
7:00 – 3:00 VTX
- Model Merging, Cross-Modal Coupling, Course Summary
- Bayesian story merging – Mark Finlayson
- Cross-modal coupling and the Zebra Finch – Coen
- If items are close in one modality, maybe they should be associated in other modalities.

- Good for dealing with unlabeled data that we need to make sense of
- If items are close in one modality, maybe they should be associated in other modalities.
- How You do it (Just AI?)
- Define or describe a competence
- Select or invent a representation
- Understand constraints and regularities – without this, you can’t make models.
- Select methods
- Implement and experiment
- Next Steps
- 6.868 Society of Mind – Minsky
- 6.863, 6.048 Language, Evolution – Berwick
- 6.945 Large Scale Symbolic Systems – Sussman
- 6.xxx Human Intellegence Enterprise – Winston
- Richards
- Tenenbaum
- Sinha
- MIT underground guide?
- Hibernate
- So the way we get around joins is to explicitly differentiate the primary key columns. So where I had ‘id_index’ as a common element which I would change in the creation of the view, in hibernate we have to have the differences to begin with (or we change the attribute column?) regardless, the column names appear to have to be different in the table…
- Here’s a good example of one-table-per-subclass that worked for me.
- And here’s my version. First, the cfg.xml:
<hibernate-configuration> <session-factory> <property name="connection.url">jdbc:mysql://localhost:3306/jh</property> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.username">root</property> <property name="connection.password">edge</property> <property name="dialect">org.hibernate.dialect.MySQL5Dialect</property> <property name="hibernate.show_sql">true</property> <!-- Drop and re-create the database schema on startup --> <property name="hbm2ddl.auto">create-drop</property> <mapping class="com.philfeldman.mappings.Employee"/> <mapping class="com.philfeldman.mappings.Person"/> </session-factory> </hibernate-configuration> - Next, the base Person Class:
package com.viztronix.mappings; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; import javax.persistence.Inheritance; import javax.persistence.InheritanceType; import javax.persistence.Table; import java.util.UUID; @Entity @Table(name = "person") @Inheritance(strategy=InheritanceType.JOINED) public class Person { @Id @GeneratedValue @Column(name = "person_ID") private Long personId; @Column(name = "first_name") private String firstname; @Column(name = "last_name") private String lastname; @Column(name = "uuid") private String uuid; // Constructors and Getter/Setter methods, public Person(){ UUID uuid = UUID.randomUUID(); this.uuid = uuid.toString(); } public Long getPersonId() { return personId; } // getters and setters... @Override public String toString(){ return "["+personId+"/"+uuid+"]: "+firstname+" "+lastname; } } - The inheriting Employee class:
package com.viztronix.mappings; import java.util.Date; import javax.persistence.*; @Entity @Table(name="employee") @PrimaryKeyJoinColumn(name="person_ID") public class Employee extends Person { @Column(name="joining_date") private Date joiningDate; @Column(name="department_name") private String departmentName; // getters and setters... @Override public String toString() { return super.toString()+ " "+departmentName+" hired "+joiningDate.toString(); } } - The ‘main’ program that calls the base class and subclass:
package com.philfeldman.mains; import com.viztronix.mappings.Employee; import com.viztronix.mappings.Person; import org.hibernate.HibernateException; import java.util.Date; public class EmployeeTest extends BaseTest{ public void addRandomPerson(){ try { session.beginTransaction(); Person person = new Person(); person.setFirstname("firstname_" + this.rand.nextInt(100)); person.setLastname("lastname_" + this.rand.nextInt(100)); session.save(person); session.getTransaction().commit(); }catch (HibernateException e){ session.getTransaction().rollback(); } } public void addRandomEmployee(){ try { session.beginTransaction(); Employee employee = new Employee(); employee.setFirstname("firstname_" + this.rand.nextInt(100)); employee.setLastname("lastname_" + this.rand.nextInt(100)); employee.setDepartmentName("dept_" + this.rand.nextInt(100)); employee.setJoiningDate(new Date()); session.save(employee); session.getTransaction().commit(); }catch (HibernateException e){ session.getTransaction().rollback(); } } public static void main(String[] args){ try { boolean setupTables = false; EmployeeTest et = new EmployeeTest(); et.setup("hibernateSetupTables.cfg.xml"); //et.setup("hibernate.cfg.xml"); for(int i = 0; i < 10; ++i) { et.addRandomEmployee(); et.addRandomPerson(); } et.printAllRows(); et.closeSession(); }catch (Exception e){ e.printStackTrace(); } } } - And some output. First, from the Java code with the Hibernate SQL statements included. It’s nice to see that the same strategy that I was using for my direction db interaction is being used by Hibernate::
Hibernate: alter table employee drop foreign key FK_apfulk355h3oc786vhg2jg09w Hibernate: drop table if exists employee Hibernate: drop table if exists person Hibernate: create table employee (department_name varchar(255), joining_date datetime, person_ID bigint not null, primary key (person_ID)) Hibernate: create table person (person_ID bigint not null auto_increment, first_name varchar(255), last_name varchar(255), uuid varchar(255), primary key (person_ID)) Hibernate: alter table employee add index FK_apfulk355h3oc786vhg2jg09w (person_ID), add constraint FK_apfulk355h3oc786vhg2jg09w foreign key (person_ID) references person (person_ID) Dec 23, 2015 10:40:26 AM org.hibernate.tool.hbm2ddl.SchemaExport execute INFO: HHH000230: Schema export complete Hibernate: insert into person (first_name, last_name, uuid) values (?, ?, ?) ... lots more inserts ... Hibernate: insert into person (first_name, last_name, uuid) values (?, ?, ?) There are [2] members in the set key = [com.philfeldman.mappings.Employee] executing: from com.philfeldman.mappings.Employee Hibernate: select employee0_.person_ID as person1_1_, employee0_1_.first_name as first2_1_, employee0_1_.last_name as last3_1_, employee0_1_.uuid as uuid4_1_, employee0_.department_name as departme1_0_, employee0_.joining_date as joining2_0_ from employee employee0_ inner join person employee0_1_ on employee0_.person_ID=employee0_1_.person_ID [1/17bc0f66-da60-4935-a4d2-5d11e93e2419]: firstname_15 lastname_96 dept_7 hired Wed Dec 23 10:40:26 EST 2015 [3/6c15103a-49b2-4b63-8ef9-0c8ab3f84eab]: firstname_30 lastname_88 dept_75 hired Wed Dec 23 10:40:26 EST 2015 key = [com.philfeldman.mappings.Person] executing: from com.philfeldman.mappings.Person Hibernate: select person0_.person_ID as person1_1_, person0_.first_name as first2_1_, person0_.last_name as last3_1_, person0_.uuid as uuid4_1_, person0_1_.department_name as departme1_0_, person0_1_.joining_date as joining2_0_, case when person0_1_.person_ID is not null then 1 when person0_.person_ID is not null then 0 end as clazz_ from person person0_ left outer join employee person0_1_ on person0_.person_ID=person0_1_.person_ID [1/17bc0f66-da60-4935-a4d2-5d11e93e2419]: firstname_15 lastname_96 dept_7 hired Wed Dec 23 10:40:26 EST 2015 [2/3edf8d12-dbd9-42d3-893f-c740714a2461]: firstname_6 lastname_99 [3/6c15103a-49b2-4b63-8ef9-0c8ab3f84eab]: firstname_30 lastname_88 dept_75 hired Wed Dec 23 10:40:26 EST 2015 [4/f5bba5c6-77a7-438b-bd73-5e12288d3b2c]: firstname_91 lastname_43 [5/75db23a9-3be3-44f5-80bf-547ab8c7f12f]: firstname_7 lastname_84 dept_36 hired Wed Dec 23 10:40:26 EST 2015 [6/45520bb5-8d3d-4577-b487-3e45d506bf50]: firstname_22 lastname_35 [7/c0bb18e6-6114-4e8a-a7ce-e580ddfb9108]: firstname_1 lastname_22
- Last, here’s what was produced in the db:

- Starting on the network data model
- Added NetworkType(class) network_types(table)
- Added BaseNode(class) network_nodes(table)
- The mapping for the types in the BaseNode class looks like this (working from this tutorial):
@Entity @Table(name="network_nodes") public class BaseNode { @Id @GeneratedValue(strategy= GenerationType.AUTO) @Column(name="node_id") private int id; private String name; private String guid; @ManyToOne @JoinColumn(name = "type_id") private NetworkType type; public BaseNode(){ UUID uuid = UUID.randomUUID(); guid = uuid.toString(); } public BaseNode(String name, NetworkType type) { this(); this.name = name; this.type = type; } //... @Override public String toString() { return "["+id+"]: name = "+name+", type = "+type.getName()+", guid = "+guid; } } - No changes needed for the NetworkType class, so it’s a one-way relationship, which is what I wanted:
@Entity @Table(name="network_types") public class NetworkType { @Id @GeneratedValue(strategy= GenerationType.AUTO) @Column(name="type_id") private int id; private String name = null; public NetworkType(){} public NetworkType(String name) { this.name = name; } // ... @Override public String toString() { return "["+id+"]: "+name; } }
- The mapping for the types in the BaseNode class looks like this (working from this tutorial):


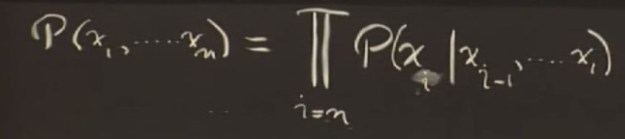
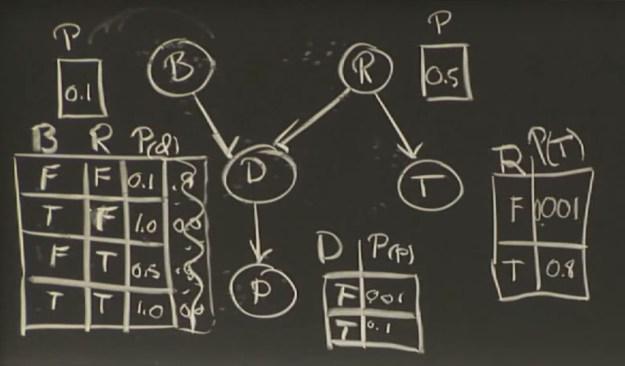 If this were a joint probability table there would be 2^5 (32) as opposed to the number here, which is 10.
If this were a joint probability table there would be 2^5 (32) as opposed to the number here, which is 10. I could see that the tempHi and tempLo items are being mapped as Objects. Typing
I could see that the tempHi and tempLo items are being mapped as Objects. Typing 
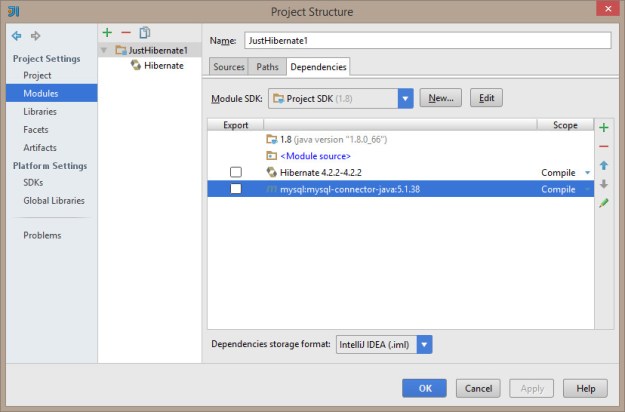 And here’s the library structure for the mysql driver. Note that it’s actually pointing at my m2 repo…
And here’s the library structure for the mysql driver. Note that it’s actually pointing at my m2 repo…


You must be logged in to post a comment.