
Our code examples are short (less than 300 lines of code), focused demonstrations of vertical deep learning workflows.
All of our examples are written as Jupyter notebooks and can be run in one click in Google Colab, a hosted notebook environment that requires no setup and runs in the cloud. Google Colab includes GPU and TPU runtimes.
- Image classification from scratch
- Simple MNIST convnet
- Image segmentation with a U-Net-like architecture
- OCR model for reading Captchas
- Next-frame prediction with Conv-LSTM
- Grad-CAM class activation visualization
- Image classification via fine-tuning with EfficientNet
- Model interpretability with Integrated Gradients
- Metric learning for image similarity search
- Point cloud classification with PointNet
- Few-Shot learning with Reptile
- Object Detection with RetinaNet
- Visualizing what convnets learn
- Pneumonia Classification on TPU
- Text classification from scratch
- Sequence to sequence learning for performing number addition
- Bidirectional LSTM on IMDB
- Character-level recurrent sequence-to-sequence model
- Using pre-trained word embeddings
- Text classification with Transformer
- BERT (from HuggingFace Transformers) for Text Extraction
- Structured data classification from scratch
- Collaborative Filtering for Movie Recommendations
- Imbalanced classification: credit card fraud detection







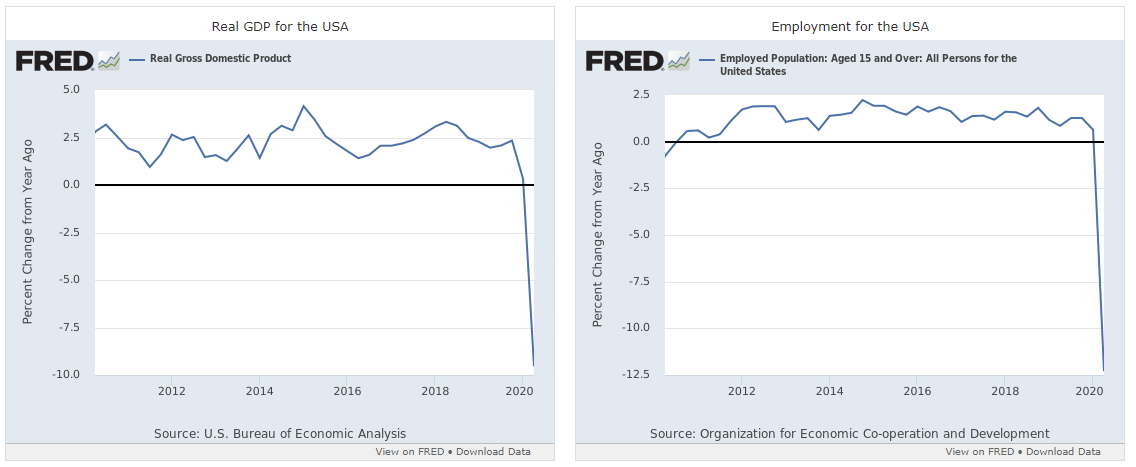




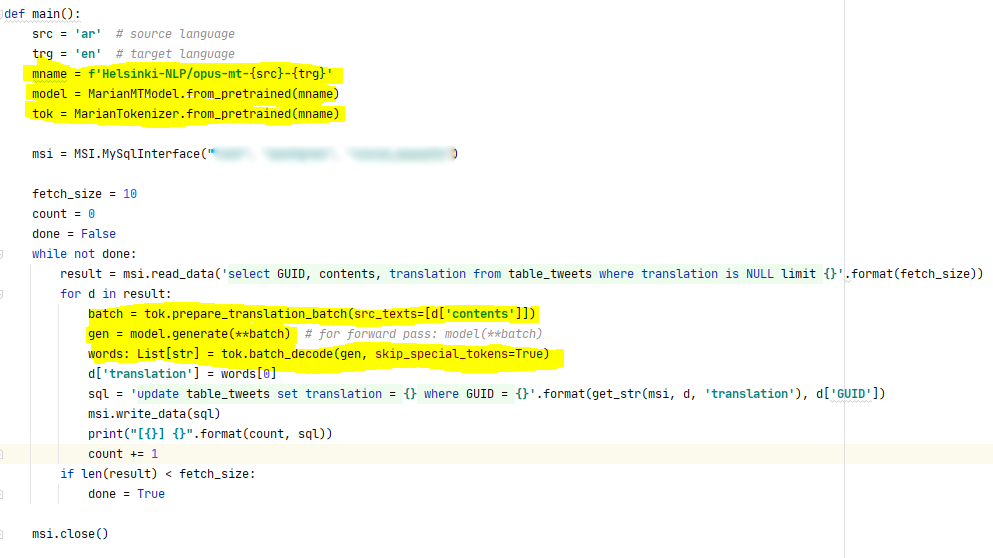
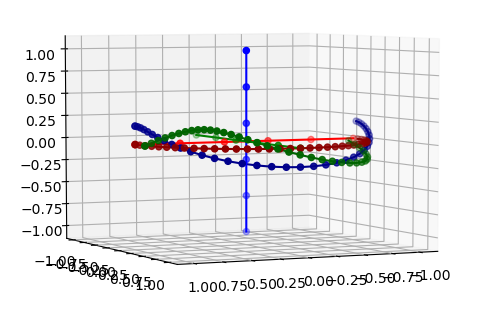
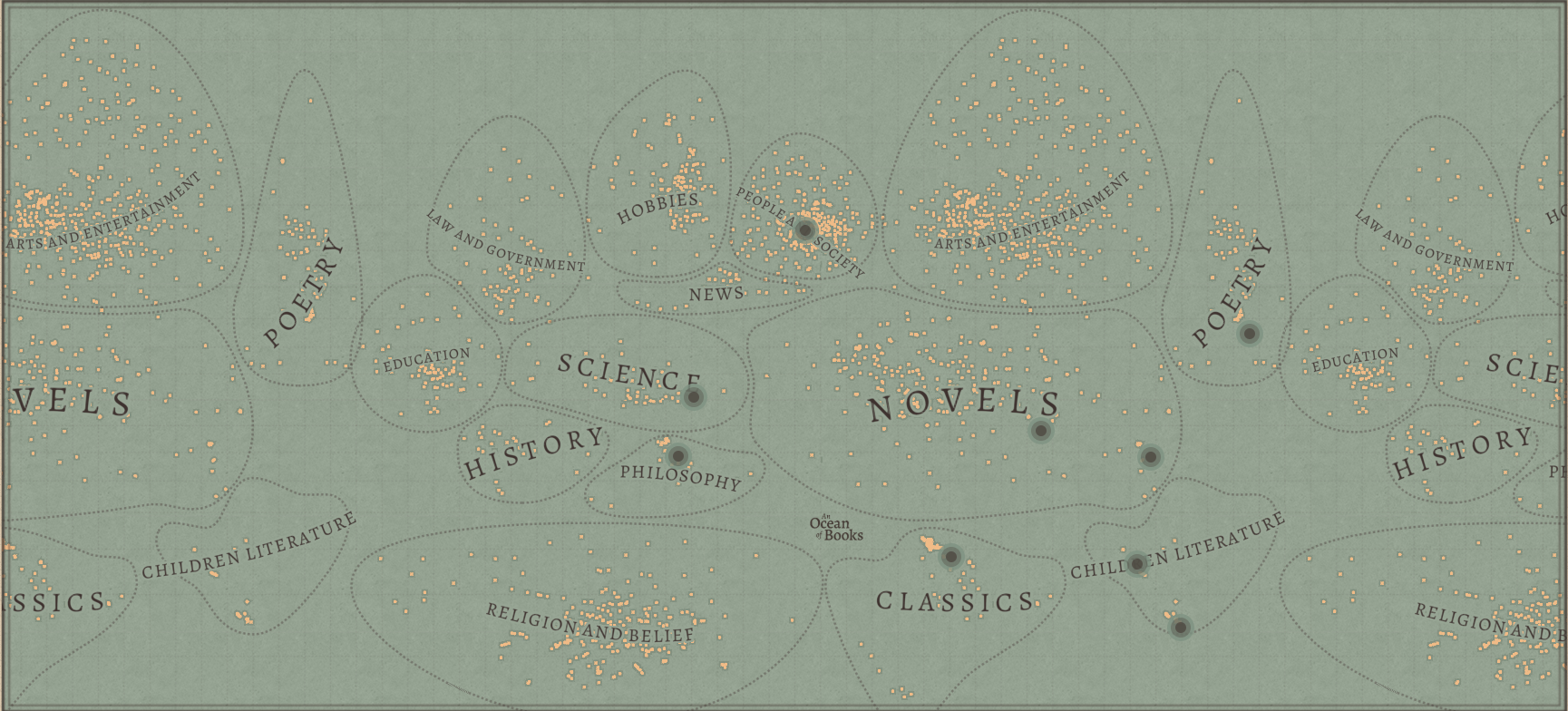


You must be logged in to post a comment.