Every morning, I get up, put something mellow on the stereo and do my morning things. So, like every morning I push the power button on the amp, there’s a slight scratching sound, and… nothing. Blown fuse. Sigh. Nothing like looking for a 5mf 8a 125v glass fuse at 5:00am
Spent too much time making a better placeholder callback:
def implement_me(self):
"""
A callback to point to when you you don't have a method ready. Prints "implement me!" to the output and
an abbreviated version of the call stack to the console
:return:
"""
#self.dprint("Implement me!")
self.dp.dprint("Implement me! (see console for call stack)")
fi:inspect.FrameInfo
count = 0
for fi in inspect.stack():
filename = re.split(r"(/)|(\\)", fi.filename)
print("Call stack[{}] = {}() (line {} in {})".format(count, fi.function, fi.lineno, filename[-1]))
count += 1
9:15 Standup
Aaron has topic clustering working:
GPT Agents
Put together a doc with existing and new prompts (“Vaccines are”, “Vaccines are a”, “I/We/<other groups> think that vaccines are”)
I need to do some research on if the API can really do this, but I’d like to make the new corpus of threadedtweets that are pulled because they mention general terms like “COVID”, “VIRUS”, and “VACCINE”, then train the models and drill down. I still like the idea of training monthly models starting in Nov 2019 to present.
Got the paper submitted last Saturday! April 7 is when we’ll find out
4:30 Meeting. We worked on what to do next. We are going to look at the monthly models from 2020 and see how their responses move with respect to embedding space and the same prompt. The first step is to collect the prompts we used from the paper and see if we want to add any new ones
SBIRs
9:15 Sprint planning. Need to write up some stories
compute an error metric (L1 difference) for the estimated proportion of positive reviews for “gray bars” (GPT with the reviews containing the keywords held out) vs the ground truth “blue bars” . Report this error metric in a table (performance of our method). – done
simulate the empirical count baseline method in the low data scenario: draw a small number of reviews containing the keyword, let’s say 6 of them). Compute the error metric (L1 difference) for the empirical counts baseline, computed on this subset, vs the ground truth “blue bars”. Repeat this many times (say, 10,000 times). Report the average error metric in a table (performance of the baseline method). – done
Finished the data extraction. Now I have to make spreadsheets and charts.
Very happy with this:
Fix the TODOs – Done
The last thing to do is fill out the ethics form and submit
Continue on interpolation section. Set up the pretrained average stars in a table and drop the figure. Show the bar chart and Pearson’s
Add comparison of GPT and GPT(v). Chart? Table? And show Pearson’s
1:00 – 2:30 Meeting
Good progress. I need to do for the three star rating category:
compute an error metric (L1 difference) for the estimated proportion of positive reviews for “gray bars” (GPT with the reviews containing the keywords held out) vs the ground truth “blue bars” . Report this error metric in a table (performance of our method).
simulate the empirical count baseline method in the low data scenario: draw a small number of reviews containing the keyword, let’s say 6 of them). Compute the error metric (L1 difference) for the empirical counts baseline, computed on this subset, vs the ground truth “blue bars”. Repeat this many times (say, 10,000 times). Report the average error metric in a table (performance of the baseline method).
Finished the data extraction. Now I have to make spreadsheets and charts
I think I want to put the results into three sections: 1) Memorization, or the learning of the meta-wrapper, 2) Interpolation, or how the model re-creates correct reviews 3) Extrapolation, how the model creates new (zero shot) reviews
Add a section to the beginning of the methods section stating that all finetuning was done on the Huggingface GPT-2 117M parameter model.
For speed (easier to produce a model for comparison)
For the environment
To show that state-of-the art insight into TLMs does not require building large models
I think that a good way to show how this matters is to use TTestIndPower to calculate the minimum sample size to determine if the populations are different as described in this tutorial
Write up the points from the discussion with Aaron last Friday. I think it will make a much better direction than trying to figure out how to automate the current manual approach
Continue code cleanup. There is still something that makes the radius of a MoveableNode grow wrong when the item count is incremented (maybe fixed? Line 34 of in MapData.Maptopic.adjust_force_node())
GPT Agents
Start writing the paper and see what shakes out
Ask to reschedule Tuesday’s meeting – done
Book
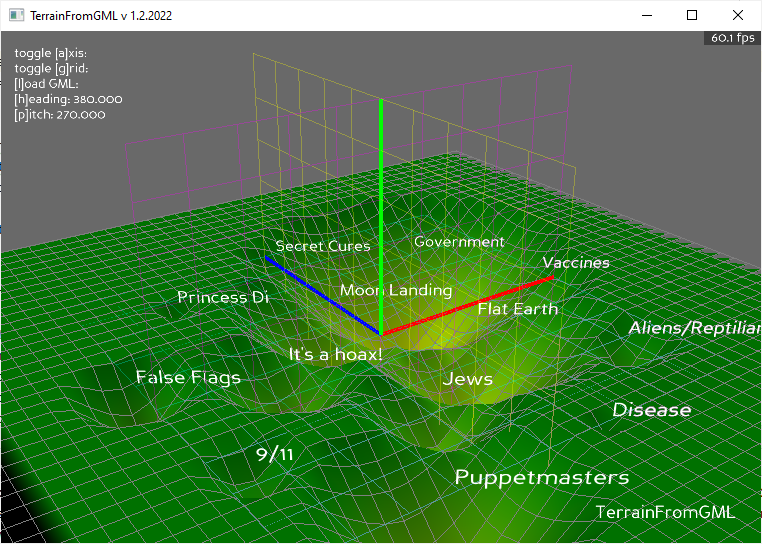
I got a visualization that I like. Now I need to rewrite the chapter a bit around it. I think just the main visualization should be ok, with maybe different perspectives?
The new conspiracy map
Maybe also generate a “philosophy” terrain? I’d need to have some code to handle a rollover for the z value
It snowed again! I think that’s more snow in one week than the past two years
GPT Agents
Need to compare the performance of each model for each probe and compare to ground truth. One thing to point out is how little data there is to sample:
SBIRs
Fixing the “find matching”
Make node size log-based
Book
Put together some more data. Need to change the maps a bit
We evaluate OTS and custom methods on the following datasets. While some of these datasets have common targets, for example, Trump is present in four of them, they are all collected in different periods of time, with different keywords (c.f Appendix B). All datasets have stance labels of ‘favor’, ‘against’, and ‘none’ towards the targets. (EMNLP)
Finished with generating the new data, now we get to see if it works!
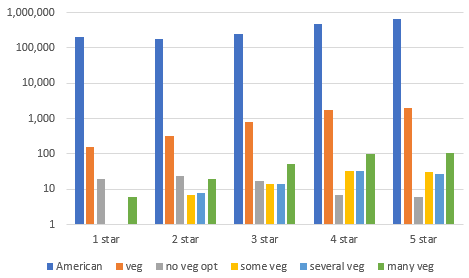
It’s pretty good. Here’s the two GPT models, one trained on the first 50k reviews of the American dataset (iso) and the other trained on the first 50k of the American dataset that do not contain the string “vegetarian options”. The probes are:
no vegetarian options
some vegetarian options
several vegetarian options
many vegetarian options
Basically identical
Now I need to compare the response vs the ground truth for each of the probes
Jamie Raskin just released a book that apparently has some overlap with my work? Trying to track it down. Here’s something from CBS
GPT Agents
Creating unistar models from the corpora that have ‘vegetarian options’ removed. As they are trained, I’m also generating responses to the vegetarian prompts that I’ll do the star and unigram compares with. Then put that in a table and write the paper around it. Also, add the Floober part or something fanciful.
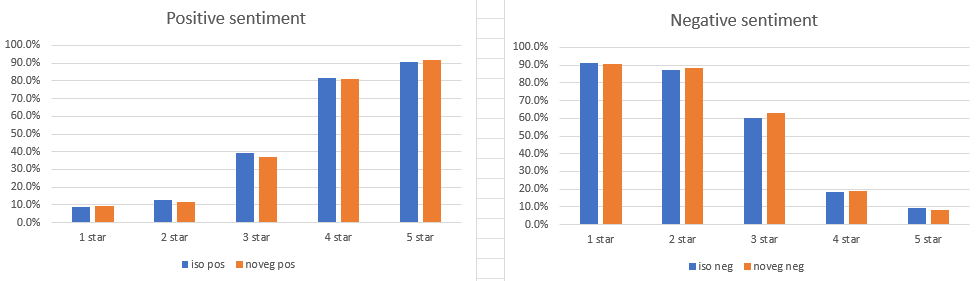
Models are all created. Finished running the first two and am now adding sentiment to them
SBIRs
Continue code cleanup and documenting. I managed to remove a good deal of code that had to do with handing raw text selection of topics, since that seems to be broken in tk
Finished commenting QueryFrame. Now I need to fix that listing problem in on_link_existing_clicked()
It got really cold last night and I had forgotten to turn the water off to the outside and lost the faucet on the deck. Could have been worse. At least the pipes didn’t burst
Thinking about submitting a writeup on Sanhedrin 17a (Section 10.4 of the dissertation. Mostly) for the We Robot conference
Abstracts due: March 7
Decisions: May 9
Final papers due: August 8
Book
Playing around with negative scalars to see how that works. This resulted in some code cleanup and a better color gradient. Not sure if it looks better though:
Still like this better:
SBIRs
Sprint planning
Working on code cleanup for MabBuilder. First, adding comments!
Fixed the exit condition that happened when clicking the ‘X’ close icon in the text compare popup
Next, check through all the button behavior in QueryFrame
Set Group
Add Topic/Seed
Add Topic
Add Seed
Find Closest (and dialog)
Add Group
Next Seed
Rerun Seed
Get Topic Details
Direct Prompt
Wikipedia
Link Existing (make this work with descending length topics)
GPT Agents
3:30 Meeting. Going to make some models that explicitly are missing the phrase ‘vegetarian options’ from the training corpora. I’ll then run those as to compare to ‘vegetarian options’ in the ground truth by star and the other GPT models
Get the number of POSITIVE and NEGATIVE sentiment for each isolated model and compare to ground truth. Make a chart and add to the draft. This is the part that shows that creating models for a population captures that population’s patterns, and that this method is more accurate and reliable than assuming that one general model has all the information needed in an accessible way. Done















You must be logged in to post a comment.