
D20
- Everything is silent again.
GPT-2 Agents
- Continuing with PGNtoEnglish
- Building out move text
- Changing board to a dataframe, since I can display it as a table in pyplot – done!

- Here’s the code for making the chesstable table in pyplot:
import pandas as pd import matplotlib.pyplot as plt class Chessboard(): board:pd.DataFrame rows:List cols:List def __init__(self): self.reset() def reset(self): self.cols = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'] self.rows = [8, 7, 6, 5, 4, 3, 2, 1] self.board = df = pd.DataFrame(columns=self.cols, index=self.rows) for number in self.rows: for letter in self.cols: df.at[number, letter] = pieces.NONE.value self.populate_board() self.print_board() def populate_board(self): self.board.at[1, 'a'] = pieces.WHITE_ROOK.value self.board.at[1, 'h'] = pieces.WHITE_ROOK.value self.board.at[1, 'b'] = pieces.WHITE_KNIGHT.value self.board.at[1, 'g'] = pieces.WHITE_KNIGHT.value self.board.at[1, 'c'] = pieces.WHITE_BISHOP.value self.board.at[1, 'f'] = pieces.WHITE_BISHOP.value self.board.at[1, 'd'] = pieces.WHITE_QUEEN.value self.board.at[1, 'e'] = pieces.WHITE_KING.value self.board.at[8, 'a'] = pieces.BLACK_ROOK.value self.board.at[8, 'h'] = pieces.BLACK_ROOK.value self.board.at[8, 'b'] = pieces.BLACK_KNIGHT.value self.board.at[8, 'g'] = pieces.BLACK_KNIGHT.value self.board.at[8, 'c'] = pieces.BLACK_BISHOP.value self.board.at[8, 'f'] = pieces.BLACK_BISHOP.value self.board.at[8, 'd'] = pieces.BLACK_KING.value self.board.at[8, 'e'] = pieces.BLACK_QUEEN.value for letter in self.cols: self.board.at[2, letter] = pieces.WHITE_PAWN.value self.board.at[7, letter] = pieces.BLACK_PAWN.value def print_board(self): fig, ax = plt.subplots() # hide axes fig.patch.set_visible(False) ax.axis('off') ax.axis('tight') ax.table(cellText=self.board.values, colLabels=self.cols, rowLabels=self.rows, loc='center') fig.tight_layout() plt.show()
GOES
- Continuing with the MLP sequence-to-sequence NN
- Writing
- Reading
- Hmm. Just realized that the input vector being defined by the query is a bit problematic. I think I need to define the input vector size and then ensure that the query creates sufficient points. Fixed. It now stores the model with the specified input vector size:

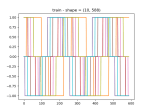
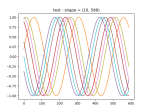
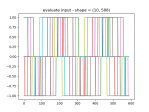
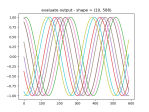
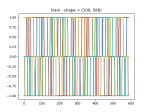
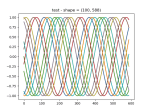
- And here’s the loaded model in newly-retrieved data:


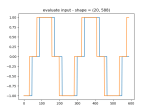
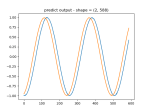
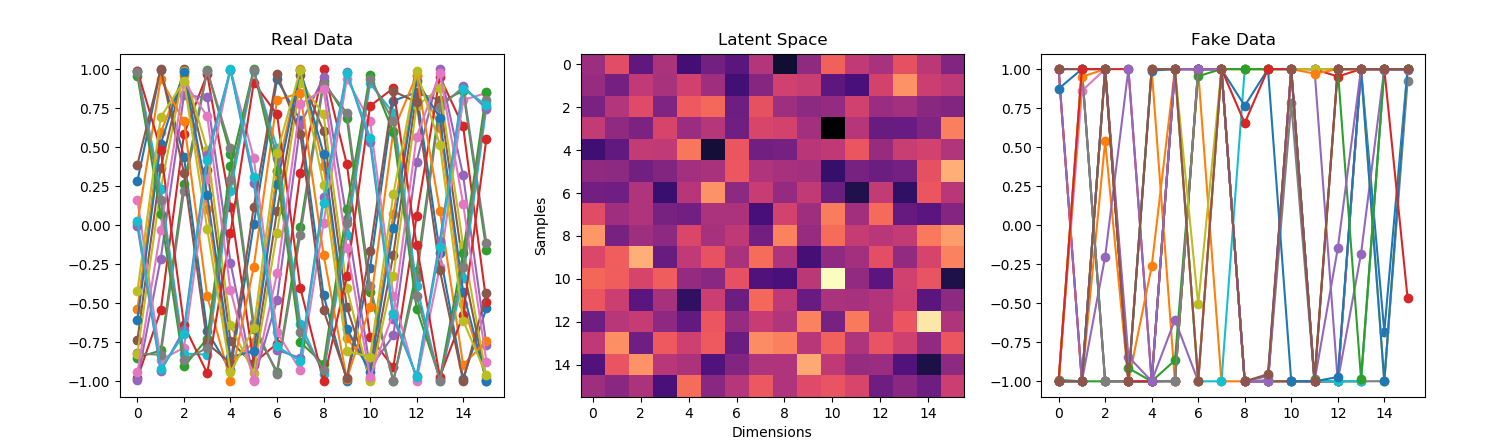
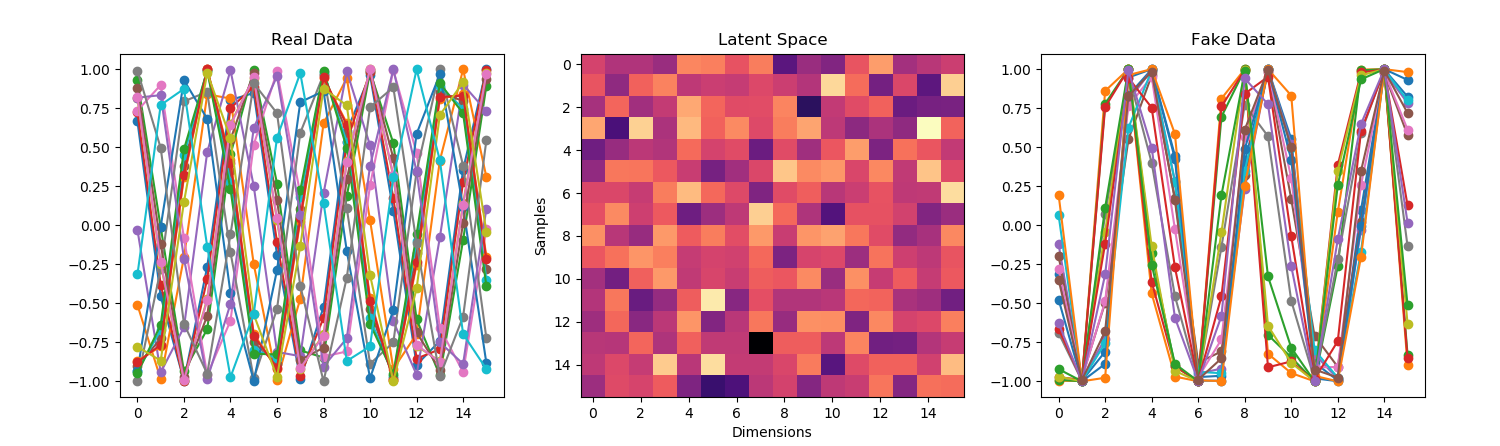
- Here’s the model learning two waveforms. Went from 400×2 neurons to 3200×2:


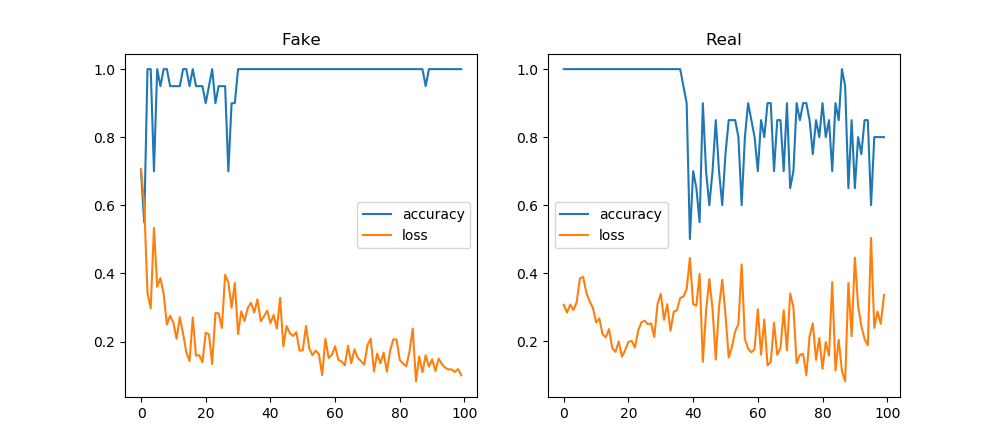
- Combining with GAN
- Subtract the sin from the noisy_sin to get the moise and train on that
- Start writing paper? What are other venues beyond GVSETS?
- 2:00 status meeting
JuryRoom
- 3:30 Meeting
- 6:00 Meeting




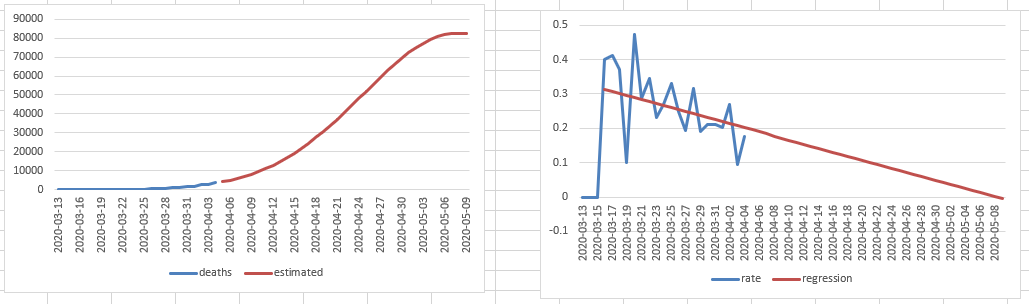

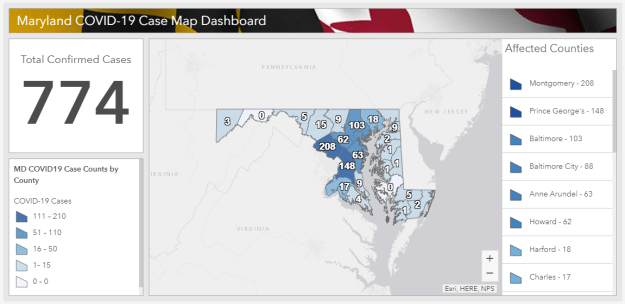
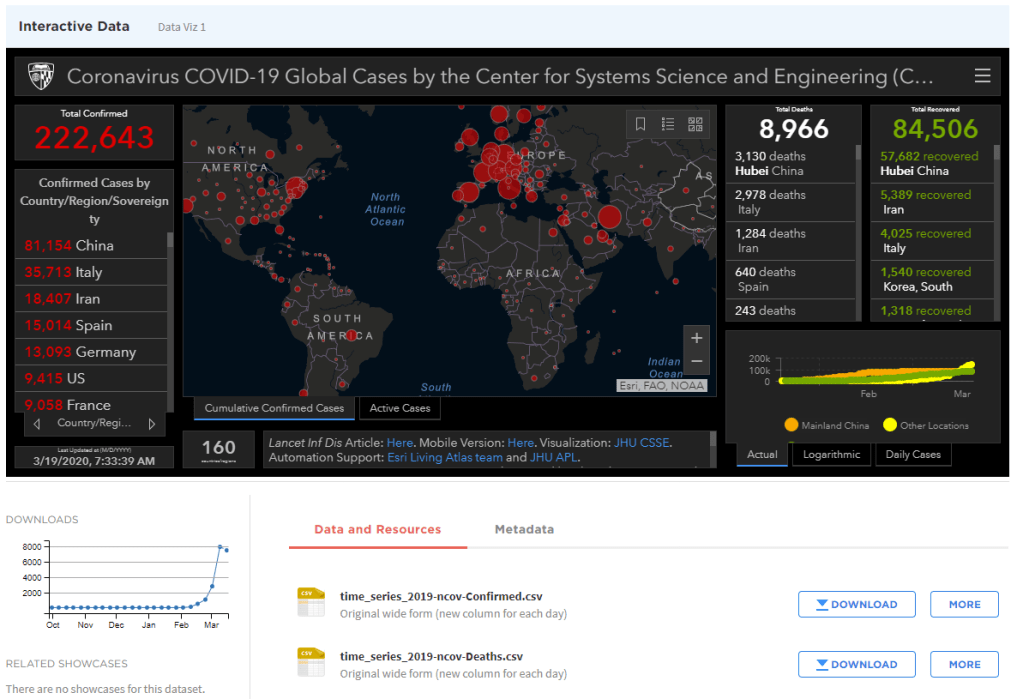
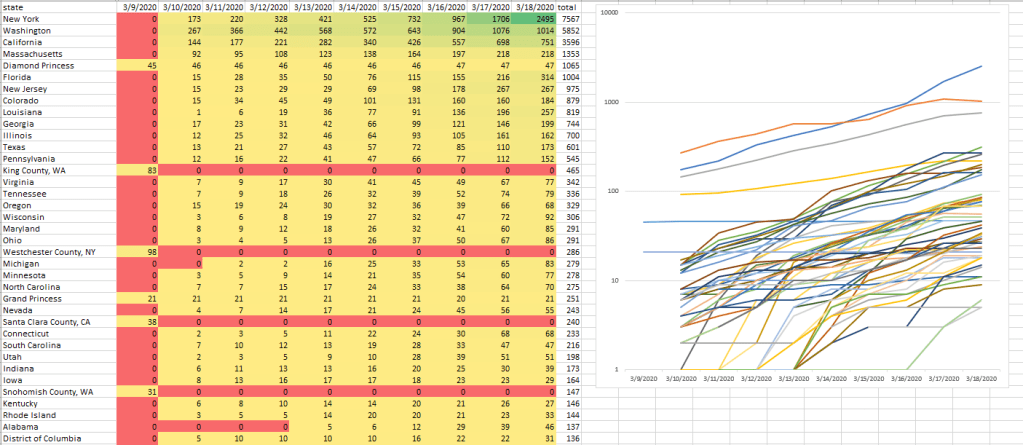






You must be logged in to post a comment.