
#COVID
- I looked at the COVID-19-TweetIDs GitHub project, and it is in fact lists of ids:
1219755883690774529 1219755875407224832 1219755707001659393 1219755610494861312 1219755586272813057 1219755378428338181 1219755293397012480 1219755288988798981 1219755197645279233 1219755157438828545
- These can work by appending that number to the string “twitter.com/anyuser/status/”, like this: twitter.com/anyuser/status/1219755883690774529
- The way to get the text in Python appears to be tweepy. This snippet from stackoverflow appears to show how to do it, but I haven’t verified yet.
import tweepy consumer_key = xxxx consumer_secret = xxxx access_token = xxxx access_token_secret = xxxx auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) tweets = api.statuses_lookup(id_list) # id_list is the list of tweet ids tweet_txt = [] for i in tweets: tweet_txt.append(i.text)
GPT-2 Agents
- Continuing with PGNtoEnglish
- Figuring out how to parse the moves text, using the wonderful regex101 site
- 4:30 meeting
- We set up an Overleaf project with the goal to submit to the Harvard/Kennedy Misinformation Review
- We talked about the GPT-2 as a way of clustering tweets. Going to try finetuning with some Arabic novels first to see if it can work in that language
GOES
- Continuing with the MLP sequence-to-sequence NN
- Getting the data to fit into nice, rectangular arrays, which is no straightforward, since the time window of the query can return a varying number of results. So I have to run the query, then trim the arrays down so that they are all the length of the shortest. Here’s the results:
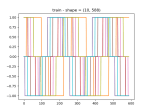
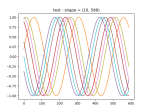
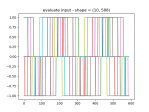
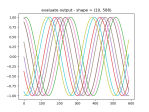
- I’ve got the training and prediction working pretty well. Stopping for the day
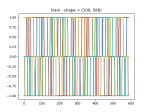
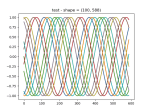
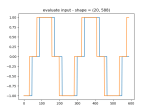
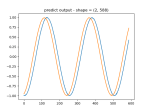
- Tomorrow I’ll get the models to write out and read in
- 2:00 status meeting
- Two weeks to getting the sim running?
