new Corona virus in Hobei Province, the new epicentre of the outbreak in central China, according to the New China News Agency (https://t.co/dj1SQc0bWc)." @i_panda wrote "RT @Hamed_Alali, New China News Agency (Xinhua) - according to a high-level team of experts from the country's National Health Commission-: We do not know the source of the virus, its source is bats or snakes,
“In March of 2020, ”
____M____N___ wrote "The Chinese government has provided 1.9 million yuan (HK$173 million) for the development of the Corona virus. This comes within one of the largest donations ever made by a pharmaceutical company.." ____M____N___ wrote "The Chinese government has provided 1.9 million yuan (HK$173 million) for the development of the Corona virus. This comes within one of the largest donations ever made by a pharmaceutical company.." ____M____N___ wrote "The Chinese government has provided 1.9 million yuan (HK$173 million) for the development of the Corona virus. This comes within one of the largest donations ever made by a pharmaceutical company.." ____M____N___ wrote "The Chinese government has provided 1.9 million yuan (HK$173 million) for the development of the Corona virus. This comes within one of the largest donations ever made by a pharmaceutical company.." ____M____N___ wrote "The Chinese government has provided 1.9 million yuan (HK$173 million) for the development of the Corona virus. This comes within one of the largest donations ever made by a pharmaceutical company.." ____M____N
“In April of 2020, ”
____3____3 wrote "The United Arab Emirates today officially announces that the first case of the new Koruna virus has been recorded, for a Chinese citizen, who has been quarantined in a hospital in Abha, while the rest awaits confirmation by the medical authorities. https://t.co/z7oG4nCp8r." ____3____3 wrote "RT @almasar_om # Path | # China announces a sharp rise in deaths due to the Corona virus # Al-Masar newspaper https://t.co/pCZ9Y5lUy3." ____3____3 wrote "https://t.co/PuJ7tuzpQT." ____3____3 wrote "https://t.co/pPuJ7tuzpQT." ____3____3 wrote "https://t.co/pPuJ7tuzpQT." ____3____3 wrote "RT @moe_gov_sa highlighted questions about the new virus #Korona, and answered by specialists, as part of the awareness campaign launched by the Ministry of Education. https://t.
Work on using the db to create queries from labeled data.
Ok, I spent Waaaaaaaaaaaaaaaaaaayyyyyyyyyy too much on this: $715.35, Stopping the run and using what I have
ML Seminar 3:30 – Went over idea on how to use meta information to make more detailed sentences.
JuryRoom 4:30 – Good discussion. Darcy is going to send out a link and a survey
There is an electric motorcycle dealer in Gaithersburg! cyclemaxusa.com
Your periodic reminder of how badly the Trump administration has handled the pandemic. If Trump had simply implemented, for example, Canada’s policies then he’d be a hero and coasting to re-election.
Update the dev db with the one generated on the laptop – done!
Write an app that creates test/train data in a date-ordered output of the translation table. If a random value is < 0.2, the line goes to a test file, otherwise a train file – running!
Whoops – found that there were a lot of rows that had NULL as the translation. Running those through Google
Training on the smaller model to see how everything works
Train model – training!
Copy the ProbesToFile code over from GPT-2 Agents and try a few tests
Work on using the db to create queries from labeled data
3:00 meeting – just Ashwag. We went over progress and discussed next steps. Once I have a model up, I’ll bundle everything together with directions for TF and Torch for playing with the model
GOES
Still waiting on Vadim – He’s back! Scheduled meeting for tomorrow at 10:00
This is cool: NumPy API on TensorFlow. It will be available in 2.4. I should revisit my simple NN
#COVID
Chunking away on translation. DB search makes it slow
Google Translate prices are really good. free for the first 500k characters, then $20/million chars. On average, that seems to be about $0.003/tweet, or about $20 for 7k. Pretty manageable to build a hybrid tweet translator that tries Huggingface first and falls back to Google
Really sped up the translation by using ORDER BY rather than DISTINCT and updating based on the GUID
Finished and backed up! Tomorrow do a select distinct translations order by date and put into a text file to train a model
GOES
Waiting on Vadim
GPT-2 Agents
3:30 Meeting. Went over the tweet ingestor (SchemaToDb) and the whole process of creating a model. The idea of finding tweets similar to generated tweets and tracing back to users came up, which is both cool and creepy
Book
Still working on dominance, leadership, cults and chimpanzees
Read Goodall on dominance displays and alliances. I think this is the in. Dominance is very low dimension (one or two?) and effective in mass movements. Arendt’s concept of terror in totalitarian states could be a manifestation of dominance at scale. There are two sides, the dominating and the dominated. They are low dimension in their own ways.
Also something about bullying vs. adversarial herding. Bullying is very low dimensional. It is generally reactive and not reflective. Herding can organize the power of bullying to move populations. It is extremely analytic. Consider the interactions between the Sheppard, the sheepdog, and and the sheep. Herding doesn’t have to be malevolent. It can simply be to sell products like supplements.
The goal of the blog post is to give an in-detail explanation of how the transformer-based encoder-decoder architecture models sequence-to-sequence problems. We will focus on the mathematical model defined by the architecture and how the model can be used in inference. Along the way, we will give some background on sequence-to-sequence models in NLP and break down the transformer-based encoder-decoder architecture into its encoder and decoder part. We provide many illustrations and establish the link between the theory of transformer-based encoder-decoder models and their practical usage in 🤗Transformers for inference. Note that this blog post does not explain how such models can be trained – this will be the topic of a future blog post.
JuryRoom
Need to respond to Tony’s email. Talk about how text entropy works at the limit: “all work and no play make Jack a dull boy” at one end and random text at the other. Different populations will produce different probabilities of (possibly the same) words. These can further be clustered using word2vec. Additionally, doc2vec could cluster different rooms.
Book
More work on the Money section. Set up discussion in the emergence section as what happens once money is established
7:00 Drinking with historians is going to cover “patriotism”. This might tie into dimension reduction and cults. Going to see if it’s possible to ask questions
GOES
Still thinking about the hiccup in the calculations. Maybe test for which of the four vectors (X, Y, Z, and combined) that’s closest to the previous vector and choose that?
Finish creativity section in Money, start on Cults
GOES
I think what I want to try is to sum all the vectors, based on the normalized total swept area. That becomes the synthesized rotation vector. Keep that rather than a VecData object.
Well, instead of just keeping the vector, I create and maintain a current_vd VecData object since it has all the rotation math in it. The results are significantly better!
On vacation riding around the Maryland Eastern Shore, but I’m also trying to see if I can connect the ML concept of attention to population scale thinking
Current state-of-the-art machine translation systems are based on encoder-decoder architectures, that first encode the input sequence, and then generate an output sequence based on the input encoding. Both are interfaced with an attention mechanism that recombines a fixed encoding of the source tokens based on the decoder state. We propose an alternative approach which instead relies on a single 2D convolutional neural network across both sequences. Each layer of our network re-codes source tokens on the basis of the output sequence produced so far. Attention-like properties are therefore pervasive throughout the network. Our model yields excellent results, outperforming state-of-the-art encoder-decoder systems, while being conceptually simpler and having fewer parameters.
Good discussion last night. Trying to get Tony to grock that JR runs on two levels, the individual discussion room and the aggregate results of many juries deliberating on the same topic
Had a thought this morning about recording user interactions such as slider behavior and keystroke dynamics. Talked to Darcy a bit about that this morning
GOES
Create an Rwheel class that has all the main components that SimpleRwheels uses and then make it work for any number and orientation of wheels.
Book
Start money section. I used the Speech-to-text tool in Google Docs. I think that may have worked very well. I did a paragraph at a time, edited a bit, then did the next.
Still working on getting Google Translate to work without the os value set (which is misbehaving). This looks to be the answer (from stackoverflow, of course):
# The way I think it should be done
client = language.LanguageServiceClient.from_service_account_json("/path/to/file.json")
# Google seems to want this value set though, for portability across environments?
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="/path/to/file.json"
The most recent Google documentation on this requires a storage object, and then doesn’t show how to use it?
# Explicitly use service account credentials by specifying the private key # file. storage_client = storage.Client.from_service_account_json('service_account.json')
This worked!
from google.cloud import translate_v2 as translate
translate_client = translate.Client.from_service_account_json("credentials.json")
text = u"So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate."
target = "de"
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
print(u"Text: {}".format(result["input"]))
print(u"Translation: {}".format(result["translatedText"]))
print(u"Detected source language: {}".format(result["detectedSourceLanguage"]))
Results:
Text: So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate.
Translation: Beginnen wir also neu - denken wir auf beiden Seiten daran, dass Höflichkeit kein Zeichen von Schwäche ist und Aufrichtigkeit immer einem Beweis unterliegt. Lasst uns niemals aus Angst verhandeln. Aber lasst uns niemals Angst haben zu verhandeln.
Detected source language: en
Here’s the list of supported languages:
Afrikaans (af)
Albanian (sq)
Amharic (am)
Arabic (ar)
Armenian (hy)
Azerbaijani (az)
Basque (eu)
Belarusian (be)
Bengali (bn)
Bosnian (bs)
Bulgarian (bg)
Catalan (ca)
Cebuano (ceb)
Chichewa (ny)
Chinese (Simplified) (zh-CN)
Chinese (Traditional) (zh-TW)
Corsican (co)
Croatian (hr)
Czech (cs)
Danish (da)
Dutch (nl)
English (en)
Esperanto (eo)
Estonian (et)
Filipino (tl)
Finnish (fi)
French (fr)
Frisian (fy)
Galician (gl)
Georgian (ka)
German (de)
Greek (el)
Gujarati (gu)
Haitian Creole (ht)
Hausa (ha)
Hawaiian (haw)
Hebrew (iw)
Hindi (hi)
Hmong (hmn)
Hungarian (hu)
Icelandic (is)
Igbo (ig)
Indonesian (id)
Irish (ga)
Italian (it)
Japanese (ja)
Javanese (jw)
Kannada (kn)
Kazakh (kk)
Khmer (km)
Kinyarwanda (rw)
Korean (ko)
Kurdish (Kurmanji) (ku)
Kyrgyz (ky)
Lao (lo)
Latin (la)
Latvian (lv)
Lithuanian (lt)
Luxembourgish (lb)
Macedonian (mk)
Malagasy (mg)
Malay (ms)
Malayalam (ml)
Maltese (mt)
Maori (mi)
Marathi (mr)
Mongolian (mn)
Myanmar (Burmese) (my)
Nepali (ne)
Norwegian (no)
Odia (Oriya) (or)
Pashto (ps)
Persian (fa)
Polish (pl)
Portuguese (pt)
Punjabi (pa)
Romanian (ro)
Russian (ru)
Samoan (sm)
Scots Gaelic (gd)
Serbian (sr)
Sesotho (st)
Shona (sn)
Sindhi (sd)
Sinhala (si)
Slovak (sk)
Slovenian (sl)
Somali (so)
Spanish (es)
Sundanese (su)
Swahili (sw)
Swedish (sv)
Tajik (tg)
Tamil (ta)
Tatar (tt)
Telugu (te)
Thai (th)
Turkish (tr)
Turkmen (tk)
Ukrainian (uk)
Urdu (ur)
Uyghur (ug)
Uzbek (uz)
Vietnamese (vi)
Welsh (cy)
Xhosa (xh)
Yiddish (yi)
Yoruba (yo)
Zulu (zu)
Hebrew (he)
Chinese (Simplified) (zh)
Here’s round-tripping to Arabic:
from google.cloud import translate_v2 as translate
translate_client = translate.Client.from_service_account_json("path_to_credentials_file.json")
text = u"So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate."
target = "ar"
source = "en"
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
print(u"Text: {}".format(result["input"]))
print(u"Translation: {}".format(result["translatedText"]))
print(u"Detected source language: {}".format(result["detectedSourceLanguage"]))
text = u"{}".format(result["translatedText"])
result = translate_client.translate(text, target_language=source)
print(u"Text: {}".format(result["input"]))
print(u"Translation: {}".format(result["translatedText"]))
print(u"Detected source language: {}".format(result["detectedSourceLanguage"]))
Results:
Text: So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate.
Translation: لذلك دعونا نبدأ من جديد - نتذكر على الجانبين أن الكياسة ليست علامة ضعف ، وأن الإخلاص يخضع دائمًا للإثبات. دعونا لا نتفاوض بدافع الخوف. ولكن دعونا لا نخشى للتفاوض.
Detected source language: en
Text: لذلك دعونا نبدأ من جديد - نتذكر على الجانبين أن الكياسة ليست علامة ضعف ، وأن الإخلاص يخضع دائمًا للإثبات. دعونا لا نتفاوض بدافع الخوف. ولكن دعونا لا نخشى للتفاوض.
Translation: So let's start over - remember on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let's not negotiate out of fear. But let's not be afraid to negotiate.
Detected source language: ar
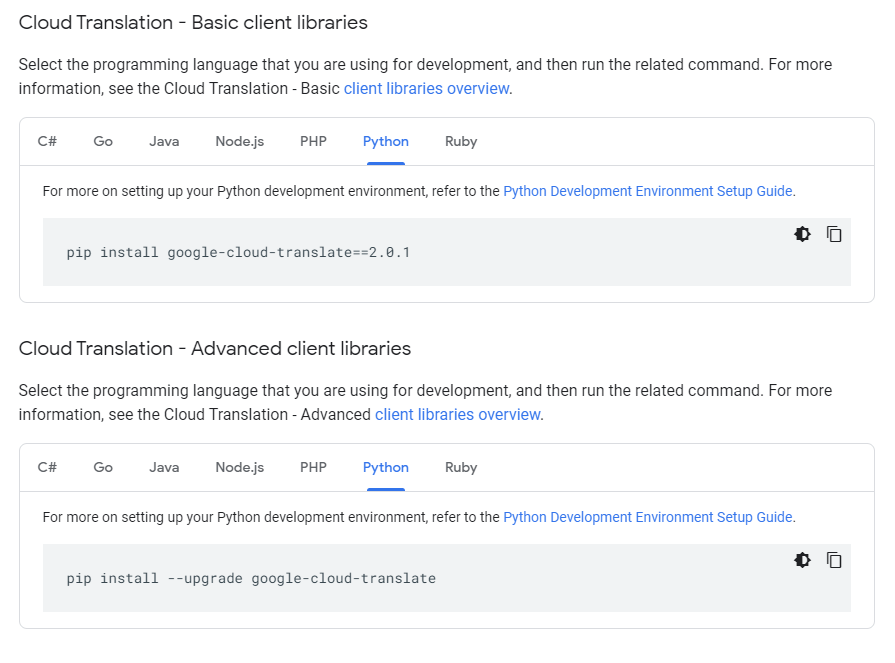
Note that I could get this working with V2, but not V3. I am not sure that I’ve done the following install though, and I’m kinda afraid to break things
pip install --upgrade google-cloud-translate
GOES
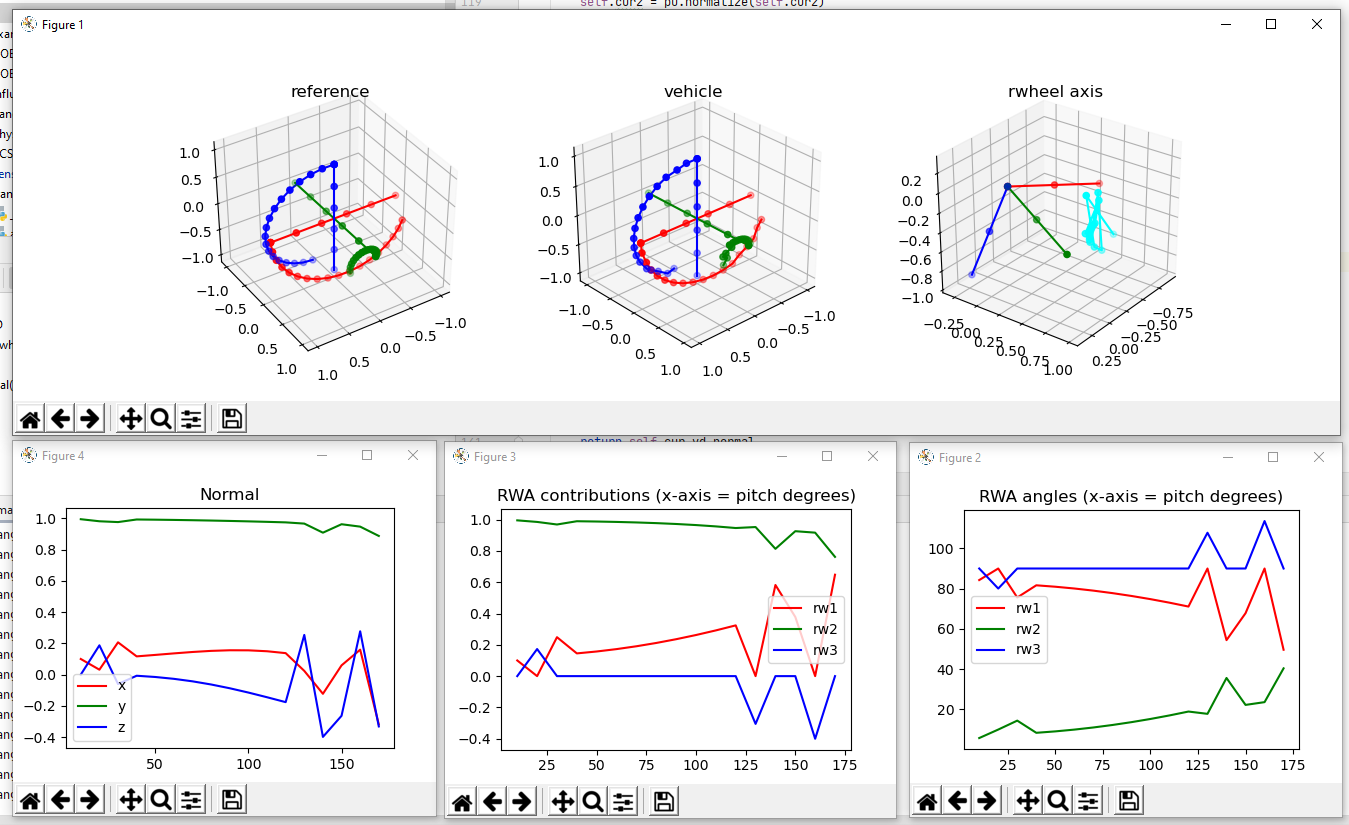
More working through the algorithm. I want to make plots for the normal (rotation) vector to see how that looks. That could also be plotted in 3D. Hmmm.
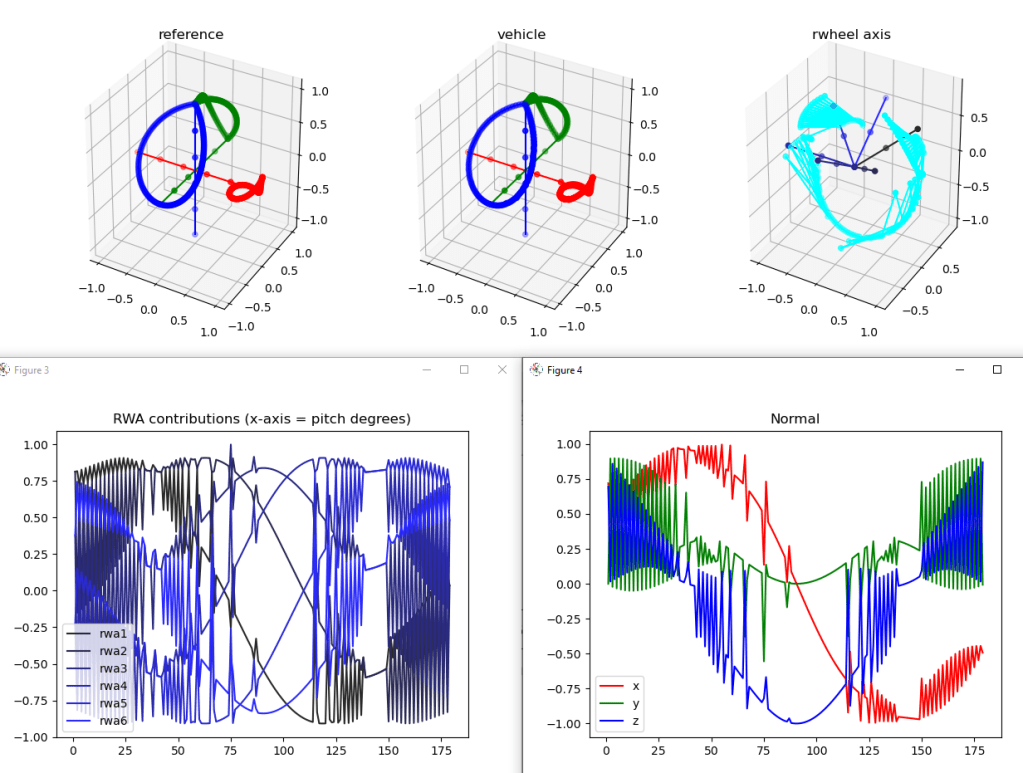
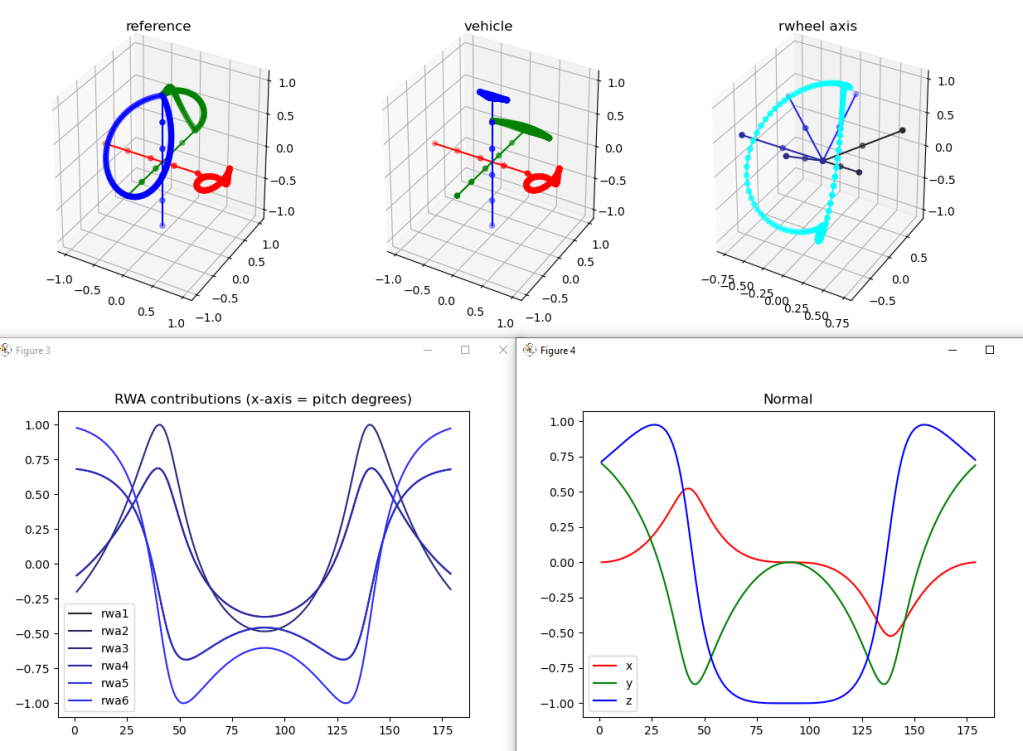
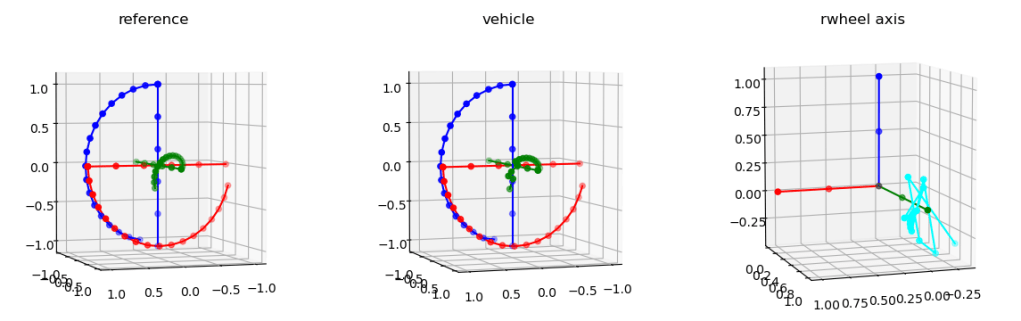
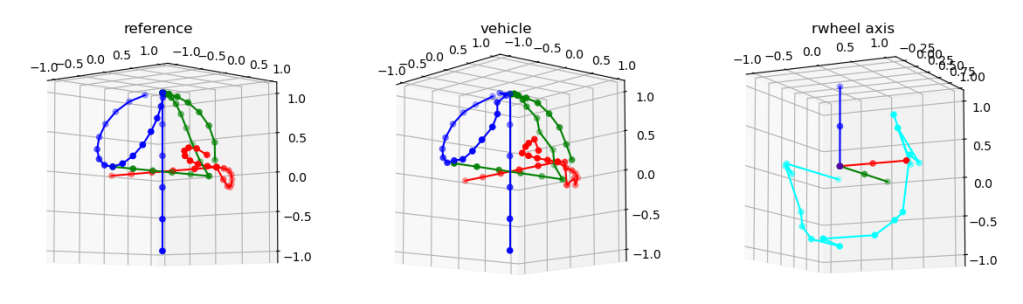
So that’s done, and it’s not as smooth as it should be. Here’s the reference frame rotated through 180 degrees on the left, the matching rotation in the middle, and the simplified reaction wheels with the rotation axis (cyan) on the right:
That cyan plot really bothers me. The results aren’t bad (vehicle), but I wonder if it’s because there are two choices that are equally good and it’s alternating between them? Let’s print out the name of the axis and the runner’s up (sorted by angle):
x angle = -1.00, y angle = -1.00, z angle = -1.00
z angle = 10.05, x angle = 10.03, y angle = 1.41
x angle = 10.11, z angle = 10.05, y angle = 2.02
z angle = 10.27, x angle = 9.95, y angle = 2.69
z angle = 10.03, x angle = 9.97, y angle = 1.87
z angle = 10.02, x angle = 9.96, y angle = 2.10
z angle = 10.00, x angle = 9.92, y angle = 2.25
z angle = 9.99, x angle = 9.85, y angle = 2.32
z angle = 9.96, x angle = 9.76, y angle = 2.34
z angle = 9.94, x angle = 9.66, y angle = 2.40
z angle = 9.91, x angle = 9.57, y angle = 2.59
z angle = 9.88, x angle = 9.54, y angle = 3.00
z angle = 9.85, x angle = 9.61, y angle = 3.67
x angle = 9.81, z angle = 9.81, y angle = 4.60
z angle = 11.31, x angle = 9.32, y angle = 6.58
z angle = 9.73, x angle = 9.45, y angle = 4.32
x angle = 9.90, z angle = 9.69, y angle = 5.66
z angle = 11.64, x angle = 9.10, y angle = 7.57
The x and z axis are almost identical. Would it make sense to average the closest? Let’s try something more extreme:
x angle = -1.00, y angle = -1.00, z angle = -1.00
y angle = 14.11, z angle = 14.11, x angle = 12.82
z angle = 20.31, x angle = 17.04, y angle = 14.19
y angle = 17.53, z angle = 13.48, x angle = 13.01
z angle = 14.25, y angle = 13.54, x angle = 6.81
y angle = 13.78, z angle = 12.22, x angle = 6.76
z angle = 12.27, y angle = 10.56, x angle = 6.80
z angle = 10.82, y angle = 8.63, x angle = 7.64
z angle = 10.29, x angle = 9.36, y angle = 6.14
x angle = 10.28, z angle = 10.00, y angle = 3.70
z angle = 9.85, x angle = 9.85, y angle = 3.70
z angle = 10.29, x angle = 8.94, y angle = 5.09
z angle = 10.82, y angle = 8.09, x angle = 7.32
z angle = 11.50, y angle = 10.74, x angle = 5.69
y angle = 13.27, z angle = 12.22, x angle = 6.12
y angle = 13.54, z angle = 13.02, x angle = 4.16
y angle = 14.09, z angle = 13.21, x angle = 6.16
z angle = 15.23, y angle = 14.19, x angle = 12.12
10:00 Meeting with Vadim. Went over the code and found that the angle calculation only works properly between two unit (vectors of the same length?). That fixed the contribution problems I was having. So that’s one serious bug fixed. Vadim is going to look at folding in the changes, and I’m going to work on getting this to work with the six reaction wheel version.
Creating a list of distinct content that translated to “elderman”. Going to see if I can get the Google Translate API to deal with these problem children
Installing the python libraries for google translate
Because I love pain, upgraded tensorflow. Let’s see if anything still works! It does! At least for translation and GPT, which is good enough for me at the moment
Working on getting the translate API running
GPT-2 Agents
The paper’s submitted!
Had a good chat with Shimei and Sim last night. The db has been uploaded, and we talked about next steps. I also showed how to install the Huggingface transformers library from source. That involved uninstalling the Typing library for some reason. Seems there are conflicts?
Updated my DaysToZero code to put charts into the spreadsheet, which was pretty straightforward using xlsxwriter. There do seem to be three basic patterns:
The first is steady growth:
So no curve flattening here. The disease is moving pretty steadily through the population. The USA is mostly on this track as are countries like India and Chile. I think the difference that we see is related to a first, faster wave among the more vulnerable populations.
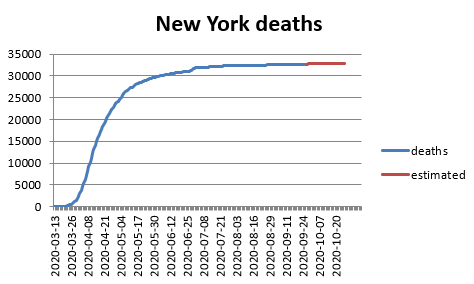
The second pattern is the ‘flattened curve’. Ireland shows this really well, as does New York state:
The last pattern is the ‘second wave’ pattern. Japan seems to be having one now:
So it looks like we are far from out of the woods on this, and letting your guard down is soundly punished.
#COVID
Start the db to fixing “elderman” posts. Running. I’ve got about 100k bad posts. The fixes seem to be taking care of some. This is going to require multiple passes
GOES
2:00 Meeting with Vadim
GPT-2 Agents
Updated the document. Antonio’s going to submit. Fingers crossed! It would be nice to go to London in May
3:30 meeting?
Need to backup and save the db. Done. It’s almost 11GB! Compressing. Backed up the compressed version, which is (only!) 3GB.













You must be logged in to post a comment.