Had a nice chat with Rukan about how to partition models. Which made me think about RCS again. Maybe make a pyRCS library? I have the code written already, just need to pull it out of the PyBullet project
Polarization has become a force that feeds on itself, gaining strength from the hostility it generates, finding sustenance on both the left and the right. A series of recent analyses reveals the destructive power of polarization across the American political system.
GPT Agents
I think OpenAI’s embeddings may have gone public – Yes!
We’ve trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. These InstructGPT models, which are trained with humans in the loop, are now deployed as the default language models on our API.
Had a long and winding talk about quality in Twitter data and whether using thread is a way to increase that. Shimei’s thought is that it will bias the data towards a different population. I think that’s reasonable, but I’m not sure that matters as long as you specify what population you’re polling.
Got the recent conversation search working
Working on historical queries
Getting historical Tweets using the v2 full-archive search endpoint
We invite submissions from the NLP and HCI communities as well as industry practitioners and professional writers on the topic of intelligent writing assistants: those that discuss innovations in building, improving, and evaluating intelligent and interactive writing assistants.
Specific topics include, but not limited to:
Combining NLP techniques (e.g. style transfer, text planning, controllability) with interaction paradigms between users and writing assistants (e.g. interfaces, iterative processes, feedback), such as a formality style transfer system for revising professional communications
Assistance on different stages of the writing process (e.g. planning, revising), different types of writing (e.g. expository, persuasive), and different applications (e.g. journalism, fiction)
Evaluation methodologies for writing assistants, writing process, and resultant text
Addressing underrepresentation of languages, types of writers (e.g. vernacular variations), and writing tasks for targeted writing assistance (note that for non-English systems, we request that the figures and examples be translated into English prior to review)
Writing assistant ownership issues, including legal issues with copyright and psychological sense of ownership
Practical challenges for building real-world systems such as Grammarly and WordTune (e.g. latency, near-perfect quality, personalization, and evolution of language)
User studies or ethnographic studies of writers who use writing assistants
Demonstration of simple prototypes of intelligent interfaces or design sketches
Book
Rewriting the first chapter around the concept that “belief is a place”
SBIRs
9:15 Stand up
Helped Aaron set up his DB, more today
Meeting with Rukan
Do RoE map. Add nodes
The Enemy (“The enemy is”)
Fire Back (“If someone shoots at you”)
Masculine (“Be tough”)
Lawless (“Whatever it takes”)
Self Protect (“First, defend yourself”)
Kill the Enemy (“Don’t be complicated”)
Tactics (“Have a plan and execute it”)
Proportional (“Don’t escalate”)
Responsible (“Do the right thing”)
Independence (“Don’t just follow orders”)
Civilians (“What to do with non-combatants”)
Careful (“Don’t get into trouble”)
Our Guys (“We come first”)
Hold Fire (“Do not fire unless absolutely necessary”)
Every morning, I get up, put something mellow on the stereo and do my morning things. So, like every morning I push the power button on the amp, there’s a slight scratching sound, and… nothing. Blown fuse. Sigh. Nothing like looking for a 5mf 8a 125v glass fuse at 5:00am
Spent too much time making a better placeholder callback:
def implement_me(self):
"""
A callback to point to when you you don't have a method ready. Prints "implement me!" to the output and
an abbreviated version of the call stack to the console
:return:
"""
#self.dprint("Implement me!")
self.dp.dprint("Implement me! (see console for call stack)")
fi:inspect.FrameInfo
count = 0
for fi in inspect.stack():
filename = re.split(r"(/)|(\\)", fi.filename)
print("Call stack[{}] = {}() (line {} in {})".format(count, fi.function, fi.lineno, filename[-1]))
count += 1
9:15 Standup
Aaron has topic clustering working:
GPT Agents
Put together a doc with existing and new prompts (“Vaccines are”, “Vaccines are a”, “I/We/<other groups> think that vaccines are”)
I need to do some research on if the API can really do this, but I’d like to make the new corpus of threadedtweets that are pulled because they mention general terms like “COVID”, “VIRUS”, and “VACCINE”, then train the models and drill down. I still like the idea of training monthly models starting in Nov 2019 to present.
Got the paper submitted last Saturday! April 7 is when we’ll find out
4:30 Meeting. We worked on what to do next. We are going to look at the monthly models from 2020 and see how their responses move with respect to embedding space and the same prompt. The first step is to collect the prompts we used from the paper and see if we want to add any new ones
SBIRs
9:15 Sprint planning. Need to write up some stories
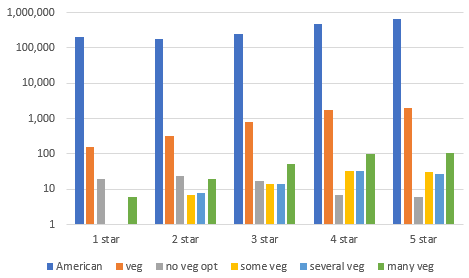
compute an error metric (L1 difference) for the estimated proportion of positive reviews for “gray bars” (GPT with the reviews containing the keywords held out) vs the ground truth “blue bars” . Report this error metric in a table (performance of our method). – done
simulate the empirical count baseline method in the low data scenario: draw a small number of reviews containing the keyword, let’s say 6 of them). Compute the error metric (L1 difference) for the empirical counts baseline, computed on this subset, vs the ground truth “blue bars”. Repeat this many times (say, 10,000 times). Report the average error metric in a table (performance of the baseline method). – done
Finished the data extraction. Now I have to make spreadsheets and charts.
Very happy with this:
Fix the TODOs – Done
The last thing to do is fill out the ethics form and submit
Continue on interpolation section. Set up the pretrained average stars in a table and drop the figure. Show the bar chart and Pearson’s
Add comparison of GPT and GPT(v). Chart? Table? And show Pearson’s
1:00 – 2:30 Meeting
Good progress. I need to do for the three star rating category:
compute an error metric (L1 difference) for the estimated proportion of positive reviews for “gray bars” (GPT with the reviews containing the keywords held out) vs the ground truth “blue bars” . Report this error metric in a table (performance of our method).
simulate the empirical count baseline method in the low data scenario: draw a small number of reviews containing the keyword, let’s say 6 of them). Compute the error metric (L1 difference) for the empirical counts baseline, computed on this subset, vs the ground truth “blue bars”. Repeat this many times (say, 10,000 times). Report the average error metric in a table (performance of the baseline method).
Finished the data extraction. Now I have to make spreadsheets and charts
I think I want to put the results into three sections: 1) Memorization, or the learning of the meta-wrapper, 2) Interpolation, or how the model re-creates correct reviews 3) Extrapolation, how the model creates new (zero shot) reviews
Add a section to the beginning of the methods section stating that all finetuning was done on the Huggingface GPT-2 117M parameter model.
For speed (easier to produce a model for comparison)
For the environment
To show that state-of-the art insight into TLMs does not require building large models
I think that a good way to show how this matters is to use TTestIndPower to calculate the minimum sample size to determine if the populations are different as described in this tutorial
Write up the points from the discussion with Aaron last Friday. I think it will make a much better direction than trying to figure out how to automate the current manual approach
Continue code cleanup. There is still something that makes the radius of a MoveableNode grow wrong when the item count is incremented (maybe fixed? Line 34 of in MapData.Maptopic.adjust_force_node())
GPT Agents
Start writing the paper and see what shakes out
Ask to reschedule Tuesday’s meeting – done
Book
I got a visualization that I like. Now I need to rewrite the chapter a bit around it. I think just the main visualization should be ok, with maybe different perspectives?
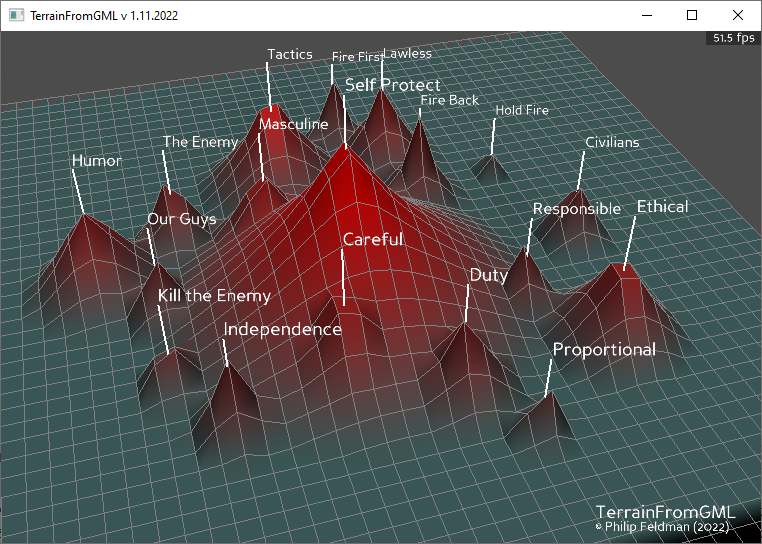
The new conspiracy map
Maybe also generate a “philosophy” terrain? I’d need to have some code to handle a rollover for the z value
It snowed again! I think that’s more snow in one week than the past two years
GPT Agents
Need to compare the performance of each model for each probe and compare to ground truth. One thing to point out is how little data there is to sample:
SBIRs
Fixing the “find matching”
Make node size log-based
Book
Put together some more data. Need to change the maps a bit















You must be logged in to post a comment.