Read Goodall on dominance displays and alliances. I think this is the in. Dominance is very low dimension (one or two?) and effective in mass movements. Arendt’s concept of terror in totalitarian states could be a manifestation of dominance at scale. There are two sides, the dominating and the dominated. They are low dimension in their own ways.
Also something about bullying vs. adversarial herding. Bullying is very low dimensional. It is generally reactive and not reflective. Herding can organize the power of bullying to move populations. It is extremely analytic. Consider the interactions between the Sheppard, the sheepdog, and and the sheep. Herding doesn’t have to be malevolent. It can simply be to sell products like supplements.
The goal of the blog post is to give an in-detail explanation of how the transformer-based encoder-decoder architecture models sequence-to-sequence problems. We will focus on the mathematical model defined by the architecture and how the model can be used in inference. Along the way, we will give some background on sequence-to-sequence models in NLP and break down the transformer-based encoder-decoder architecture into its encoder and decoder part. We provide many illustrations and establish the link between the theory of transformer-based encoder-decoder models and their practical usage in 🤗Transformers for inference. Note that this blog post does not explain how such models can be trained – this will be the topic of a future blog post.
JuryRoom
Need to respond to Tony’s email. Talk about how text entropy works at the limit: “all work and no play make Jack a dull boy” at one end and random text at the other. Different populations will produce different probabilities of (possibly the same) words. These can further be clustered using word2vec. Additionally, doc2vec could cluster different rooms.
Book
More work on the Money section. Set up discussion in the emergence section as what happens once money is established
7:00 Drinking with historians is going to cover “patriotism”. This might tie into dimension reduction and cults. Going to see if it’s possible to ask questions
GOES
Still thinking about the hiccup in the calculations. Maybe test for which of the four vectors (X, Y, Z, and combined) that’s closest to the previous vector and choose that?
Finish creativity section in Money, start on Cults
GOES
I think what I want to try is to sum all the vectors, based on the normalized total swept area. That becomes the synthesized rotation vector. Keep that rather than a VecData object.
Well, instead of just keeping the vector, I create and maintain a current_vd VecData object since it has all the rotation math in it. The results are significantly better!
On vacation riding around the Maryland Eastern Shore, but I’m also trying to see if I can connect the ML concept of attention to population scale thinking
Current state-of-the-art machine translation systems are based on encoder-decoder architectures, that first encode the input sequence, and then generate an output sequence based on the input encoding. Both are interfaced with an attention mechanism that recombines a fixed encoding of the source tokens based on the decoder state. We propose an alternative approach which instead relies on a single 2D convolutional neural network across both sequences. Each layer of our network re-codes source tokens on the basis of the output sequence produced so far. Attention-like properties are therefore pervasive throughout the network. Our model yields excellent results, outperforming state-of-the-art encoder-decoder systems, while being conceptually simpler and having fewer parameters.
Good discussion last night. Trying to get Tony to grock that JR runs on two levels, the individual discussion room and the aggregate results of many juries deliberating on the same topic
Had a thought this morning about recording user interactions such as slider behavior and keystroke dynamics. Talked to Darcy a bit about that this morning
GOES
Create an Rwheel class that has all the main components that SimpleRwheels uses and then make it work for any number and orientation of wheels.
Book
Start money section. I used the Speech-to-text tool in Google Docs. I think that may have worked very well. I did a paragraph at a time, edited a bit, then did the next.
Still working on getting Google Translate to work without the os value set (which is misbehaving). This looks to be the answer (from stackoverflow, of course):
# The way I think it should be done
client = language.LanguageServiceClient.from_service_account_json("/path/to/file.json")
# Google seems to want this value set though, for portability across environments?
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="/path/to/file.json"
The most recent Google documentation on this requires a storage object, and then doesn’t show how to use it?
# Explicitly use service account credentials by specifying the private key # file. storage_client = storage.Client.from_service_account_json('service_account.json')
This worked!
from google.cloud import translate_v2 as translate
translate_client = translate.Client.from_service_account_json("credentials.json")
text = u"So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate."
target = "de"
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
print(u"Text: {}".format(result["input"]))
print(u"Translation: {}".format(result["translatedText"]))
print(u"Detected source language: {}".format(result["detectedSourceLanguage"]))
Results:
Text: So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate.
Translation: Beginnen wir also neu - denken wir auf beiden Seiten daran, dass Höflichkeit kein Zeichen von Schwäche ist und Aufrichtigkeit immer einem Beweis unterliegt. Lasst uns niemals aus Angst verhandeln. Aber lasst uns niemals Angst haben zu verhandeln.
Detected source language: en
Here’s the list of supported languages:
Afrikaans (af)
Albanian (sq)
Amharic (am)
Arabic (ar)
Armenian (hy)
Azerbaijani (az)
Basque (eu)
Belarusian (be)
Bengali (bn)
Bosnian (bs)
Bulgarian (bg)
Catalan (ca)
Cebuano (ceb)
Chichewa (ny)
Chinese (Simplified) (zh-CN)
Chinese (Traditional) (zh-TW)
Corsican (co)
Croatian (hr)
Czech (cs)
Danish (da)
Dutch (nl)
English (en)
Esperanto (eo)
Estonian (et)
Filipino (tl)
Finnish (fi)
French (fr)
Frisian (fy)
Galician (gl)
Georgian (ka)
German (de)
Greek (el)
Gujarati (gu)
Haitian Creole (ht)
Hausa (ha)
Hawaiian (haw)
Hebrew (iw)
Hindi (hi)
Hmong (hmn)
Hungarian (hu)
Icelandic (is)
Igbo (ig)
Indonesian (id)
Irish (ga)
Italian (it)
Japanese (ja)
Javanese (jw)
Kannada (kn)
Kazakh (kk)
Khmer (km)
Kinyarwanda (rw)
Korean (ko)
Kurdish (Kurmanji) (ku)
Kyrgyz (ky)
Lao (lo)
Latin (la)
Latvian (lv)
Lithuanian (lt)
Luxembourgish (lb)
Macedonian (mk)
Malagasy (mg)
Malay (ms)
Malayalam (ml)
Maltese (mt)
Maori (mi)
Marathi (mr)
Mongolian (mn)
Myanmar (Burmese) (my)
Nepali (ne)
Norwegian (no)
Odia (Oriya) (or)
Pashto (ps)
Persian (fa)
Polish (pl)
Portuguese (pt)
Punjabi (pa)
Romanian (ro)
Russian (ru)
Samoan (sm)
Scots Gaelic (gd)
Serbian (sr)
Sesotho (st)
Shona (sn)
Sindhi (sd)
Sinhala (si)
Slovak (sk)
Slovenian (sl)
Somali (so)
Spanish (es)
Sundanese (su)
Swahili (sw)
Swedish (sv)
Tajik (tg)
Tamil (ta)
Tatar (tt)
Telugu (te)
Thai (th)
Turkish (tr)
Turkmen (tk)
Ukrainian (uk)
Urdu (ur)
Uyghur (ug)
Uzbek (uz)
Vietnamese (vi)
Welsh (cy)
Xhosa (xh)
Yiddish (yi)
Yoruba (yo)
Zulu (zu)
Hebrew (he)
Chinese (Simplified) (zh)
Here’s round-tripping to Arabic:
from google.cloud import translate_v2 as translate
translate_client = translate.Client.from_service_account_json("path_to_credentials_file.json")
text = u"So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate."
target = "ar"
source = "en"
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
print(u"Text: {}".format(result["input"]))
print(u"Translation: {}".format(result["translatedText"]))
print(u"Detected source language: {}".format(result["detectedSourceLanguage"]))
text = u"{}".format(result["translatedText"])
result = translate_client.translate(text, target_language=source)
print(u"Text: {}".format(result["input"]))
print(u"Translation: {}".format(result["translatedText"]))
print(u"Detected source language: {}".format(result["detectedSourceLanguage"]))
Results:
Text: So let us begin anew--remembering on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let us never negotiate out of fear. But let us never fear to negotiate.
Translation: لذلك دعونا نبدأ من جديد - نتذكر على الجانبين أن الكياسة ليست علامة ضعف ، وأن الإخلاص يخضع دائمًا للإثبات. دعونا لا نتفاوض بدافع الخوف. ولكن دعونا لا نخشى للتفاوض.
Detected source language: en
Text: لذلك دعونا نبدأ من جديد - نتذكر على الجانبين أن الكياسة ليست علامة ضعف ، وأن الإخلاص يخضع دائمًا للإثبات. دعونا لا نتفاوض بدافع الخوف. ولكن دعونا لا نخشى للتفاوض.
Translation: So let's start over - remember on both sides that civility is not a sign of weakness, and sincerity is always subject to proof. Let's not negotiate out of fear. But let's not be afraid to negotiate.
Detected source language: ar
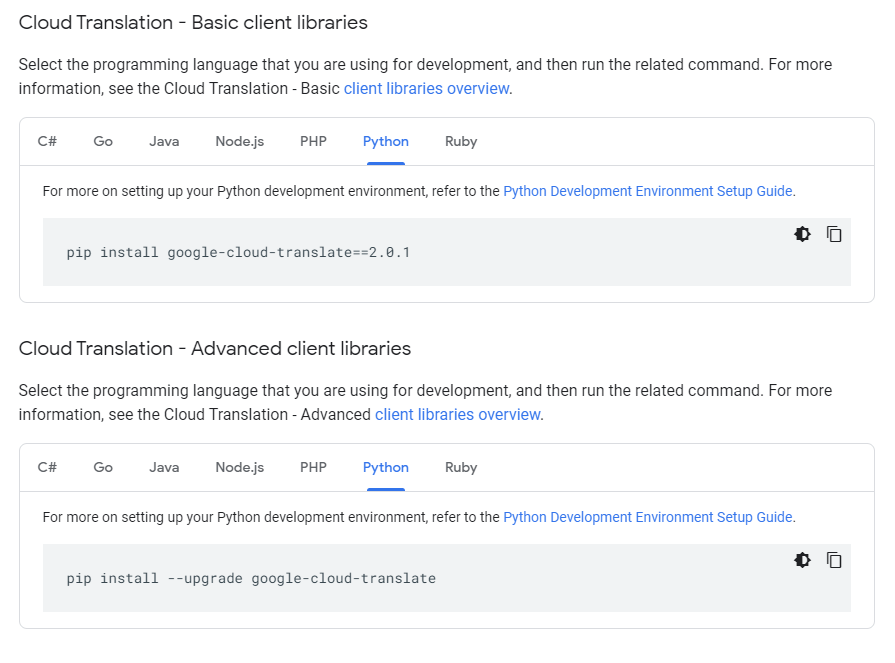
Note that I could get this working with V2, but not V3. I am not sure that I’ve done the following install though, and I’m kinda afraid to break things
pip install --upgrade google-cloud-translate
GOES
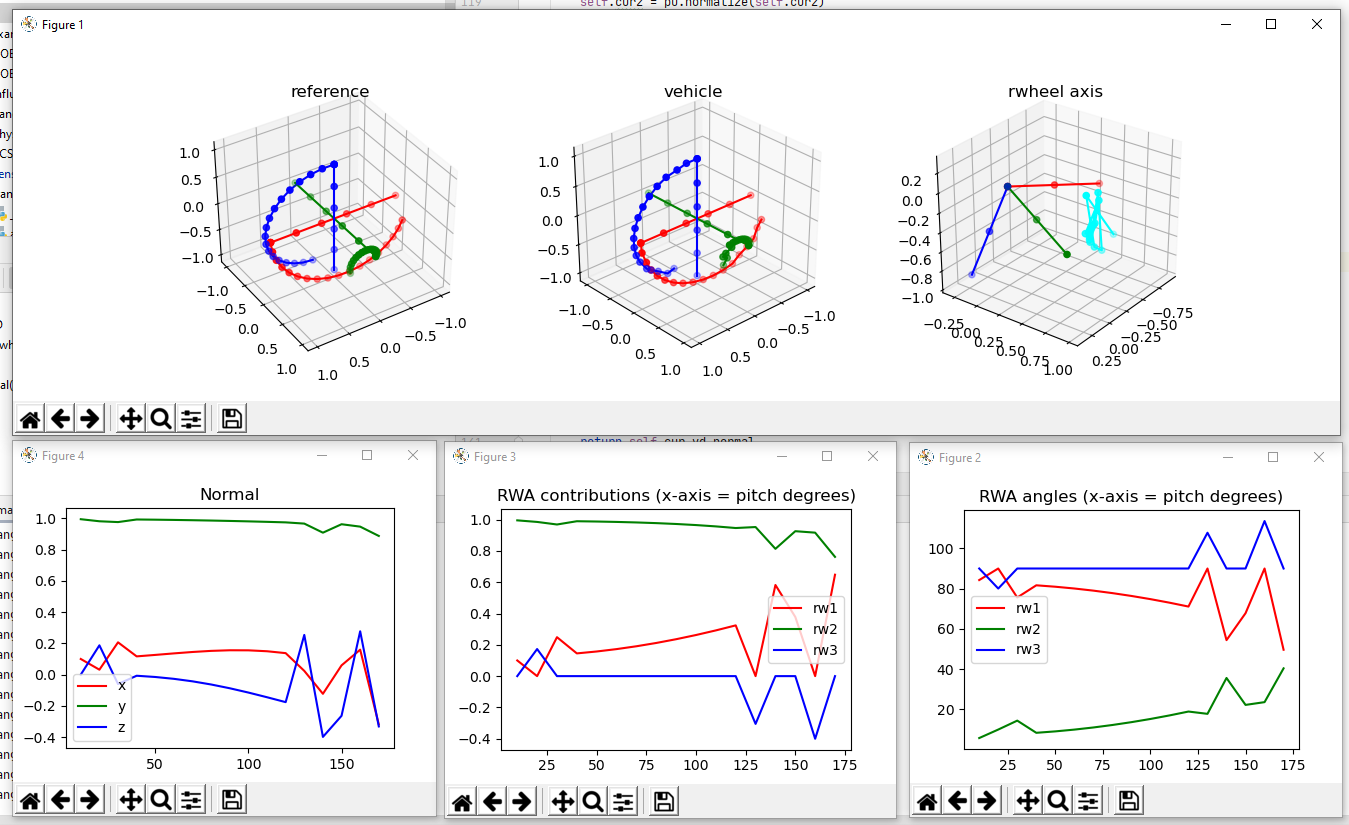
More working through the algorithm. I want to make plots for the normal (rotation) vector to see how that looks. That could also be plotted in 3D. Hmmm.
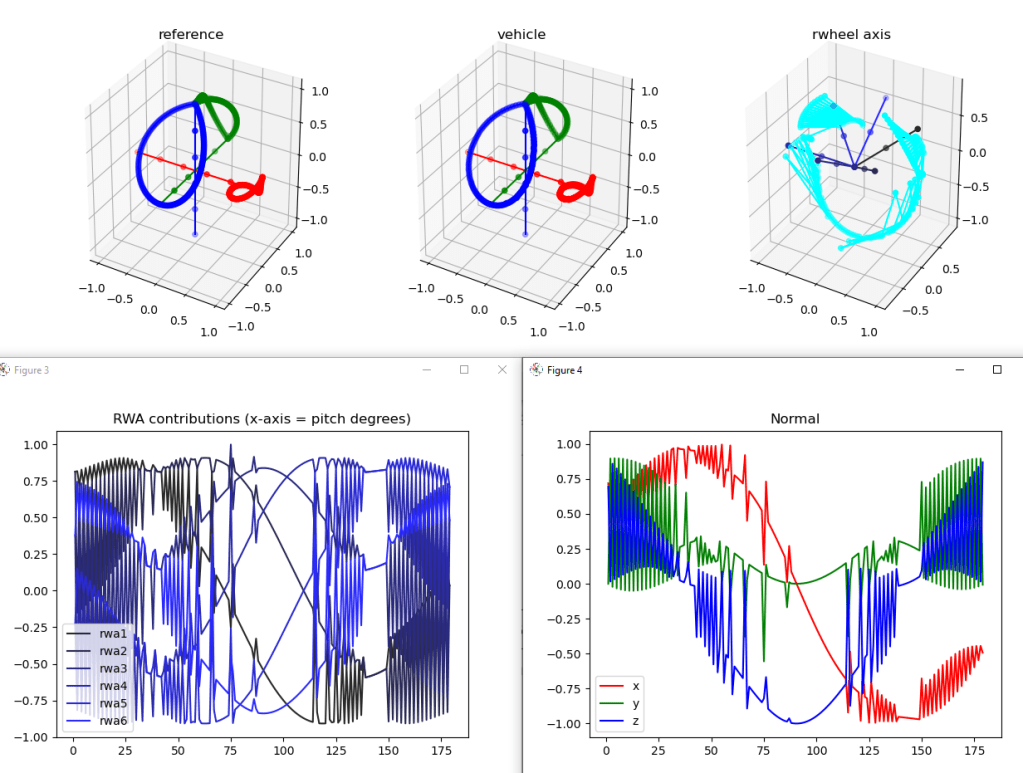
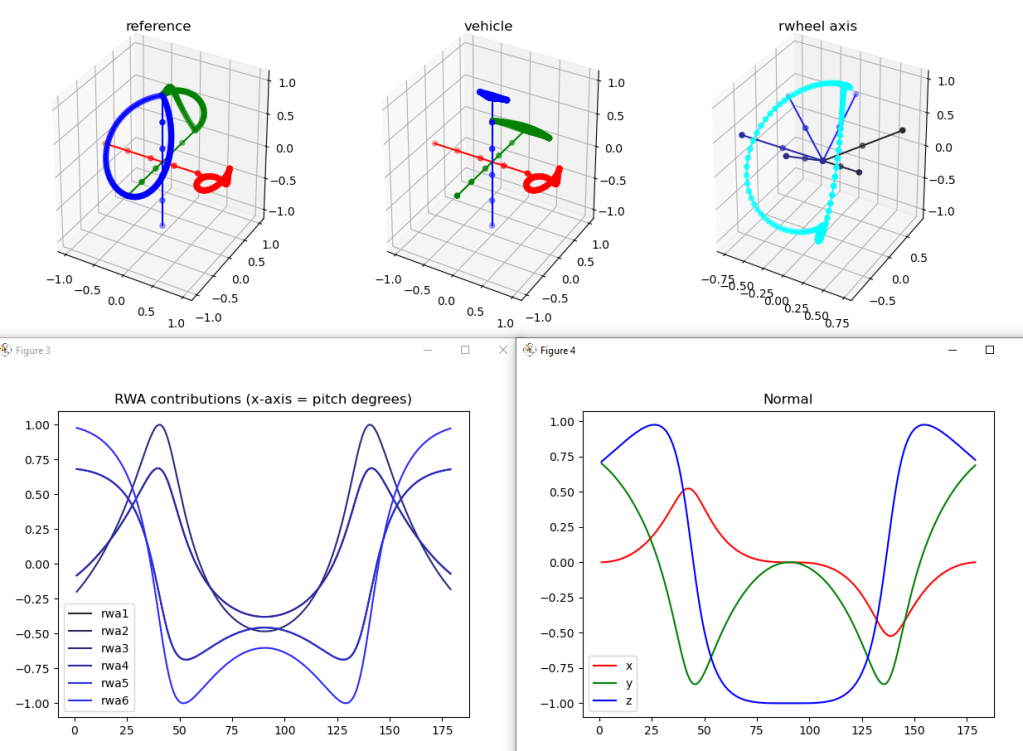
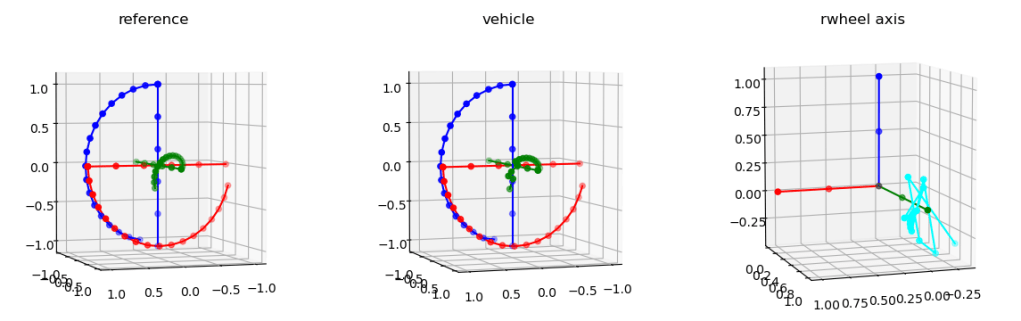
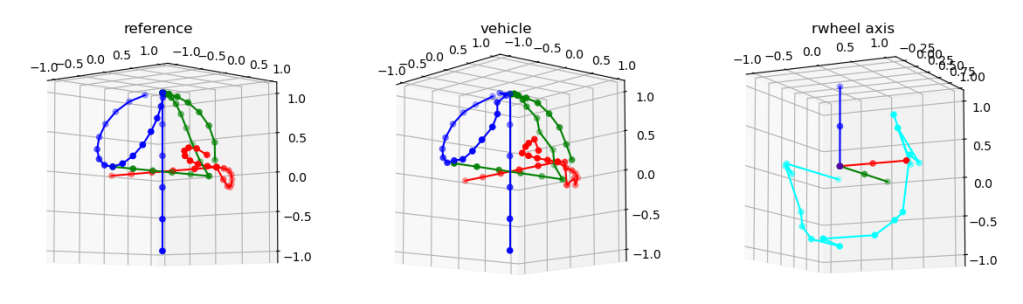
So that’s done, and it’s not as smooth as it should be. Here’s the reference frame rotated through 180 degrees on the left, the matching rotation in the middle, and the simplified reaction wheels with the rotation axis (cyan) on the right:
That cyan plot really bothers me. The results aren’t bad (vehicle), but I wonder if it’s because there are two choices that are equally good and it’s alternating between them? Let’s print out the name of the axis and the runner’s up (sorted by angle):
x angle = -1.00, y angle = -1.00, z angle = -1.00
z angle = 10.05, x angle = 10.03, y angle = 1.41
x angle = 10.11, z angle = 10.05, y angle = 2.02
z angle = 10.27, x angle = 9.95, y angle = 2.69
z angle = 10.03, x angle = 9.97, y angle = 1.87
z angle = 10.02, x angle = 9.96, y angle = 2.10
z angle = 10.00, x angle = 9.92, y angle = 2.25
z angle = 9.99, x angle = 9.85, y angle = 2.32
z angle = 9.96, x angle = 9.76, y angle = 2.34
z angle = 9.94, x angle = 9.66, y angle = 2.40
z angle = 9.91, x angle = 9.57, y angle = 2.59
z angle = 9.88, x angle = 9.54, y angle = 3.00
z angle = 9.85, x angle = 9.61, y angle = 3.67
x angle = 9.81, z angle = 9.81, y angle = 4.60
z angle = 11.31, x angle = 9.32, y angle = 6.58
z angle = 9.73, x angle = 9.45, y angle = 4.32
x angle = 9.90, z angle = 9.69, y angle = 5.66
z angle = 11.64, x angle = 9.10, y angle = 7.57
The x and z axis are almost identical. Would it make sense to average the closest? Let’s try something more extreme:
x angle = -1.00, y angle = -1.00, z angle = -1.00
y angle = 14.11, z angle = 14.11, x angle = 12.82
z angle = 20.31, x angle = 17.04, y angle = 14.19
y angle = 17.53, z angle = 13.48, x angle = 13.01
z angle = 14.25, y angle = 13.54, x angle = 6.81
y angle = 13.78, z angle = 12.22, x angle = 6.76
z angle = 12.27, y angle = 10.56, x angle = 6.80
z angle = 10.82, y angle = 8.63, x angle = 7.64
z angle = 10.29, x angle = 9.36, y angle = 6.14
x angle = 10.28, z angle = 10.00, y angle = 3.70
z angle = 9.85, x angle = 9.85, y angle = 3.70
z angle = 10.29, x angle = 8.94, y angle = 5.09
z angle = 10.82, y angle = 8.09, x angle = 7.32
z angle = 11.50, y angle = 10.74, x angle = 5.69
y angle = 13.27, z angle = 12.22, x angle = 6.12
y angle = 13.54, z angle = 13.02, x angle = 4.16
y angle = 14.09, z angle = 13.21, x angle = 6.16
z angle = 15.23, y angle = 14.19, x angle = 12.12
10:00 Meeting with Vadim. Went over the code and found that the angle calculation only works properly between two unit (vectors of the same length?). That fixed the contribution problems I was having. So that’s one serious bug fixed. Vadim is going to look at folding in the changes, and I’m going to work on getting this to work with the six reaction wheel version.
Creating a list of distinct content that translated to “elderman”. Going to see if I can get the Google Translate API to deal with these problem children
Installing the python libraries for google translate
Because I love pain, upgraded tensorflow. Let’s see if anything still works! It does! At least for translation and GPT, which is good enough for me at the moment
Working on getting the translate API running
GPT-2 Agents
The paper’s submitted!
Had a good chat with Shimei and Sim last night. The db has been uploaded, and we talked about next steps. I also showed how to install the Huggingface transformers library from source. That involved uninstalling the Typing library for some reason. Seems there are conflicts?
Updated my DaysToZero code to put charts into the spreadsheet, which was pretty straightforward using xlsxwriter. There do seem to be three basic patterns:
The first is steady growth:
So no curve flattening here. The disease is moving pretty steadily through the population. The USA is mostly on this track as are countries like India and Chile. I think the difference that we see is related to a first, faster wave among the more vulnerable populations.
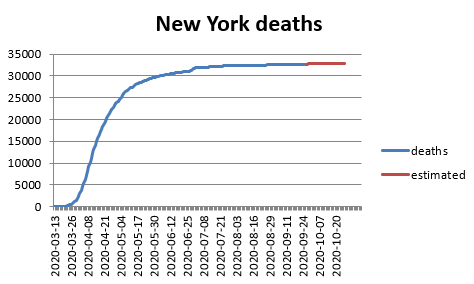
The second pattern is the ‘flattened curve’. Ireland shows this really well, as does New York state:
The last pattern is the ‘second wave’ pattern. Japan seems to be having one now:
So it looks like we are far from out of the woods on this, and letting your guard down is soundly punished.
#COVID
Start the db to fixing “elderman” posts. Running. I’ve got about 100k bad posts. The fixes seem to be taking care of some. This is going to require multiple passes
GOES
2:00 Meeting with Vadim
GPT-2 Agents
Updated the document. Antonio’s going to submit. Fingers crossed! It would be nice to go to London in May
3:30 meeting?
Need to backup and save the db. Done. It’s almost 11GB! Compressing. Backed up the compressed version, which is (only!) 3GB.
Adding to these thoughts about using three stories to frame nomad, flock, and stampede behaviors.
Listening to BBC Business Daily on London’s dirty financial secrets. In the episode, Tom Burgis, author of a new book Kleptopia: How Dirty Money is Conquering the World, discusses money laundering. It’s making me think about how though money is a dimension reduction process, it’s a very peculiar one. The ability to simplify transactions and “store” the profits means that power accumulates with money. That money lets the owner of the money pay people to add dimensions in other areas. This can be good, as with scientific research, or it can be bad, as with the creation of the byzantine dimensions of money laundering. In the middle somewhere are activities like high-speed trading.
The thing is, any increase in the ability to create social realities that exist independently of the environmental reality creates the conditions for stampedes. A lot of crime (Scams, cons, embezzlement) depends on the creation of a social reality that overwhelms trustworthy information coming in through other channels.
More transcription
GPT-2 Agents
At 7.5M tweets so far
Got Antonio’s comments back. Need to roll them in
GOES
More rotations. I think we found the problems. The first is that the angles being fed to the absolute angle calculations were wrong. The second was that the sign of the pitch and yaw vectors flip near 180 degrees and we were not compensating for that.
Need to try a runthrough for the GVSETS slides. Too tired. Maybe over the weekend.
Need to fix “elderman” translations, though there are some other bad/partial translations as well
GOES
Create logger for DDict – done!
Start rwheel coding for incremental rotations – started
2:00 Meeting and demo. It went well, I think. We can run 100x speedup now!
Vadim has this thought: Was just thinking that at the next demo meeting, we should mention that this is adaptable to many different situations, including simulating the Launch Orbit Raising scenarios, specifically for the upcoming GOES-T launch. Since it’s a physics sim and we can make the various pieces move, such as deploying the solar panels.
10:00 Meeting with Vadim. Worked through bugs in the angle adjustment code and added clamping. Still have problems at 120 degrees. Need to see if this is a blocker for the demo
Roll freezes at exactly 90 degrees. WTaF? Need to extend the DDict so that it can dump a column-format csv file that is incrementally updated
Pitch works great. It’s neat to see how all the rwheels line up for that maneuver
Today the USA passed 200,000 dead from COVID-19. That triggered a memory from the earlier days of the pandemic. Italy handled the virus poorly, and I remember thinking that will be the standard that the USA will be judged. It should have been relatively easy to do better than Italy.
In the chart above, I scaled the deaths for selected countries so that they could be compared to the US directly. As you can see, we are now worse than any country in the EU, and staggeringly worse than South Korea.
Not sure what to do about that other than just be angry.
Book
Transcribing
Reading more on the money book, and coming to the conclusion that money provides consistent mathematical rules for transactions that promote coordination
GOES
10:00 Meeting with Vadim. Walked through a lot and fixed a few things. There seems to be some problem related to 120 degrees, which is the angular spacing of the reaction wheels. I think that we are hitting a singularity. Working on a short term fix, though I think the long term is to simply use the reference frame code I’m working on
Speaking of which, I need to have a case for handling overlapping vectors (angle = 0), and not using an angle that is too small, and using the last angle if possible. If no angles are available, then wait until the next time and get larger angles? Done!














You must be logged in to post a comment.