And some output. First, from the Java code with the Hibernate SQL statements included. It’s nice to see that the same strategy that I was using for my direction db interaction is being used by Hibernate::
Hibernate: alter table employee drop foreign key FK_apfulk355h3oc786vhg2jg09w
Hibernate: drop table if exists employee
Hibernate: drop table if exists person
Hibernate: create table employee (department_name varchar(255), joining_date datetime, person_ID bigint not null, primary key (person_ID))
Hibernate: create table person (person_ID bigint not null auto_increment, first_name varchar(255), last_name varchar(255), uuid varchar(255), primary key (person_ID))
Hibernate: alter table employee add index FK_apfulk355h3oc786vhg2jg09w (person_ID), add constraint FK_apfulk355h3oc786vhg2jg09w foreign key (person_ID) references person (person_ID)
Dec 23, 2015 10:40:26 AM org.hibernate.tool.hbm2ddl.SchemaExport execute
INFO: HHH000230: Schema export complete
Hibernate: insert into person (first_name, last_name, uuid) values (?, ?, ?)
... lots more inserts ...
Hibernate: insert into person (first_name, last_name, uuid) values (?, ?, ?)
There are [2] members in the set
key = [com.philfeldman.mappings.Employee]
executing: from com.philfeldman.mappings.Employee
Hibernate: select employee0_.person_ID as person1_1_, employee0_1_.first_name as first2_1_, employee0_1_.last_name as last3_1_, employee0_1_.uuid as uuid4_1_, employee0_.department_name as departme1_0_, employee0_.joining_date as joining2_0_ from employee employee0_ inner join person employee0_1_ on employee0_.person_ID=employee0_1_.person_ID
[1/17bc0f66-da60-4935-a4d2-5d11e93e2419]: firstname_15 lastname_96 dept_7 hired Wed Dec 23 10:40:26 EST 2015
[3/6c15103a-49b2-4b63-8ef9-0c8ab3f84eab]: firstname_30 lastname_88 dept_75 hired Wed Dec 23 10:40:26 EST 2015
key = [com.philfeldman.mappings.Person]
executing: from com.philfeldman.mappings.Person
Hibernate: select person0_.person_ID as person1_1_, person0_.first_name as first2_1_, person0_.last_name as last3_1_, person0_.uuid as uuid4_1_, person0_1_.department_name as departme1_0_, person0_1_.joining_date as joining2_0_, case when person0_1_.person_ID is not null then 1 when person0_.person_ID is not null then 0 end as clazz_ from person person0_ left outer join employee person0_1_ on person0_.person_ID=person0_1_.person_ID
[1/17bc0f66-da60-4935-a4d2-5d11e93e2419]: firstname_15 lastname_96 dept_7 hired Wed Dec 23 10:40:26 EST 2015
[2/3edf8d12-dbd9-42d3-893f-c740714a2461]: firstname_6 lastname_99
[3/6c15103a-49b2-4b63-8ef9-0c8ab3f84eab]: firstname_30 lastname_88 dept_75 hired Wed Dec 23 10:40:26 EST 2015
[4/f5bba5c6-77a7-438b-bd73-5e12288d3b2c]: firstname_91 lastname_43
[5/75db23a9-3be3-44f5-80bf-547ab8c7f12f]: firstname_7 lastname_84 dept_36 hired Wed Dec 23 10:40:26 EST 2015
[6/45520bb5-8d3d-4577-b487-3e45d506bf50]: firstname_22 lastname_35
[7/c0bb18e6-6114-4e8a-a7ce-e580ddfb9108]: firstname_1 lastname_22






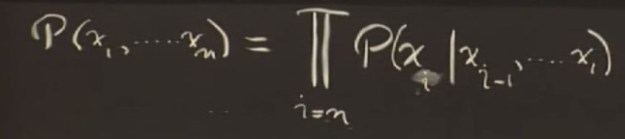
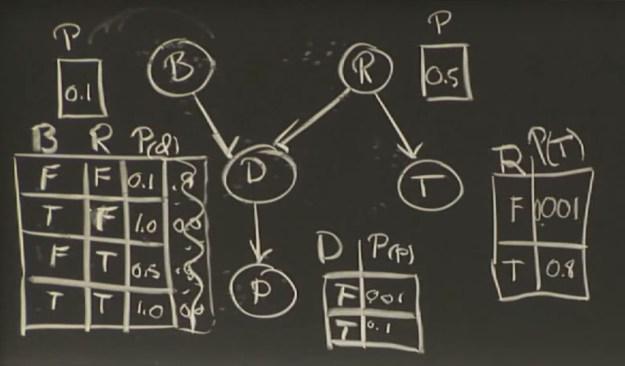 If this were a joint probability table there would be 2^5 (32) as opposed to the number here, which is 10.
If this were a joint probability table there would be 2^5 (32) as opposed to the number here, which is 10. I could see that the tempHi and tempLo items are being mapped as Objects. Typing
I could see that the tempHi and tempLo items are being mapped as Objects. Typing 
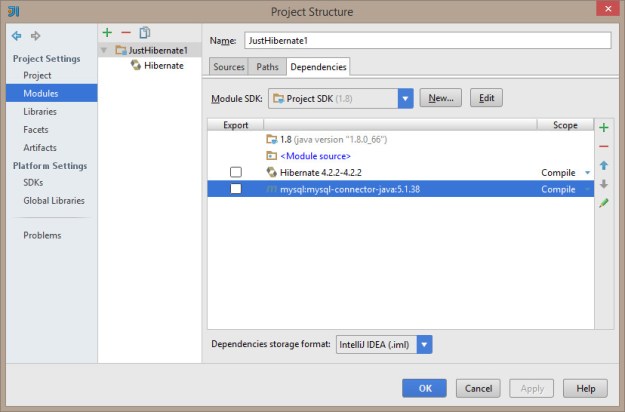 And here’s the library structure for the mysql driver. Note that it’s actually pointing at my m2 repo…
And here’s the library structure for the mysql driver. Note that it’s actually pointing at my m2 repo…


You must be logged in to post a comment.