
#COVID
- Got a response back from Huggingface. They can’t replicate. sent more info
GPT-2 Agents
- Adding better date handling
- Fixed tied game text
- Added some randomization to sentence beginnings
- Added an overall description of the game. Today’s progress:
On January 21, 2020, F Caruana played Ding Liren. F Caruana was the higer-ranked player, with an Elo rating of 2835. Ding Liren was the lower-ranked player, with an Elo rating of 2791. After 73 moves, the game ended in a draw. The game began with ECO opening B90: The game begins as White moves pawn from e2 to e4. Black moves pawn from c7 to c5. White moves knight from g1 to f3. Ding Liren moves black pawn from d7 to d6. White moves pawn from d2 to d4. Black moves pawn from c5 to d4. Black takes white pawn. White moves knight from f3 to d4. White takes black pawn. Black moves knight from g8 to f6. In move 5, F Caruana moves white knight from b1 to c3. Black moves pawn from a7 to a6. F Caruana moves white queen from d1 to d3. Ding Liren moves black pawn from e7 to e6.
GOES
- I’m using the OneDGAN2 as a base class to do experiments with. That way, the subclass only needs a generator and/or a discriminator:
class OneDGAN2a(ODG.OneDGAN2): def __init__(self): super().__init__() # create the Keras model to generate fake data (Dense to CNN) def define_generator(self) -> Sequential: self.g_model = Sequential() self.g_model.add(Dense(64, activation='relu', kernel_initializer='he_uniform', input_dim=self.latent_dimension)) self.g_model.add(BatchNormalization()) self.g_model.add(Dense(self.vector_size, activation='tanh')) self.g_model.add(Reshape((self.vector_size, 1))) print("g_model_Dense.output_shape = {}".format(self.g_model.output_shape)) # compile model loss_func = tf.keras.losses.BinaryCrossentropy() opt_func = tf.keras.optimizers.Adam(0.001) self.g_model.compile(loss=loss_func, optimizer=opt_func) return self.g_model # define the standalone discriminator model def define_discriminator(self) -> Sequential: # activation_func = tf.keras.layers.LeakyReLU(alpha=0.02) activation_func = tf.keras.layers.ReLU() self.d_model = Sequential() self.d_model.add(Conv1D(filters=self.vector_size, kernel_size=20, strides=4, activation=activation_func, batch_input_shape=(self.num_samples, self.vector_size, 1))) self.d_model.add(Dropout(.3)) self.d_model.add(GlobalMaxPool1D()) self.d_model.add(Flatten()) self.d_model.add(Dense(self.vector_size/2, activation=activation_func, kernel_initializer='he_uniform', input_dim=self.vector_size)) self.d_model.add(Dropout(.3)) self.d_model.add(Dense(1, activation='sigmoid')) # compile model loss_func = tf.keras.losses.BinaryCrossentropy() opt_func = tf.keras.optimizers.Adam(0.001) self.d_model.compile(loss=loss_func, optimizer=opt_func, metrics=['accuracy']) return self.d_modelWhich means that I can keep running instances rather than just notes
- Continuing with Advanced Deep Learning with Keras
- Another writeup of Wasserstein Loss cited in the book is here, with the associated TF code here. It’s from 3 years ago, so the TF version is waaaaaay out of date. That being said, the loss function is mostly straight java code:
if self.model_type == self.WGAN_GP: # Wasserstein GAN with gradient penalty epsilon = tf.random_uniform([self.batch_size, 1, 1, 1], 0.0, 1.0) interpolated = epsilon * inputs + (1 - epsilon) * self.G _, self.D_logits_intp_ = self.discriminator(interpolated, self.y, reuse=True) # tf.gradients returns a list of sum(dy/dx) for each x in xs. gradients = tf.gradients(self.D_logits_intp_, [interpolated, ], name="D_logits_intp")[0] grad_l2 = tf.sqrt(tf.reduce_sum(tf.square(gradients), axis=[1, 2, 3])) grad_penalty = tf.reduce_mean(tf.square(grad_l2 - 1.0)) self.gp_loss_sum = tf.summary.scalar("grad_penalty", grad_penalty) self.grad_norm_sum = tf.summary.scalar("grad_norm", tf.nn.l2_loss(gradients)) # Add gradient penalty to the discriminator's loss function. self.d_loss += self.gp_lambda * grad_penalty
- Another writeup of Wasserstein Loss cited in the book is here, with the associated TF code here. It’s from 3 years ago, so the TF version is waaaaaay out of date. That being said, the loss function is mostly straight java code:
- Here’s the approach to a WGAN. Pretty much the same, except for the loss function
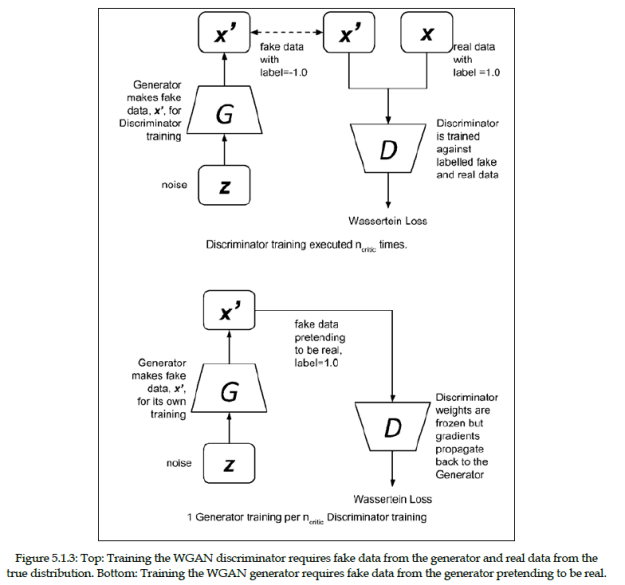
- Note that the WGAN labels fake data as -1 rather than 0.
- Starting to implement. Figured out how to do the first part of Wasserstein Loss, which also includes using RMSProp rather than Adam. So I gave that a shot. It’s better! And it might get better still with more epochs:


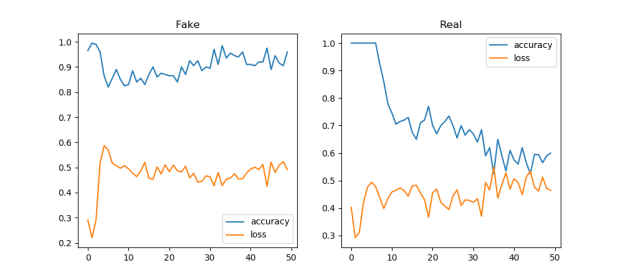
- That is a little better! We’ll keep that:


- Created a OneDGAN2b to continue
- Got all the code running. Here’s my first attempt. It’s sloooooow, too

- With an RMSProp optimizer of 0.0001 it seems to be better.
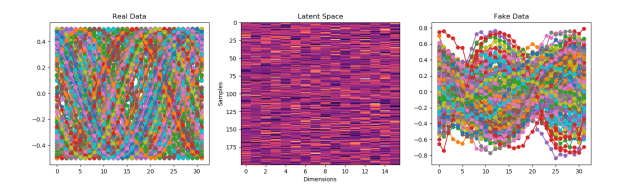
- I’m going to try a 20,000 epoch run next. A little better? Maybe


- Here’s a 50k run. It’s really no better, but now there’s a mechanism to explore more than one layer of detector neurons? I also like to see that the pattern really stabilizes around 8,000 epochs
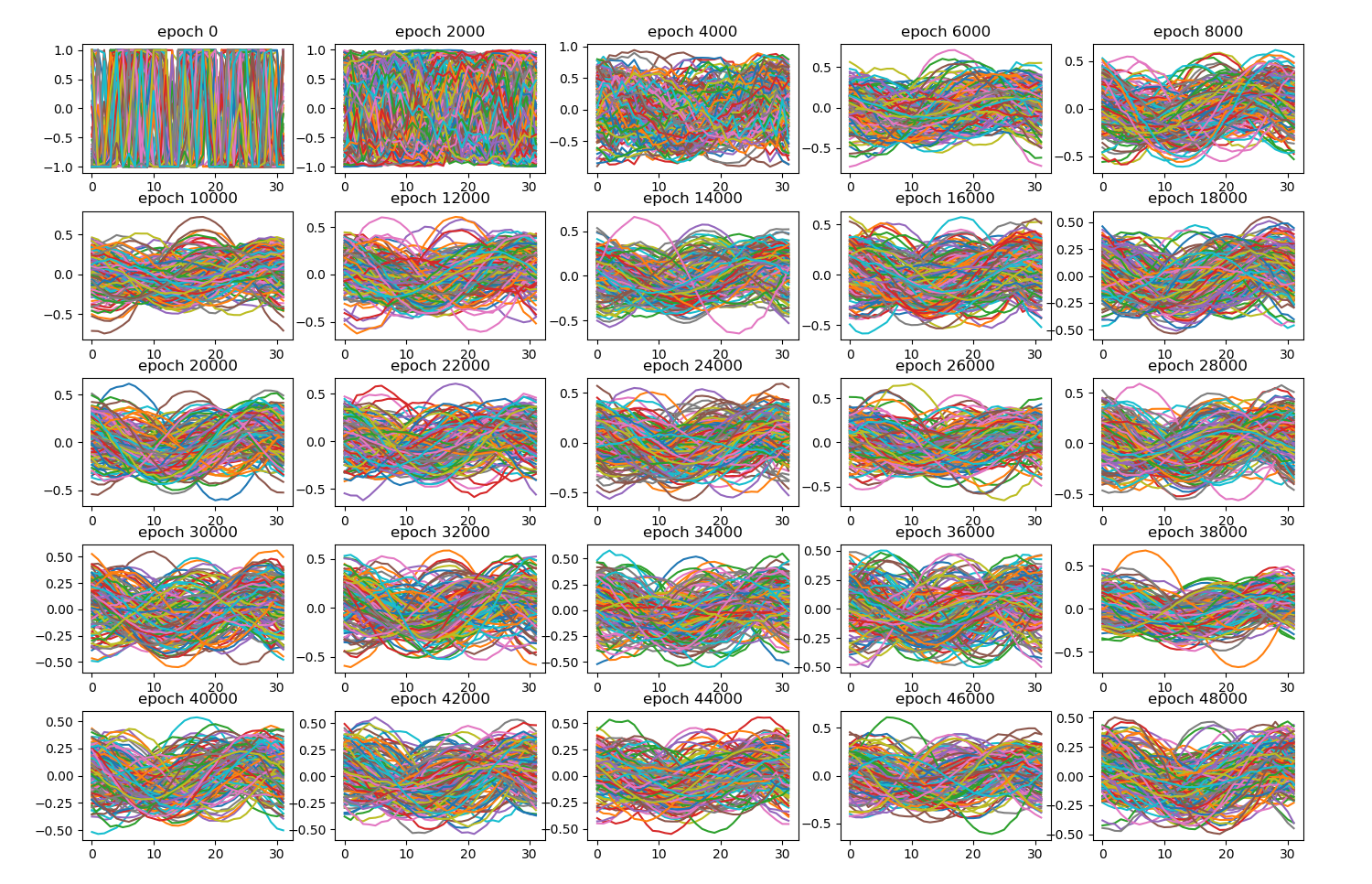

- I think the next thing I want to try is the n-critic approach to the OneGAN2a approach
