
GOES
- All hands meeting at noon
- Tag-team coding with Vadim – good progress. More tomorrow
- Make slides for T in the GPT-2 Agents IRAD – done?
GPT-2 Agents
- Finished updates to paper. The results are kind of cool. Here’s the error rate by model
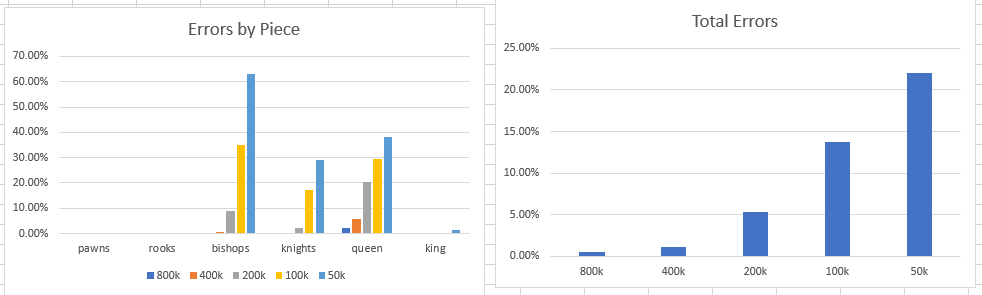
- It’s pretty clear from looking at the charts is the ability of the model to learn legal moves is proportional to the size of the corpora. These are complicated rules, particularly for knights, bishops, and the queen. There needs to be a lot of examples in the text.
- On the other hand, let’s look at overall percentage of moves by piece when compared to human patterns:
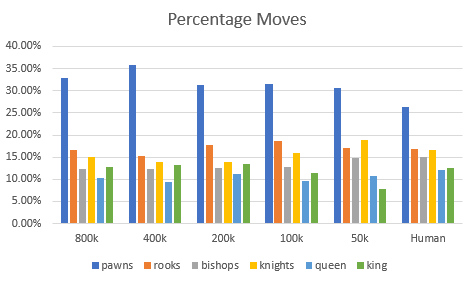
- The overall patterns are substantially the same. Here’s the 2-tailed correlation:

- There really is no substantial difference. To me that means that the low-frequency(?) information makes it into the model with this kind of thematic information with less text. Kinda cool!
- JSON parser
- Got the code working to grab the right files and read them:
for filename in glob.glob('*.jsonl', recursive=True):
trimmed = re.findall(r"\\\d+_to_\d+", filename)
print("{}/{}".format(filename, trimmed))
with open(filename) as f:
jobj = json.load(f)
print(json.dumps(jobj, indent=4, sort_keys=True)) - Working on the schemas now
- It looks like it may be possible to generate a full table representation using two packages. The first is genson, which you use to generate the schema. Then that schema is used by jsonschema2db, which should produce the tables (This only works for postgres, so I’ll have to install that). The last step is to insert the data, which is also handled by jsonschema2db
- Schema generation worked like a charm
- Postgres and drivers are installed. That’s enough good luck for the day
- Got the code working to grab the right files and read them:
ML seminar
- The Language Interpretability Tool:Extensible, Interactive Visualizations and Analysis for NLP Models
- how to get word embedding vector in GPT-2 #1458
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained('gpt2') # or any other checkpoint
word_embeddings = model.transformer.wte.weight # Word Token Embeddings
position_embeddings = model.transformer.wpe.weight # Word Position Embeddings
Book?
