Science is a social process, and teaching students how researchers work in tandem to develop facts will make them less likely to be duped by falsehoods
GPT Agents
Model Explorer
Make it so that seed re-use happens only on new text – Done
Add ‘%’ to percentage formatting – Done
add parsing of probes to split on commas – Done
Get experiment loading working – Done
Wire up to db – Not done
Created table_text and table_text_data in the gpt_experiments schema
Finish up Money section. Maybe introduce the idea of self-grounded spaces? Either add a section to Belief is a Place, and continue here, or introduce here and continue on with the rest of the book? Not sure
SBIRs
Add method that handles a particular class and produces a tab in a spreadsheet
Add overridable “publish” method in BaseController?
Comment changes in SharedObjects and BaseController
Many recent corporate scandals have been described as resulting from a slippery slope in which a series of small infractions gradually increased over time (e.g., McLean & Elkind, 2003). However, behavioral ethics research has rarely considered how unethical behavior unfolds over time. In this study, we draw on theories of self-regulation to examine whether individuals engage in a slippery slope of increasingly unethical behavior. First, we extend Bandura’s (1991, 1999) social-cognitive theory by demonstrating how the mechanism of moral disengagement can reduce ethicality over a series of gradually increasing indiscretions. Second, we draw from recent research connecting regulatory focus theory and behavioral ethics (Gino & Margolis, 2011) to demonstrate that inducing a prevention focus moderates this mediated relationship by reducing one’s propensity to slide down the slippery slope. We find support for the developed model across 4 multiround studies. (PsycINFO Database Record (c) 2014 APA, all rights reserved).
SBIRs
Working on showing controller commands, states, and responses – done!
Add SharedObject “queries” that create spreadsheets for specified (maybe an array?) types. Got the basics working. Need to break out a method to handle a type and a writer
Book
10:00 Meeting! We are going ahead on the book! Submission of the full book at the beginning of December, and a decision 1-2 weeks after that!
Use the GoogleExplorer as a template for prompt interactions, and try some repeat interactions! Parsed output can easily be rendered as html which should be a nice touch. The text is the main piece, and the meta attributes are <ul> elements
Add param list for GPT generation
Add buttons to save current output to db
Add textarea for description
4:00 Meeting
Progress for today!
SBIRs
More writing
Book
Reply to Katy, and try to set up a meeting? Done. 10:00am tomorrow!
Fold in more changes
I realize that fiat money is also a self-grounded belief space. I think that means that money, organized religion, and constitutional governments are all related. They are also distinctly different from ungrounded belief spaces. Added a note to the text
“Skops” is the name of the framework being actively developed as the link between the scikit-learn and the Hugging Face ecosystems. With Skops, we hope to facilitate essential workflows:
The ability to push scikit-learn models on the Hugging Face Hub
The possibility to try out models directly in the browser
The automatic creation of model cards, to improve model documentation and understanding
The ability to collaborate with others on machine learning projects
Started to poke at the outlines of a religion chapter
4:00 Meeting with Brenda
SBIRs
Working on 3D viz
1:00 LLM Meeting with Isaac and Aaron
2:00 MDA meeting
GPT Agents
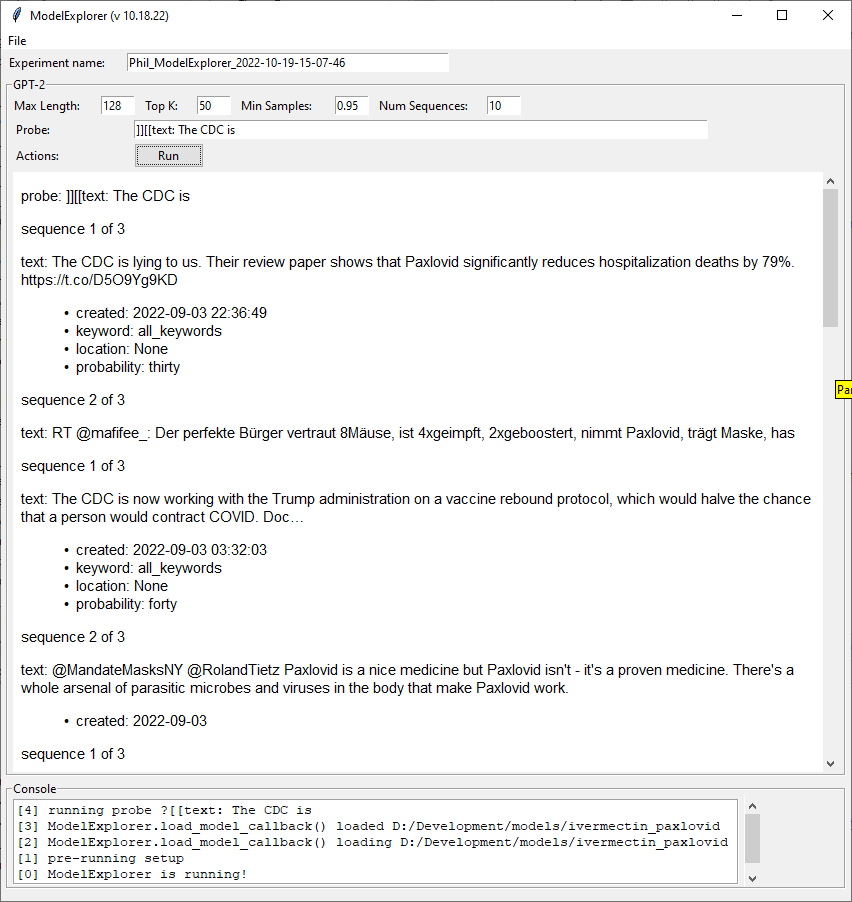
Stub out ModelExplorer. Off to a good start. The app framework is up, loading the model and running prompts. Working out how to split the output for analysis
I track my temperature every morning, along with weight and blood pressure. What can I say? I like to record data. Anyway, I came down with Covid after I came back from Spain in July, got Paxlovid and (motly) recovered in about two weeks. I still had a lingering cough, which is now completely gon. Looking back over the data, my temperature was slightly raised for two months. Not exactly Long Covid, but this thing took a looooong time to shake.
SBIRs
9:00 Meeting with Rukan to go over EntityData
Work with Aaron on paper?
Copy over the AI & Weapons paper to Overleaf for updating – done. It turns out that I don’t “own” the paper on Arxiv – Aaron Massey does. Downloaded final from Arxiv and uploaded to Overleaf
GPT Agents
Added twitter query options to TweetDownloader and a way to disable writes to the db for debugging. I’m afraid to test it given that it’s Friday and all
Fix excluded clusters – I think it’s backwards
Not sure if I want to build an App to interact with the model. I think so? If only for quick data gathering
Find and load a model
Calculate percentages
Set prompts, generate text, get embeddings and cluster
Had a good chat with Rukan about kernel methods. Looking at ways to produce information to split out features that the system struggles to learn so that they can be handled differently. This led to thinking about adding that information in as a feature and then testing the reconstruction of the feature (e.g. std dev) vs the calculation based on the output as the loss function.
Talked to Aaron to work out the experiment design
Had to do my MORS expenses AGAIN
9:15 standup
11:30 touch point
Get 3D viz working, and start on texture import and using lat/long. It looks like I can use the utm package. There are pieces missing from the directory that I don’t want to chase. Made a simpler viztest directory
GPT Agents
The computational sociology group had a meeting again! Went over stuff, and I managed to break the Embedding explorter by removing tweet_row from the view. It should be this:
That’s working now
Getting more embeddings and clusters
Struggled a bit with getting the files to save correctly
I think that this could be a really interesting way of debugging vision systems around edge cases. Mask out everything but the attribution area and run separate image-to-text models to see what they identify and then check for consensus.
This also makes me think of what it might mean for human-monitored AI systems. People will need to be trained to quickly identify if the model is behaving poorly and flag it, as opposed to if the decision is correct. It’s more like driving a race car where you have to monitor the performance of the vehicle and adapt to that. You can’t stop racing if the tires are wearing out or you’re running out of fuel. You have to adjust your behavior to optimize the behavior of the system as it is. Which implies that we need simulators of AI systems that break a lot.
Politics has in recent decades entered an era of intense polarization. Explanations have implicated digital media, with the so-called echo chamber remaining a dominant causal hypothesis despite growing challenge by empirical evidence. This paper suggests that this mounting evidence provides not only reason to reject the echo chamber hypothesis but also the foundation for an alternative causal mechanism. To propose such a mechanism, the paper draws on the literatures on affective polarization, digital media, and opinion dynamics. From the affective polarization literature, we follow the move from seeing polarization as diverging issue positions to rooted in sorting: an alignment of differences which is effectively dividing the electorate into two increasingly homogeneous megaparties. To explain the rise in sorting, the paper draws on opinion dynamics and digital media research to present a model which essentially turns the echo chamber on its head: it is not isolation from opposing views that drives polarization but precisely the fact that digital media bring us to interact outside our local bubble. When individuals interact locally, the outcome is a stable plural patchwork of cross-cutting conflicts. By encouraging nonlocal interaction, digital media drive an alignment of conflicts along partisan lines, thus effacing the counterbalancing effects of local heterogeneity. The result is polarization, even if individual interaction leads to convergence. The model thus suggests that digital media polarize through partisan sorting, creating a maelstrom in which more and more identities, beliefs, and cultural preferences become drawn into an all-encompassing societal division.
SBIRs
9:00 kernel methods discussion with Rukan. Need to look at a way of using SD to look at “outlier-ness” maybe SD of all points – SD of all other points
10:00 experiment logger review
Got GeoPandas installed!
An example for a Windows Python 3.7 install in the directory where the whl files are located would be (in order):











You must be logged in to post a comment.