Respond to Dave’s email. I think setting up a pipeline is a great idea actually, as long as it starts with mocks
Combinatorial explosion used to reside in the decision process. Now that’s a trained NN that inherently dimension reduces. My intuition is that this controls the combinatorial explosion
The success of multi-head self-attentions (MSAs) for computer vision is now indisputable. However, little is known about how MSAs work. We present fundamental explanations to help better understand the nature of MSAs. In particular, we demonstrate the following properties of MSAs and Vision Transformers (ViTs): (1) MSAs improve not only accuracy but also generalization by flattening the loss landscapes. Such improvement is primarily attributable to their data specificity, not long-range dependency. On the other hand, ViTs suffer from non-convex losses. Large datasets and loss landscape smoothing methods alleviate this problem; (2) MSAs and Convs exhibit opposite behaviors. For example, MSAs are low-pass filters, but Convs are high-pass filters. Therefore, MSAs and Convs are complementary; (3) Multi-stage neural networks behave like a series connection of small individual models. In addition, MSAs at the end of a stage play a key role in prediction. Based on these insights, we propose AlterNet, a model in which Conv blocks at the end of a stage are replaced with MSA blocks. AlterNet outperforms CNNs not only in large data regimes but also in small data regimes. The code is available at this https URL.
SBIRs
It was a very busy day yesterday. Early morning meeting before the actual meeting, then lots of discussion on how (basically) to fit a simulation into a TLM. Then a long discussion with Dave. Then a short lunch break where I got to go for a walk in the February cold. Then demos, then another meeting with Dave.
Then about 45 minutes to spin down before
Waikato
Where we went over Tamahau’s progress, which is good.
Ended the day watching Mythbusters encasing Adam Savage in Bubble Wrap.
So, for today…
SBIRs
Responded to Dave’s email about tokenization and overall project approach. Talked about PGN as an example of simulator tokenizing. No meetings on the calendar, so I’m not sure what happens next.
Put together possible stories for next sprint
Book
If today turns out to be a light day, I’m going to start roughing out the social dominance chapter
GPT-Agents
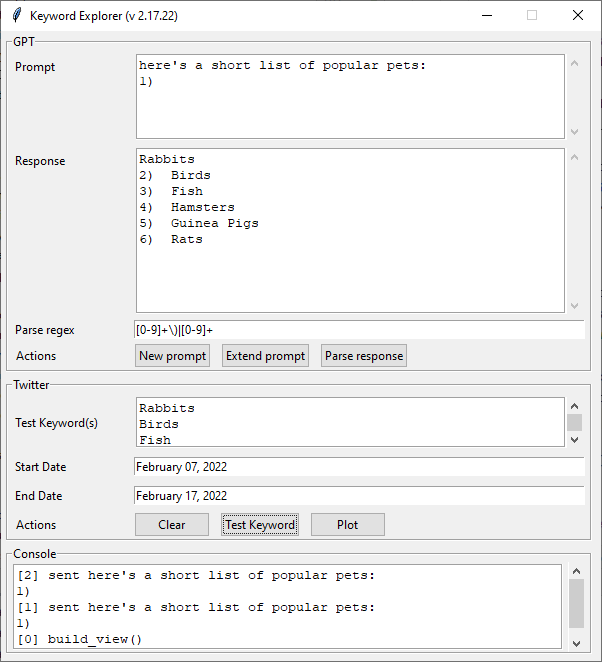
Need to put together a landscape for today’s meeting. Actually go caught up in just getting the results from one prompt “Here’s a short list of racist terms in wide use today. Some may surprise you:”. Not really even close to saturation and I have pages
3:30 Meeting. Fun! I think we’re going to look at food keyword generation because it’s less horrible than all the racist terms the GPT can come up with
3:30 Present the AI RoE paper to the data science tagup
4:30 LAIC meeting
Book
I finished Social Dominance last night and I think there might be room for a chapter on how SDT and AI/ML could work together to a) Identify and attenuate runaway HE behavior while also identifying and amplifying nascent or stagnant HA behavior.
Finished a pass of some kind and sent off to Wajanat and Aaron
Fixed the chapter headings
Reworked the proposal so that it has a new intro and the chapters are in the new order
SBIRs
10:00 Meeting with Rukan and Aaron
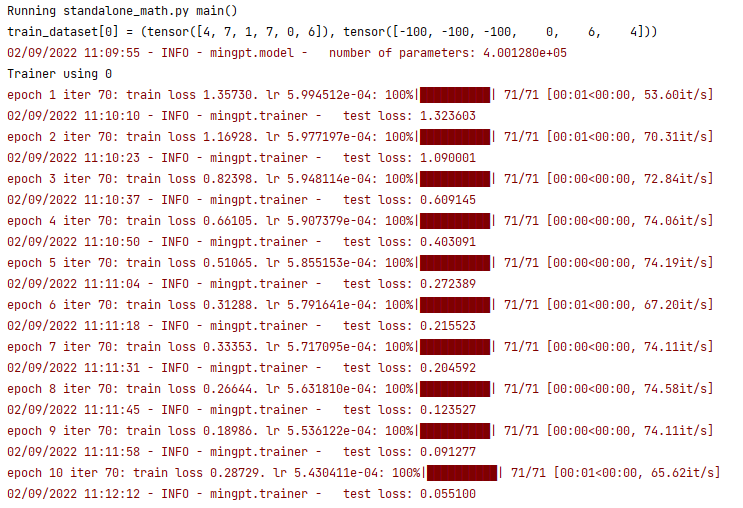
Need to download the MinGPT project and see if I can build it. It works! Now I need to load and save the model, then start playing around with the mask
Save and load the model
Create a reverse model
A working, from scratch, GPT
JuryRoom
Working with Zach a bit on framing out the concept and how much it might cost
More Transformers book. Need to look more deeply at MinGPT
GPT Agents
Now that I have the counts working, need to tie that back into the GPT output. I think I need some Parts-of-speech analysis to figure out what to count. The other part is to use the feedback to determine important points in the GPT response
BertViz: Visualize Attention in Transformer Models (BERT, GPT2, T5, etc.)
Found (I think) what I’m looking for: MinGPT: “A PyTorch re-implementation of GPT training. minGPT tries to be small, clean, interpretable and educational, as most of the currently available ones are a bit sprawling. GPT is not a complicated model and this implementation is appropriately about 300 lines of code, including boilerplate and a totally unnecessary custom causal self-attention module.“
GPT Agents
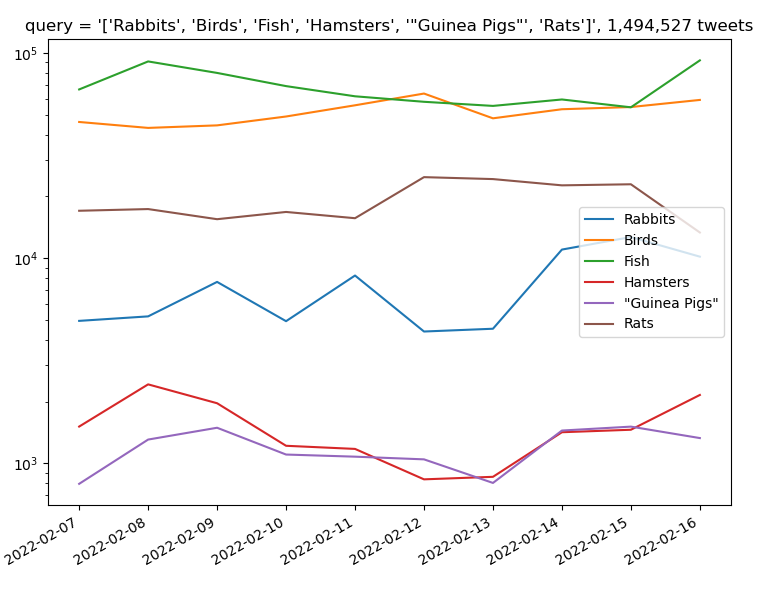
Continue with TwitterV2 count class. Good progress. I have basic functionality:
Chinese New Year!
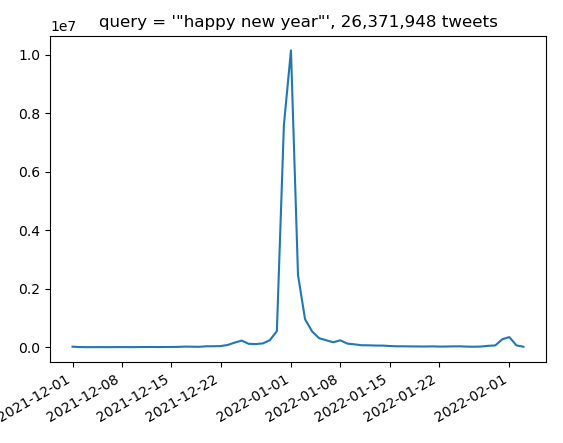
Need to work on the queries a bit to get phrases. Actually not hard, you just have to use escaped quotes ‘\”happy new year\”‘:
Got the counts query working with only a small amount of googling. The cool thing is that the items come back with a granularity, so this call (which has a default granularity of “day”:
This is very nice! I’m looking forward to doing some interesting things with the GPT. We can scan through responses to prompts and look at word-by-word Twitter frequencies after stop words, and then use those sentences for further prompting. We can also compare embeddings, cluster and other interesting things
Pretty much any data you want for general training at any scale
Datasets simplifies this process by providing a standard interface for thousands of datasets that can be found on the Hub. It also provides smart caching (so you don’t have to redo your preprocessing each time you run your code)and avoids RAM limitations by leveraging a special mechanism called memory mapping that stores the contents of a file in virtual memory and enables multiple processes to modify a file more efficiently.
Imbalanced-learn (imported as imblearn) is an open source, MIT-licensed library relying on scikit-learn (imported as sklearn) and provides tools when dealing with classification with imbalanced classes.
Nice NW job fair
Ack! Dreamhost has deleted my SVN repo. Very bad. Working on getting it back. Other options include RiouxSVN, but it may be moribund. Assembla hosts for $19/month with 500 GB, which is good because I store models. Alternatively, make a svn server, fix the IP address, and have it on Google Drive, OneDrive, or DropBox.
I think the upshot is to 1) Get the embedding topic narrative thing working, then run the gpt to generate keywords and count their occurrence on Twitter
Sharpened Cosine Similarity (CosSim) is an alternative to Convolution for building features in neural networks. It performs as well as ConvNets with 10x-100x more parameters.
Examined the possibility that social-desirability-tainted responses emerge in the study of stereotypes. 60 white male undergraduates were randomly assigned to 1 of 4 experimental conditions. Ss were asked to indicate how characteristic each of 22 adjective traits was of either “Americans” or “Negroes.” 1/2 the Ss responded in a rating situation in which they were presumably free to distort their responses. The remaining Ss responded under “bogus pipeline” conditions; i.e., they were led to believe that the experimenter had an accurate, distortion-free physiological measure of their attitudes, and were asked to predict that measure. Results support the expectation that the stereotype ascribed to Negroes would be more favorable under rating than under bogus pipeline conditions. Americans were more favorably stereotyped under bogus pipeline than under rating conditions. A number of explanations for these results are discussed, and consideration is given to the relationship between verbally expressed attitudes and other, overt, behavior.
Recent decades have seen a rise in the use of physics methods to study different societal phenomena. This development has been due to physicists venturing outside of their traditional domains of interest, but also due to scientists from other disciplines taking from physics the methods that have proven so successful throughout the 19th and the 20th century. Here we characterise the field with the term ‘social physics’ and pay our respect to intellectual mavericks who nurtured it to maturity. We do so by reviewing the current state of the art. Starting with a set of topics that are at the heart of modern human societies, we review research dedicated to urban development and traffic, the functioning of financial markets, cooperation as the basis for our evolutionary success, the structure of social networks, and the integration of intelligent machines into these networks. We then shift our attention to a set of topics that explore potential threats to society. These include criminal behaviour, large-scale migration, epidemics, environmental challenges, and climate change. We end the coverage of each topic with promising directions for future research. Based on this, we conclude that the future for social physics is bright. Physicists studying societal phenomena are no longer a curiosity, but rather a force to be reckoned with. Notwithstanding, it remains of the utmost importance that we continue to foster constructive dialogue and mutual respect at the interfaces of different scientific disciplines.
What are the pathways for spreading disinformation on social media platforms? This article addresses this question by collecting, categorizing, and situating an extensive body of research on how application programming interfaces (APIs) provided by social media platforms facilitate the spread of disinformation. We first examine the landscape of official social media APIs, then perform quantitative research on the open‐source code repositories GitHub and GitLab to understand the usage patterns of these APIs. By inspecting the code repositories, we classify developers’ usage of the APIs as official and unofficial, and further develop a four‐stage framework characterizing pathways for spreading disinformation on social media platforms. We further highlight how the stages in the framework were activated during the 2016 US Presidential Elections, before providing policy re-commendations for issues relating to access to APIs, algorithmic content, advertisements, and suggest rapid response to coordinate campaigns, development of collaborative, and participatory approaches as well as government stewardship in the regulation of social media platforms.
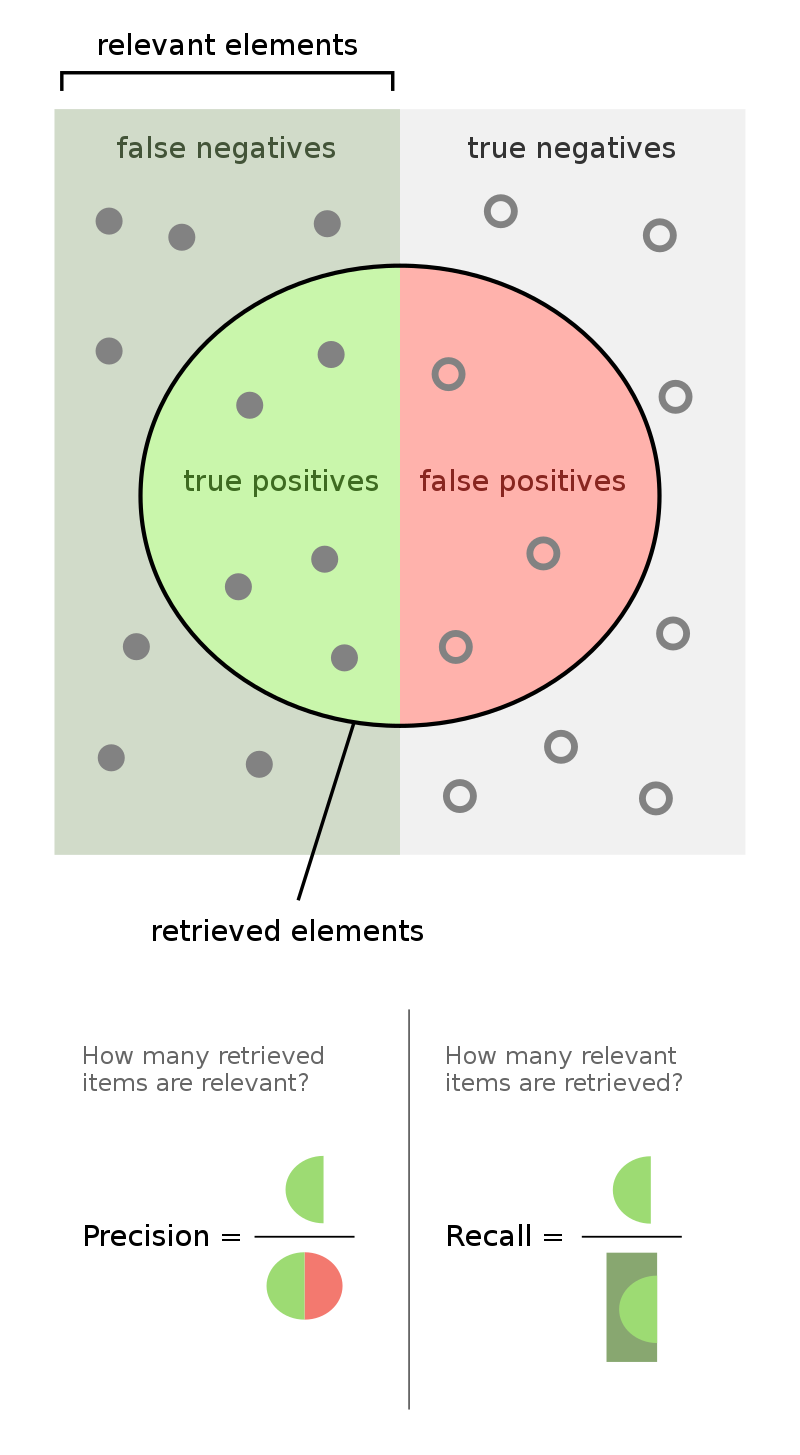
The Wikipedia folks have produced a very clear Precision/Recall diagram!









You must be logged in to post a comment.