Many resources on machine learning (ML) methodology recommend, or even state as crucial, that one scale (or standardize) one’s data, i.e. divide each variable by its standard deviation (after subtracting the mean), before applying Principal Component Analysis (PCA). Here we will show why that can be problematic, and provide alternatives.
Our code examples are short (less than 300 lines of code), focused demonstrations of vertical deep learning workflows.
All of our examples are written as Jupyter notebooks and can be run in one click in Google Colab, a hosted notebook environment that requires no setup and runs in the cloud. Google Colab includes GPU and TPU runtimes.
Hitting malformed descriptions in the 200k model that caused the program to crash twice. It was at 146k moves, which is probably enough to get statistics on illegal moves. Fixed the error with a try/except and moved onto the next model. I’ll go back and rerun if the fix works. Now over 100k moves on the 100k model with no problems. Yet.
Trying to work through what a malfunctioning RW would look like to the vehicle control. RW2 is critical for Roll, and RW5 is critical for Pitch and Roll. How is this system redundant?
I think I need to make some plots to understand this
So I think this is starting to make sense. There is always a point where any two rwheels are equal. You can see this on the RW1-RW4 graph. On the other, it’s just further to the left. This means that you can make them cancel and then manipulate the vehicle on the desired axis. This should be a matter of setting a scalar value such that the desired axis is nonzero. I’ll play around with that after lunch.
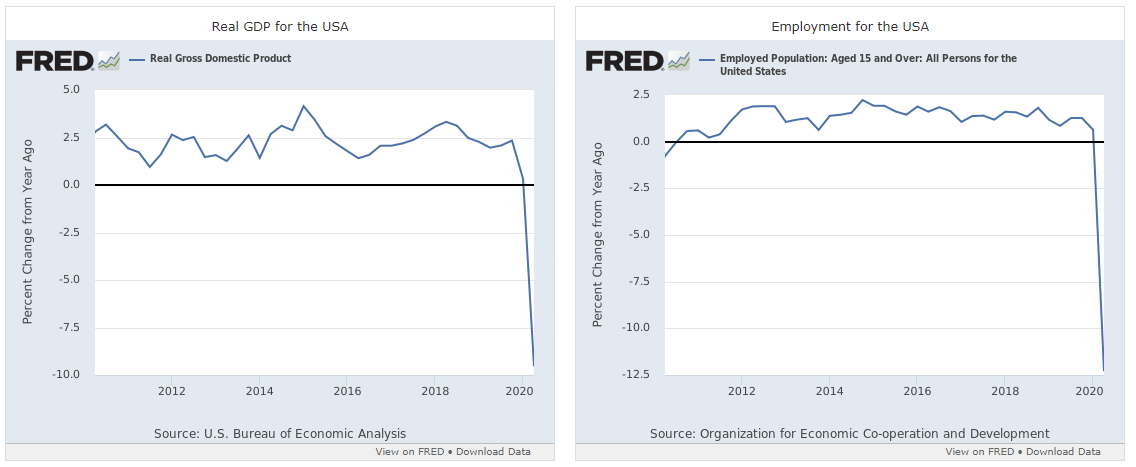
I’m a little angry today. I was engaging with a Trump supporter and they wanted to know how things would have been better under Biden. So, based on how the Obama administration handled SARS and Ebola (very well), I thought I’d try mapping a democracy that is handling the pandemic very well, which is South Korea. Both the USA and S. Korea had their first case on the same day, so it is very easy to line up the data, and then scale the S. Korean results to match the population of the USA (About 6.4). The results are staggering:
I need to write up a longer post on this and annotate the charts, but the conclusion is stark: the mismanagement of the pandemic by the administration has led to the deaths of hundreds of thousands of people who might otherwise be alive today
The Emerging Techniques Forum (ETF) is driven to improve analysis and understanding throughout the defense community by seeking out novel and leading-edge approaches, methods, and techniques – wherever they are conceived. By sharing and incorporating the latest (and in-progress) developments across government, academia, private industry, and enthusiasts, the ETF aims to support and maintain relevant, timely, and early comprehension of lessons learned that may grow to have an outsized impact on the community at large.
December 7 – 10 2020
Book
Write some content for the dimension reduction and emergence chapters – made good progress
GPT-2
Created copies of the table_moves table for the 400, 200, 100, and 50 models. It’s easy!
Created a 100 line source/translation csv file and distributed
3:00 Meeting – assigned translations
GOES
10:00 Meeting with Vadim
We went over the axis results and I realized that the pairs of reaction wheels are spinning in opposite directions, which allows for easy rotation around the vehicle primary axis. Need to figure out what the exact configurations are, but here’s the math for a hypothetical set space at 120 degrees around the z axis, and at 45 degrees with respect to an x-axis rotated the same amount
2:00 Status meeting. Nothing new. Still working on slow connectivity to the devlab
The trick to generating content without the need for much editing was understanding GPT-3’s strengths and weaknesses. “It’s quite good at making pretty language, and it’s not very good at being logical and rational,” says Porr. So he picked a popular blog category that doesn’t require rigorous logic: productivity and self-help.
GPT-2 Agents
Slides – Done!?
Start writing code to store JSON in db
#COVID
Translation is chunking along a but faster now that I’m generating 20 translations per batch
GOES
2:00 Meeting with Vadim
The rotations all look good
Explained the 3 vector reference frame rotation approach
V will characterize each RW, and then we’ll try to spin the vehicle in the XY plane
Looks like we lost the classic editor on WordPress. Sigh.
GPT-2 Agents
Updated ArXiv paper. Need to start thinking about slides for Tuesday. Started!
Book
Finished moving text to Overleaf project
2:00 Meeting with Michelle – went through the whole structure of the book, added some chapters and moved other parts around. I’m going to start roughing in the new parts
Understanding narratives requires dynamically reasoning about the implicit causes, effects, and states of the situations described in text, which in turn requires understanding rich background knowledge about how the social and physical world works. At the core of this challenge is how to access contextually relevant knowledge on demand and reason over it. In this paper, we present initial studies toward zero-shot commonsense QA by formulating the task as probabilistic inference over dynamically generated commonsense knowledge graphs. In contrast to previous studies for knowledge integration that rely on retrieval of existing knowledge from static knowledge graphs, our study requires commonsense knowledge integration where contextually relevant knowledge is often not present in existing knowledge bases. Therefore, we present a novel approach that generates contextually relevant knowledge on demand using generative neural commonsense knowledge models. Empirical results on the SocialIQa and StoryCommonsense datasets in a zero-shot setting demonstrate that using commonsense knowledge models to dynamically construct and reason over knowledge graphs achieves performance boosts over pre-trained language models and using knowledge models to directly evaluate answers.
We present the first comprehensive study on automatic knowledge base construction for two prevalent commonsense knowledge graphs: ATOMIC (Sap et al., 2019) and ConceptNet (Speer et al., 2017). Contrary to many conventional KBs that store knowledge with canonical templates, commonsense KBs only store loosely structured open-text descriptions of knowledge. We posit that an important step toward automatic commonsense completion is the development of generative models of commonsense knowledge, and propose COMmonsEnse Transformers (COMET) that learn to generate rich and diverse commonsense descriptions in natural language. Despite the challenges of commonsense modeling, our investigation reveals promising results when implicit knowledge from deep pre-trained language models is transferred to generate explicit knowledge in commonsense knowledge graphs. Empirical results demonstrate that COMET is able to generate novel knowledge that humans rate as high quality, with up to 77.5% (ATOMIC) and 91.7% (ConceptNet) precision at top 1, which approaches human performance for these resources. Our findings suggest that using generative commonsense models for automatic commonsense KB completion could soon be a plausible alternative to extractive methods.
GOES
10:00 sim status meeting – planning to fully evaluate off-axis rotation by Monday, then characterize Rwheel contribution, adjust the control system and start commanding vehicle rotations by the end of the week? Seems ambitions, but what the hell.
2:00 status meeting
Anything about GVSETS? Yup: Meeting Wed 9/16/2020 9:00 AM – 10:00 AM
JuryRoom
5:30 meeting. Discuss proposal and additional meetings
For next week, create a spreadsheet with 150 random tweets for translation tests (Pearson’s correlation?)
GPT2-Agents
Creating code that dumps probe results to files for better word clouds – done.
Boy, that produced some unexpected results. I changed the probe to “The man/woman walked into the room.”, and ran 100 probes for each, initializing with the same seed on the 117 million parameter GPT-2, which seems plenty large for these types of experiments.
The big surprise if how similar the start of the text is for each, then how it diverges. Here’s the first result for each probe (all text examples are ordered man, then woman):
This was about the time that an old friend of mine made his move and was going to be a huge help for me. I thought to myself and began crying. The thought of an old friend crying seemed almost too much, but I didn’t want to hurt him as much. My mind was racing, but all I could think about was how much the boy was hurting right now. He still wasn’t strong,
This was about the time that an accident really occurred. She had just turned up a couple hours earlier at the home they owned and hadn’t seen her since. She had a bad haircut and she couldn’t sit still and look after herself. When the accident happened, she didn’t even have her hair cut. She was so exhausted, she started crying. She was so exhausted and crying. After
And here’s the last:
He spoke, “I can’t believe there’s this situation here. This is very, very weird.” I told him I felt scared, and he replied, “You’re probably right about that, but I don’t know what it’s about.” He didn’t respond, and I was left thinking, “I’m sure I’m not alone in this crazy situation.” The next day, I went back to meet him. “He’s
She spoke, “I can’t believe there’s this situation here. This is very, very painful.” I told her I felt scared and I was upset. She said “I’ll tell you what I saw when I saw him.” I told her “He’s so skinny but the black hair looks gorgeous, he looks beautiful. “She started crying and began giving me some food and asking if I were alright. “
Here’s another good pairing:
It wasn’t that it was a bad situation. He just wasn’t feeling it. He felt that he wasn’t going to get laid, and if anything, he didn’t think it would help him get off. “We’ll go, then,” the woman said. There was still an argument at the back, but now it wasn’t too much worse. The woman had been arguing with the man, but the man was not
It wasn’t that it was a bad situation. That just wasn’t the case. She was just a little shy and reserved and didn’t really need anything to do with it. I had been on the phone with Amy for the last week. When I found out that she wanted to join me in our recent trip I was pretty bummed out. That’s when Amy started to feel bad about herself. For
The pairs don’t always begin with the same words. This pair still seems to have a legal/criminal context:
He handed out a number of hand-written handbags, which he claimed could be used to carry out a search that began when he first moved into the room. The door was then locked and the man went into the bathroom, which he said was the safest place. It was the first time the intruder had ever been caught, and the man said it was the second time they’d been spotted outside the residence. The man was
The two officers were holding their guns. As the woman made her way to her seat, she saw two men on a motorcycle walking towards her. She asked the man why he was not in the car with her. The man explained that he was afraid of the two men driving. The officers explained that she had to have sex and to stay with the men. The woman was terrified of the officers as the men drove away with their cameras and other equipment
It’s like the model start in similar places, but pointing in a slightly different direction. It seems to be important to run probes in identical sequences to have more insight into the way the model is perceiving the probes.
GOES
1:30 Meeting with Vadim. He’s don an on-axis mass test and will do an off-axis test next. I showed him the quaternion frame tracker
In this post, I will present a few techniques, both from published research and our own experiments at Hugging Face, for using state-of-the-art NLP models for sequence classification without large annotated training sets.
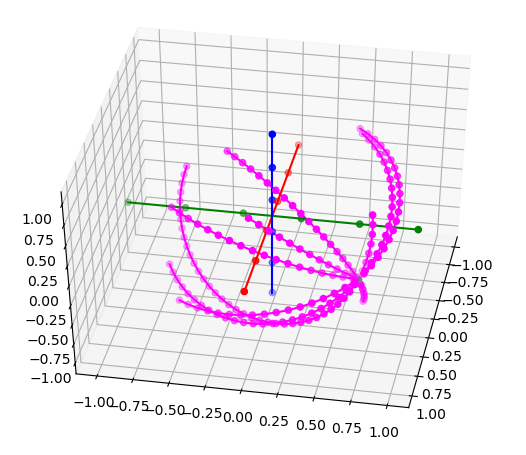
I think I realize my problem about the second axis. It’s not rotating around the origin, so the vectors that I’m using to create the rotation vectors are not right.
Fixed! Here are some rotations (180 around Z, 90 around x, and 360 around z, 180 around x)
GPT-2 Agents
I did 11 runs of S/He walked into the room and made word clouds:
I’m going to re-run this on my GPT-2 so I can have a larger N. Just need to do some things to the test code to output to a file
ICTAI
Finished the last review. The last paper was an ontological model with no computation in it
Uploaded and finished!
ML seminar
I have access to the Twitter data now. Need to download and store it in the db
Recent progress in pretraining language models on large textual corpora led to a surge of improvements for downstream NLP tasks. Whilst learning linguistic knowledge, these models may also be storing relational knowledge present in the training data, and may be able to answer queries structured as “fill-in-the-blank” cloze statements. Language models have many advantages over structured knowledge bases: they require no schema engineering, allow practitioners to query about an open class of relations, are easy to extend to more data, and require no human supervision to train. We present an in-depth analysis of the relational knowledge already present (without fine-tuning) in a wide range of state-of-the-art pretrained language models. We find that (i) without fine-tuning, BERT contains relational knowledge competitive with traditional NLP methods that have some access to oracle knowledge, (ii) BERT also does remarkably well on open-domain question answering against a supervised baseline, and (iii) certain types of factual knowledge are learned much more readily than others by standard language model pretraining approaches. The surprisingly strong ability of these models to recall factual knowledge without any fine-tuning demonstrates their potential as unsupervised open-domain QA systems. The code to reproduce our analysis is available at this https URL.
#COVID
Currently at 103, 951 tweets translated
JuryRoom
Write reference section – done
GOES
I need to do an incremental rotation to track the reference points from last week
Still having problems with the secondary rotation. I’m clearly doing something basic wrong
Meeting with Vadim
GPT-2 Agents
Create a word cloud for multiple passes of “She came into the room”
Add something about the place for qualitative research in a Language model sociology. Outliers are the places that the models learn to ignore. So traditional research will be the way that these marginalized populations are not forgotten.
Screwed up the ArXiv bibliography submission. Fixed
ICTAI
Started reading the last paper, which is on <shudder> ontologies
The Arabic translation program is chunking along. It’s translated over 27,000 tweets so far. I think I’m seeing the power and risks of AI/ML in this tiny example. See, I’ve been programming since the late 1970’s, in many, many, languages and environments, and the common thread in everything I’ve done was the idea of deterministic execution. That’s the idea that you can, if you have the time and skills, step through a program line by line in a debugger and figure out what’s going on. It wasn’t always true in practice, but the idea was conceptually sound.
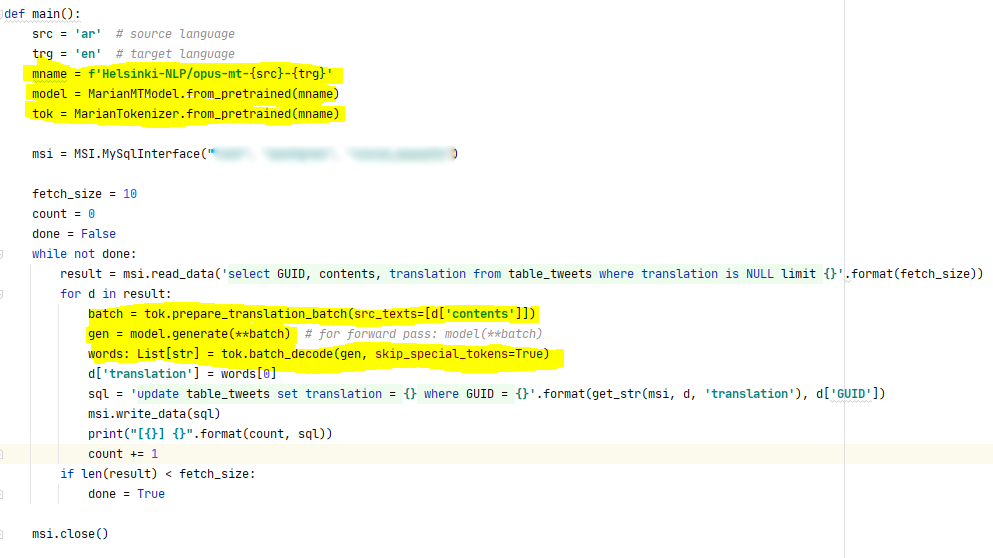
This translation program is entirely different. To understand why, it helps to look at the code:
This is the core of the code. It looks a lot like code I’ve written over the years. I open a database, get some lines, manipulate them, and put them back. Rinse, lather, repeat.
batch = tok.prepare_translation_batch(src_texts=[d['contents']])
gen = model.generate(**batch) # for forward pass: model(**batch)
words: List[str] = tok.batch_decode(gen, skip_special_tokens=True)
The first line is straightforward. It converts the Arabic words to tokens (numbers) that the language model works in. The last line does the reverse, converting result tokens to english.
The middle line is the new part. The input vector of tokens is goes to the input layer of the model, where they get sent through a 12-layer, 512-hidden, 8-heads, ~74M parameter model. Tokens that can be converted to English pop put the other side. I know (roughly) how it works at the neuron and layer level, but the idea of stepping through the execution of such a model to understand the translation process is meaningless.
In the time it took to write this, its translated about 1,000 more tweets. I can have my Arabic-speaking friends to a sanity check on a sample of these words, but we’re going to have to trust the overall behavior of the model to do our research in, because some of these systems only work on English text.
So we’re trusting a system that we cannot verify to to research at a scale that would otherwise be impossible. If the model is good enough, the results should be valid. If the model behaves poorly, then we have bad science. The problem is right now there is only one Arabic to English translation model available, so there is no way to statistically examine the results for validity.
And I guess that’s really how we’ll have to proceed in this new world where ML becomes just another API. Validity of results will depend on diversity on model architectures and training sets. That may occur naturally in some areas, but in others, there may only be one model, and we may never know the influences that it has on us.
GOES
More quaternions. Need to do multiple axis movement properly. Can you average two quaternions and have something meaningful?
Here’s the reference frame with two rotations based off of the origin, so no drift. Now I need to do an incremental rotation to track these points:
We show that the transformer attention mechanism is the update rule of a modern Hopfield network with continuous states. This new Hopfield network can store exponentially (with the dimension) many patterns, converges with one update, and has exponentially small retrieval errors. The number of stored patterns is traded off against convergence speed and retrieval error. The new Hopfield network has three types of energy minima (fixed points of the update): (1) global fixed point averaging over all patterns, (2) metastable states averaging over a subset of patterns, and (3) fixed points which store a single pattern. Transformer and BERT models operate in their first layers preferably in the global averaging regime, while they operate in higher layers in metastable states. The gradient in transformers is maximal for metastable states, is uniformly distributed for global averaging, and vanishes for a fixed point near a stored pattern. Using the Hopfield network interpretation, we analyzed learning of transformer and BERT models. Learning starts with attention heads that average and then most of them switch to metastable states. However, the majority of heads in the first layers still averages and can be replaced by averaging, e.g. our proposed Gaussian weighting. In contrast, heads in the last layers steadily learn and seem to use metastable states to collect information created in lower layers. These heads seem to be a promising target for improving transformers. Neural networks with Hopfield networks outperform other methods on immune repertoire classification, where the Hopfield net stores several hundreds of thousands of patterns. We provide a new PyTorch layer called “Hopfield”, which allows to equip deep learning architectures with modern Hopfield networks as a new powerful concept comprising pooling, memory, and attention. GitHub: this https URL
Going to try to get the translator working and inserting best effort into the DB. They we can make queries for the good results. Done! Here’s a shot of it chunking away. About one translation a second:
Updating my work box. Had a weird experience upgrading pip. It hit a permissions issue and failed out without rolling back. I had to use get-pip.py to get it back















You must be logged in to post a comment.